【论文推荐】最新五篇命名实体识别相关论文—深度主动学习、Lattice LSTM、混合马尔可夫CRF
【导读】专知内容组既昨天推出六篇命名实体识别(Named Entity Recognition)相关文章,今天又整理了最近五篇命名实体识别相关文章,为大家进行介绍,欢迎查看!
7.Deep Active Learning for Named Entity Recognition(基于深度主动学习的命名实体识别)
作者:Yanyao Shen,Hyokun Yun,Zachary C. Lipton,Yakov Kronrod,Animashree Anandkumar
摘要:Deep learning has yielded state-of-the-art performance on many natural language processing tasks including named entity recognition (NER). However, this typically requires large amounts of labeled data. In this work, we demonstrate that the amount of labeled training data can be drastically reduced when deep learning is combined with active learning. While active learning is sample-efficient, it can be computationally expensive since it requires iterative retraining. To speed this up, we introduce a lightweight architecture for NER, viz., the CNN-CNN-LSTM model consisting of convolutional character and word encoders and a long short term memory (LSTM) tag decoder. The model achieves nearly state-of-the-art performance on standard datasets for the task while being computationally much more efficient than best performing models. We carry out incremental active learning, during the training process, and are able to nearly match state-of-the-art performance with just 25\% of the original training data.

期刊:arXiv, 2018年2月4日
网址:
http://www.zhuanzhi.ai/document/34a32cbd6e8951face20444d74932cda
8.Chinese NER Using Lattice LSTM(基于Lattice LSTM的中文命名实体识别)
作者:Yue Zhang,Jie Yang
Accepted at ACL 2018 as Long paper
机构:Singapore University of Technology and Design
摘要:We investigate a lattice-structured LSTM model for Chinese NER, which encodes a sequence of input characters as well as all potential words that match a lexicon. Compared with character-based methods, our model explicitly leverages word and word sequence information. Compared with word-based methods, lattice LSTM does not suffer from segmentation errors. Gated recurrent cells allow our model to choose the most relevant characters and words from a sentence for better NER results. Experiments on various datasets show that lattice LSTM outperforms both word-based and character-based LSTM baselines, achieving the best results.

期刊:arXiv, 2018年5月15日
网址:
http://www.zhuanzhi.ai/document/90c97ae2371e75029f1b5bf151a7badb
9.Hybrid semi-Markov CRF for Neural Sequence Labeling(用于神经序列标记的混合马尔可夫CRF)
作者:Zhi-Xiu Ye,Zhen-Hua Ling
This paper has been accepted by ACL 2018
机构:University of Science and Technology of China
摘要:This paper proposes hybrid semi-Markov conditional random fields (SCRFs) for neural sequence labeling in natural language processing. Based on conventional conditional random fields (CRFs), SCRFs have been designed for the tasks of assigning labels to segments by extracting features from and describing transitions between segments instead of words. In this paper, we improve the existing SCRF methods by employing word-level and segment-level information simultaneously. First, word-level labels are utilized to derive the segment scores in SCRFs. Second, a CRF output layer and an SCRF output layer are integrated into an unified neural network and trained jointly. Experimental results on CoNLL 2003 named entity recognition (NER) shared task show that our model achieves state-of-the-art performance when no external knowledge is used.
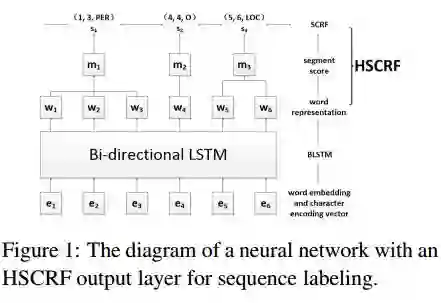
期刊:arXiv, 2018年5月10日
网址:
http://www.zhuanzhi.ai/document/541eb79c19f4294f26824278c2e9984c
10.SlugNERDS: A Named Entity Recognition Tool for Open Domain Dialogue Systems(SlugNERDS: 开放域对话系统的命名实体识别工具)
作者:Kevin K. Bowden,Jiaqi Wu,Shereen Oraby,Amita Misra,Marilyn Walker
机构:University of California
摘要:In dialogue systems, the tasks of named entity recognition (NER) and named entity linking (NEL) are vital preprocessing steps for understanding user intent, especially in open domain interaction where we cannot rely on domain-specific inference. UCSC's effort as one of the funded teams in the 2017 Amazon Alexa Prize Contest has yielded Slugbot, an open domain social bot, aimed at casual conversation. We discovered several challenges specifically associated with both NER and NEL when building Slugbot, such as that the NE labels are too coarse-grained or the entity types are not linked to a useful ontology. Moreover, we have discovered that traditional approaches do not perform well in our context: even systems designed to operate on tweets or other social media data do not work well in dialogue systems. In this paper, we introduce Slugbot's Named Entity Recognition for dialogue Systems (SlugNERDS), a NER and NEL tool which is optimized to address these issues. We describe two new resources that we are building as part of this work: SlugEntityDB and SchemaActuator. We believe these resources will be useful for the research community.

期刊:arXiv, 2018年5月10日
网址:
http://www.zhuanzhi.ai/document/448c34888e109fd96ef630a1ac72d106
11.A Tidy Data Model for Natural Language Processing using cleanNLP(使用cleanNLP进行自然语言处理的清理数据模型)
作者:Taylor Arnold
摘要:The package cleanNLP provides a set of fast tools for converting a textual corpus into a set of normalized tables. The underlying natural language processing pipeline utilizes Stanford's CoreNLP library, exposing a number of annotation tasks for text written in English, French, German, and Spanish. Annotators include tokenization, part of speech tagging, named entity recognition, entity linking, sentiment analysis, dependency parsing, coreference resolution, and information extraction.
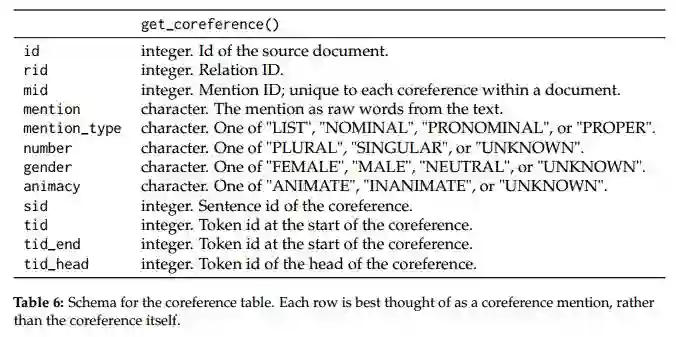
期刊:arXiv, 2018年5月4日
网址:
http://www.zhuanzhi.ai/document/1d8bac3ec0605c327726546d570eac19
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

[点击上面图片加入会员]
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知


