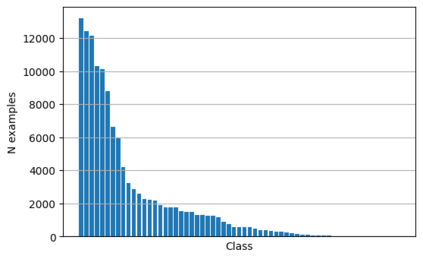
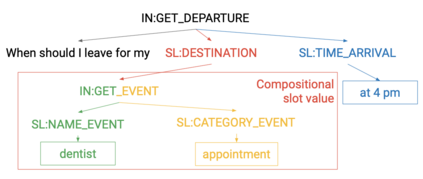
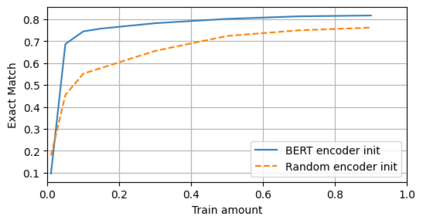
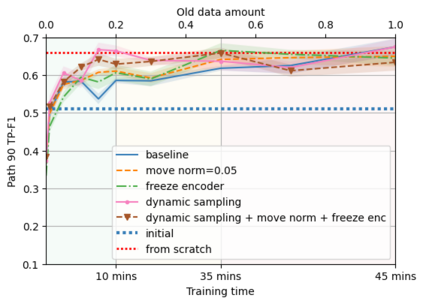
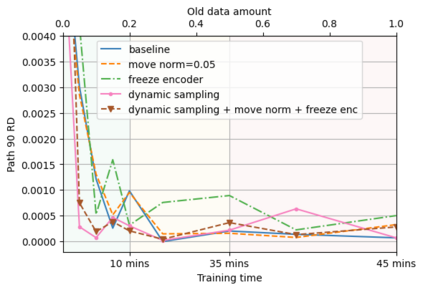
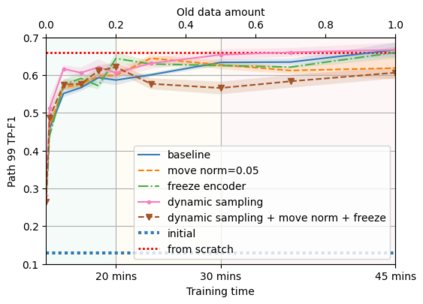
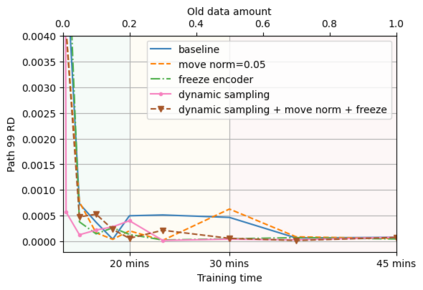
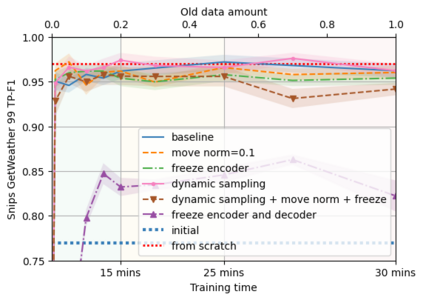
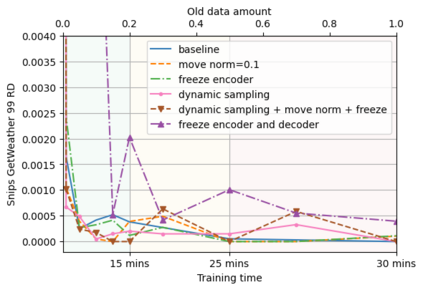
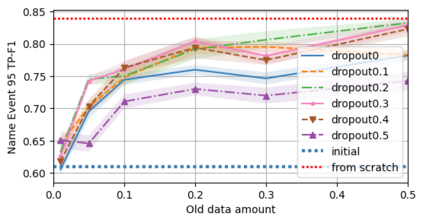
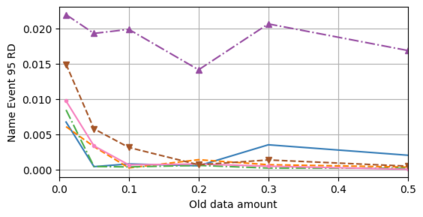
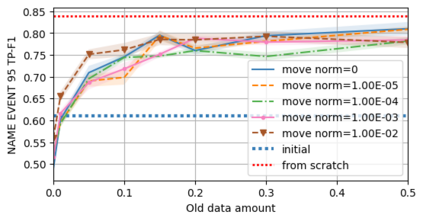
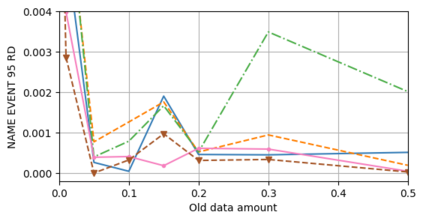
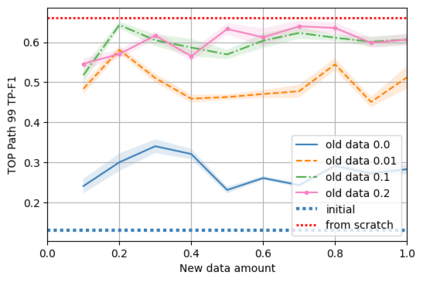
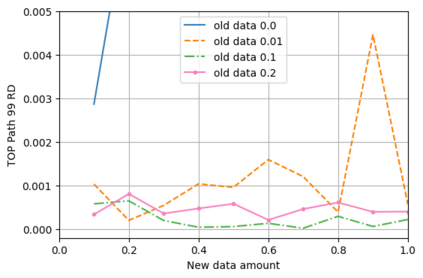
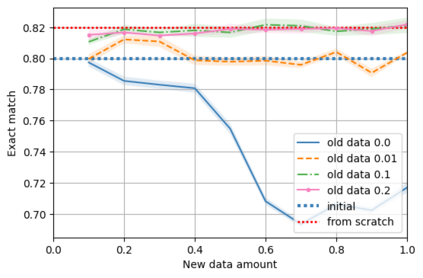
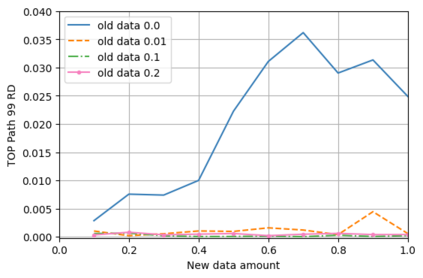
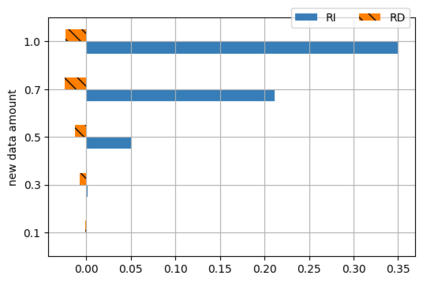
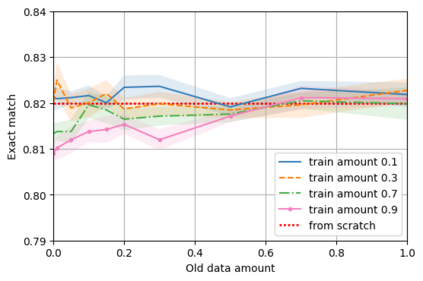
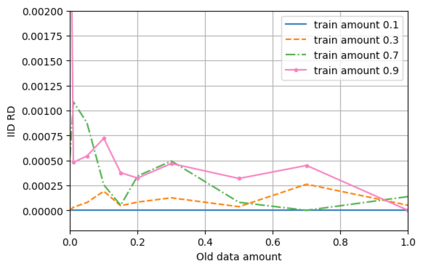
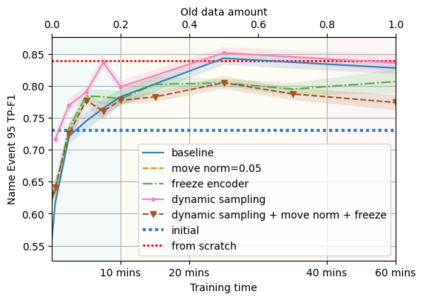
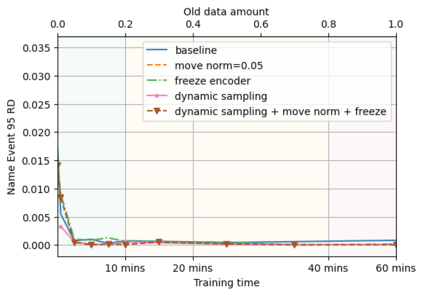
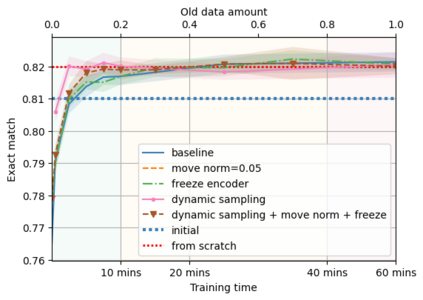
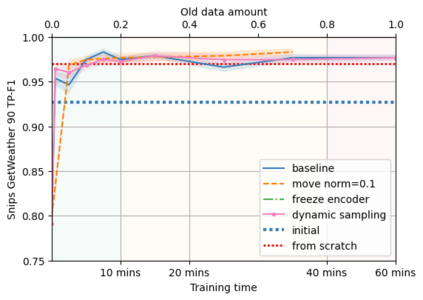
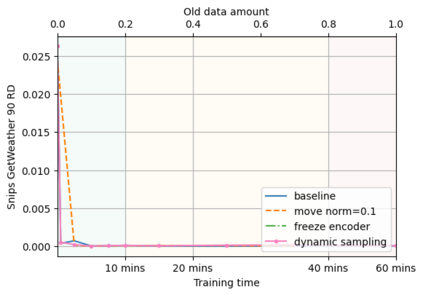
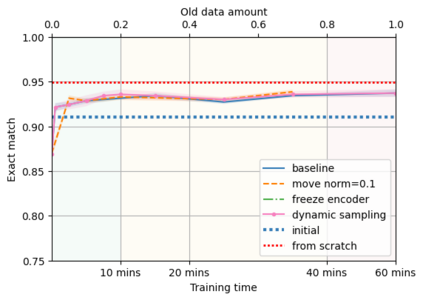
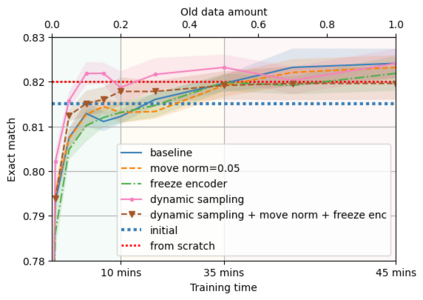
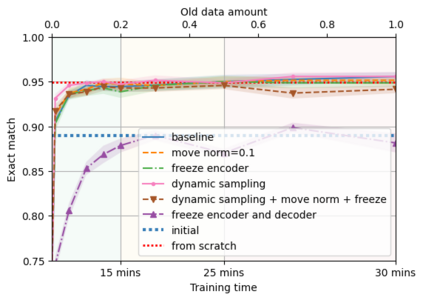
A semantic parsing model is crucial to natural language processing applications such as goal-oriented dialogue systems. Such models can have hundreds of classes with a highly non-uniform distribution. In this work, we show how to efficiently (in terms of computational budget) improve model performance given a new portion of labeled data for a specific low-resource class or a set of classes. We demonstrate that a simple approach with a specific fine-tuning procedure for the old model can reduce the computational costs by ~90% compared to the training of a new model. The resulting performance is on-par with a model trained from scratch on a full dataset. We showcase the efficacy of our approach on two popular semantic parsing datasets, Facebook TOP, and SNIPS.
翻译:语义分解模型对于自然语言处理应用程序(如面向目标的对话系统)至关重要。 这种模型可以拥有数百个高度非统一分布的班级。 在这项工作中,我们展示了如何(在计算预算方面)高效率地提高模型性能,因为特定低资源类或一组类的标签数据有了新的部分。 我们展示了对旧模型采用特定微调程序的简单方法,可以比对新模型的培训减少计算成本~90%。 由此产生的性能与在全数据集上从零开始培训的模型是平行的。 我们展示了我们对两个流行的语义解解析数据集( Facebook TOP 和 SNIPS) 的实用性。