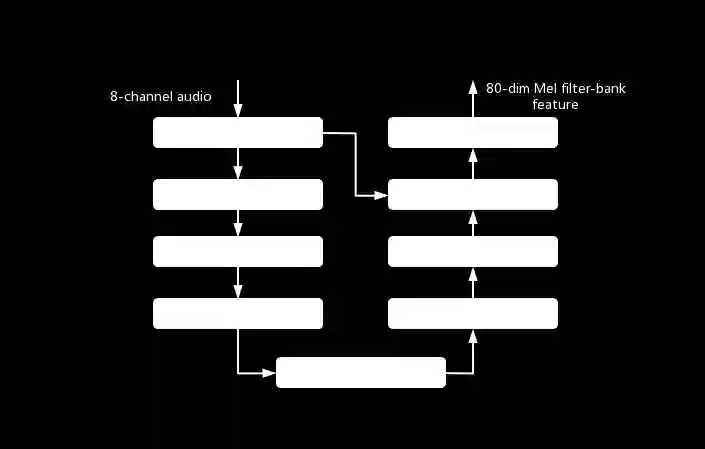
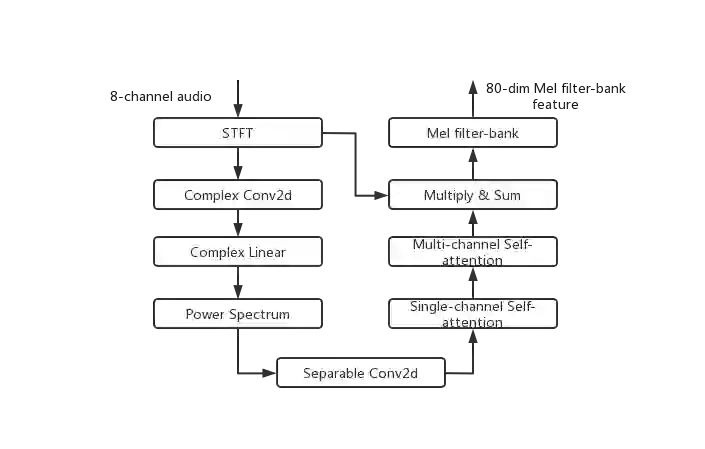
This paper describes our submission to ICASSP 2022 Multi-channel Multi-party Meeting Transcription (M2MeT) Challenge. For Track 1, we propose several approaches to empower the clustering-based speaker diarization system to handle overlapped speech. Front-end dereverberation and the direction-of-arrival (DOA) estimation are used to improve the accuracy of speaker diarization. Multi-channel combination and overlap detection are applied to reduce the missed speaker error. A modified DOVER-Lap is also proposed to fuse the results of different systems. We achieve the final DER of 5.79% on the Eval set and 7.23% on the Test set. For Track 2, we develop our system using the Conformer model in a joint CTC-attention architecture. Serialized output training is adopted to multi-speaker overlapped speech recognition. We propose a neural front-end module to model multi-channel audio and train the model end-to-end. Various data augmentation methods are utilized to mitigate over-fitting in the multi-channel multi-speaker E2E system. Transformer language model fusion is developed to achieve better performance. The final CER is 19.2% on the Eval set and 20.8% on the Test set.
翻译:本文描述我们提交 ICASSP 2022 多通道多党会议分解( M2Met) 挑战 。 对于第1轨,我们提出几种方法,授权基于组群的扩音器分解系统处理重叠的语音。 前端偏差和抵达方向(DOA)估算用于提高音频分解的准确性。多通道组合和重叠检测用于减少错开的扬声器错误。还提出修改DOVER-Lap 以整合不同系统的结果。我们实现了Eval集5.79%和测试集7.23%的最后DER。关于第2轨,我们利用CCT-注意联合结构中的Conecter模式开发了我们的系统。采用定序输出培训用于多声器重叠语音识别。我们提议了一个神经前端模块,用于模拟多频道音频带音响,并培训模式端对端到端。我们采用了各种数据增强方法,以缓解多频道多频段E2E2E2E2E系统中的超配度。 对于第2轨,我们开发了我们的系统,我们使用Contreferal 模型。 和EVLismal 20Rever 套的功能。