春节充电系列:李宏毅2017机器学习课程学习笔记19之迁移学习(Transfer Learning)
【导读】我们在上一节的内容中已经为大家介绍了台大李宏毅老师的机器学习课程的deep generative model (part 2),这一节将主要针对讨论transfer learning。本文讨论机器学习中transfer learning的若干主要问题:model fine-tuning, multitask learning, domain-adversarial training 以及 zero-shot learning。话不多说,让我们一起学习这些内容吧。
春节充电系列:李宏毅2017机器学习课程学习笔记02之Regression
春节充电系列:李宏毅2017机器学习课程学习笔记03之梯度下降
春节充电系列:李宏毅2017机器学习课程学习笔记04分类(Classification)
春节充电系列:李宏毅2017机器学习课程学习笔记05之Logistic 回归
春节充电系列:李宏毅2017机器学习课程学习笔记06之深度学习入门
春节充电系列:李宏毅2017机器学习课程学习笔记07之反向传播(Back Propagation)
春节充电系列:李宏毅2017机器学习课程学习笔记08之“Hello World” of Deep Learning
春节充电系列:李宏毅2017机器学习课程学习笔记09之Tip for training DNN
春节充电系列:李宏毅2017机器学习课程学习笔记10之卷积神经网络
春节充电系列:李宏毅2017机器学习课程学习笔记11之Why Deep Learning?
春节充电系列:李宏毅2017机器学习课程学习笔记12之半监督学习(Semi-supervised Learning)
春节充电系列:李宏毅2017机器学习课程学习笔记13之无监督学习:主成分分析(PCA)
春节充电系列:李宏毅2017机器学习课程学习笔记14之无监督学习:词嵌入表示(Word Embedding)
春节充电系列:李宏毅2017机器学习课程学习笔记15之无监督学习:Neighbor Embedding
春节充电系列:李宏毅2017机器学习课程学习笔记16之无监督学习:自编码器(autoencoder)
春节充电系列:李宏毅2017机器学习课程学习笔记17之深度生成模型:deep generative model part 1
春节充电系列:李宏毅2017机器学习课程学习笔记18之深度生成模型:deep generative model part 2
课件网址:
http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML17_2.html
http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML17.html
视频网址:
https://www.bilibili.com/video/av15889450/index_1.html
李宏毅机器学习笔记19 迁移学习(Transfer Learning)
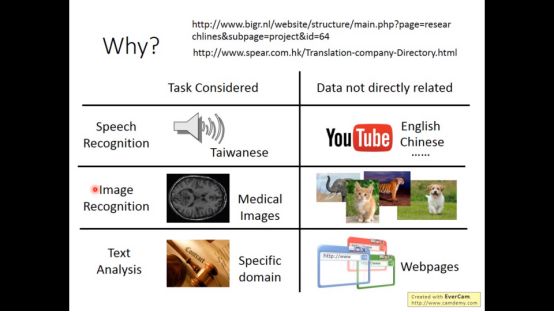
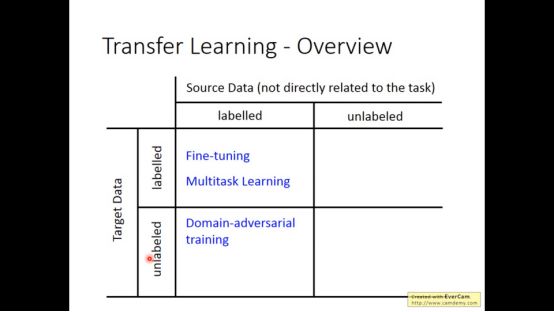
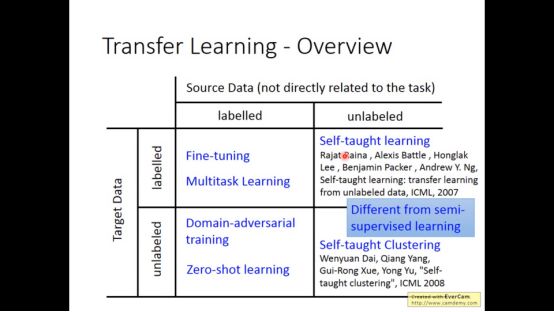
所谓transfer learning也叫迁移学习,是指有一些数据集它不是直接和任务相关联

因为在speech recognition,image recognition,text analysis等一系列应用都会有这样的数据集。
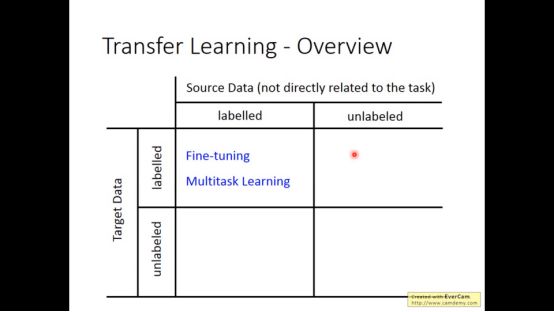
1.model fine-tuning
model fine-tuning指的是有labelled target data和labelled source data 的一种模型
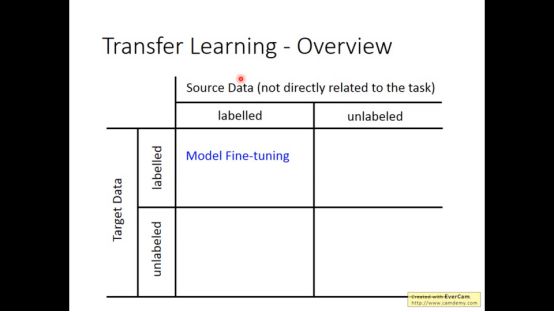
往往target data是非常少的,而source data很多

核心思想是用source data进行训练模型,然后用target data进行微调
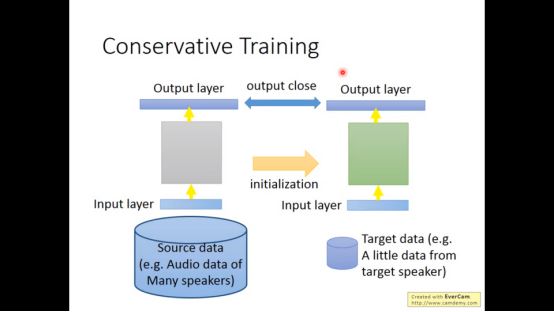
我们进行微调时必须特别谨慎避免overfitting
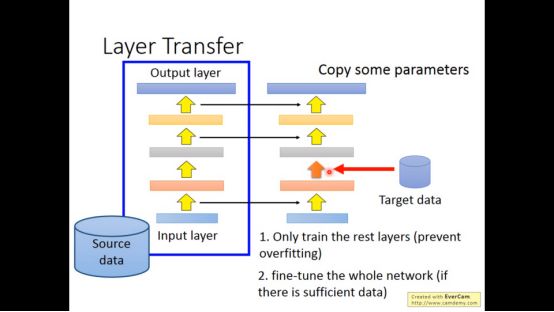
Layer的迁移是有规律的,比如对于语音信号我们最好复制最后面的几个layer,对于图像我们最好复制最前面的几个layer
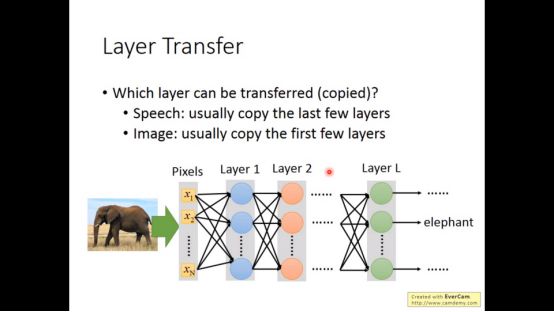
2. Multitask Learning
除了model fine-tuning以外还有种模型叫做Multitask Learning
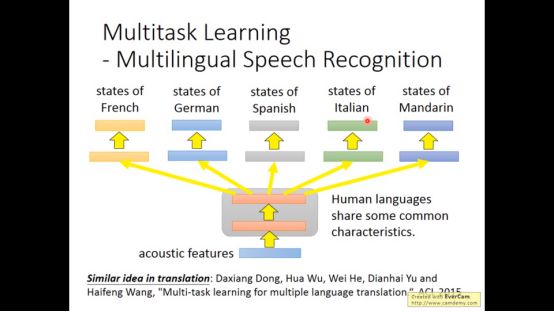
它的核心思想是让机器同时去学好好几个task
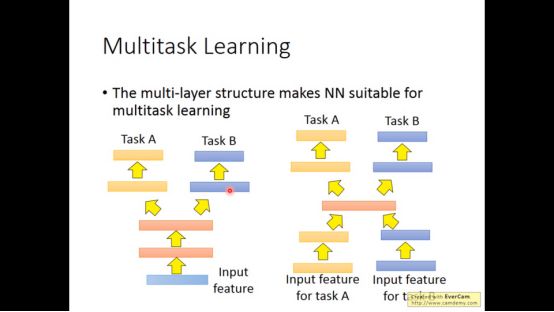
因为多个task一起train可能是彼此有帮助的
先学会A,再学会B。学会A是对学B有帮助的,但我们不希望学会B后忘记A
把A隐藏层的输出当做B隐藏层的一部分,比如A的隐藏层的输出当做B隐藏层的输入,反向传播时锁死A的参数,只调B。但这样参数会越来越多
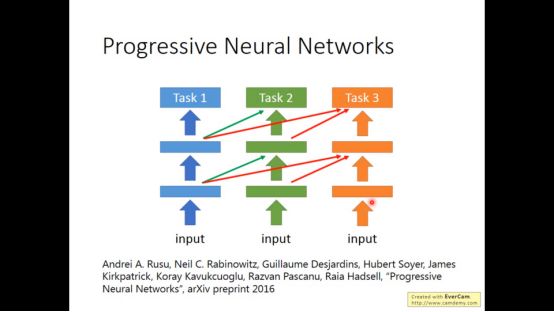
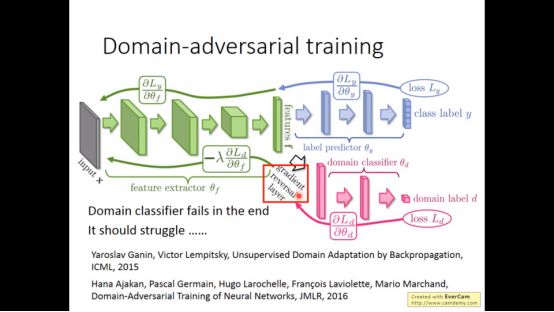
3. Domain-adversarial training
有unlabeled target data和labelled source data的模型叫做Domain-adversarial training
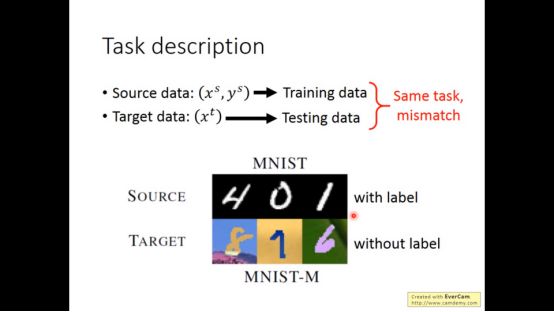
Source data和target data他们的任务一样,但是数据不匹配
所以我们要用一个模型使得target data和source data通过一个feature extractor后得到相似的特征。这个模型叫做Domain-adversarial training
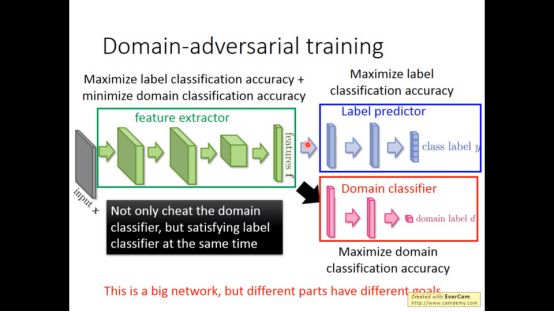
Domain有三个部分,feature extractor是为了从target data和source data得到相似的feature,label predictor能用feature得到正确的label,domain是为了将target data和source data分离开来。这个模型很像GAN。Feature extractor不仅要欺骗domain classifier还要满足label predictor
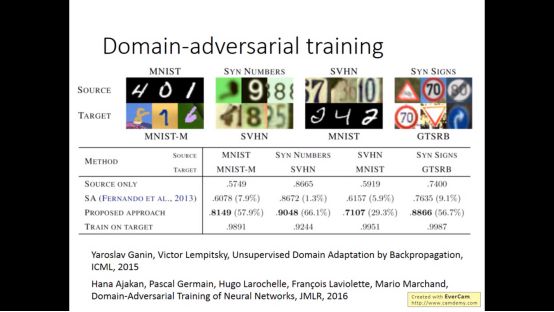
实验结果如下
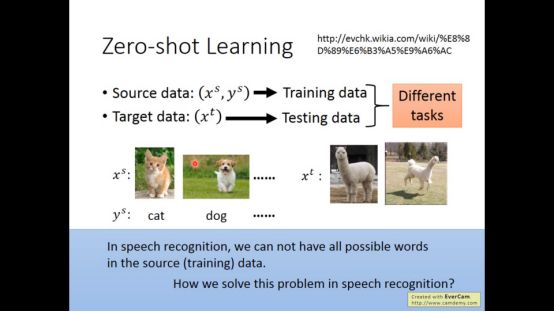
4. zero-shot learning
所谓zero-shot learning指的如何得到训练集以外的结果
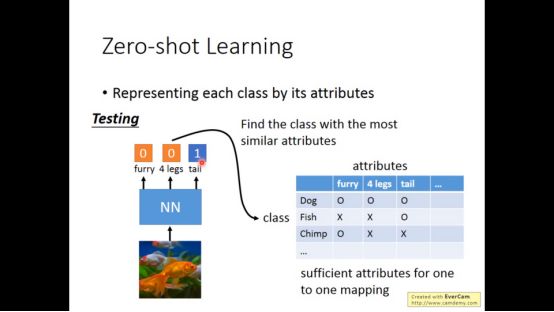
我们可以用其属性来进行训练

然后对于不在训练集的东西根据属性在database寻找对应的结果
另外的做法,把图像和attribute投影到同一个投影空间里面
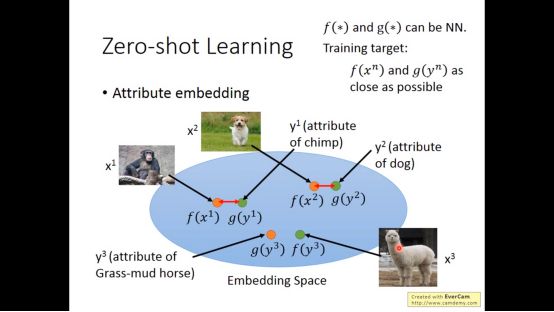
对应的数学表达式如下图所示。要求f和g越接近越好,当f和g全为0即可。但不能这样,所以要加上一个k

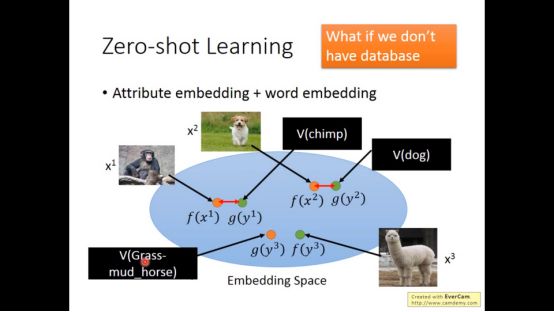
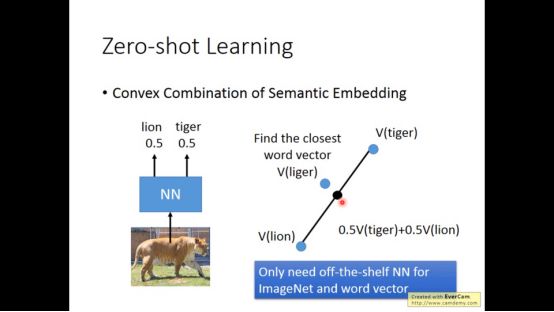
假设连attribute都没有呢,则可以用每一个动物对应的名字的word vector来代表它的attribute
比如狮虎兽可以这样来
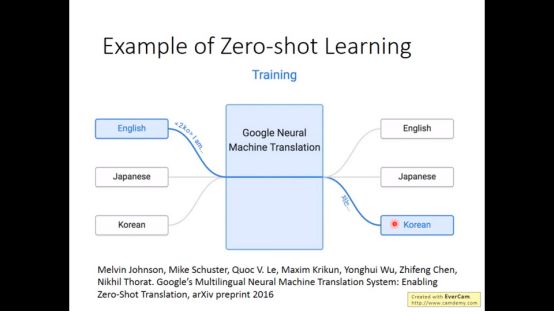
Zero-shot可以用在机器翻译中
还可以用在语义聚类中

还有两个模型叫做self-taught learning和self-taught Clustering。作者并没细讲(可能应用不太广泛)。想要详细了解的话可以看图中的论文。
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“LHY2017” 就可以获取 2017年李宏毅中文机器学习课程下载链接~
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!



