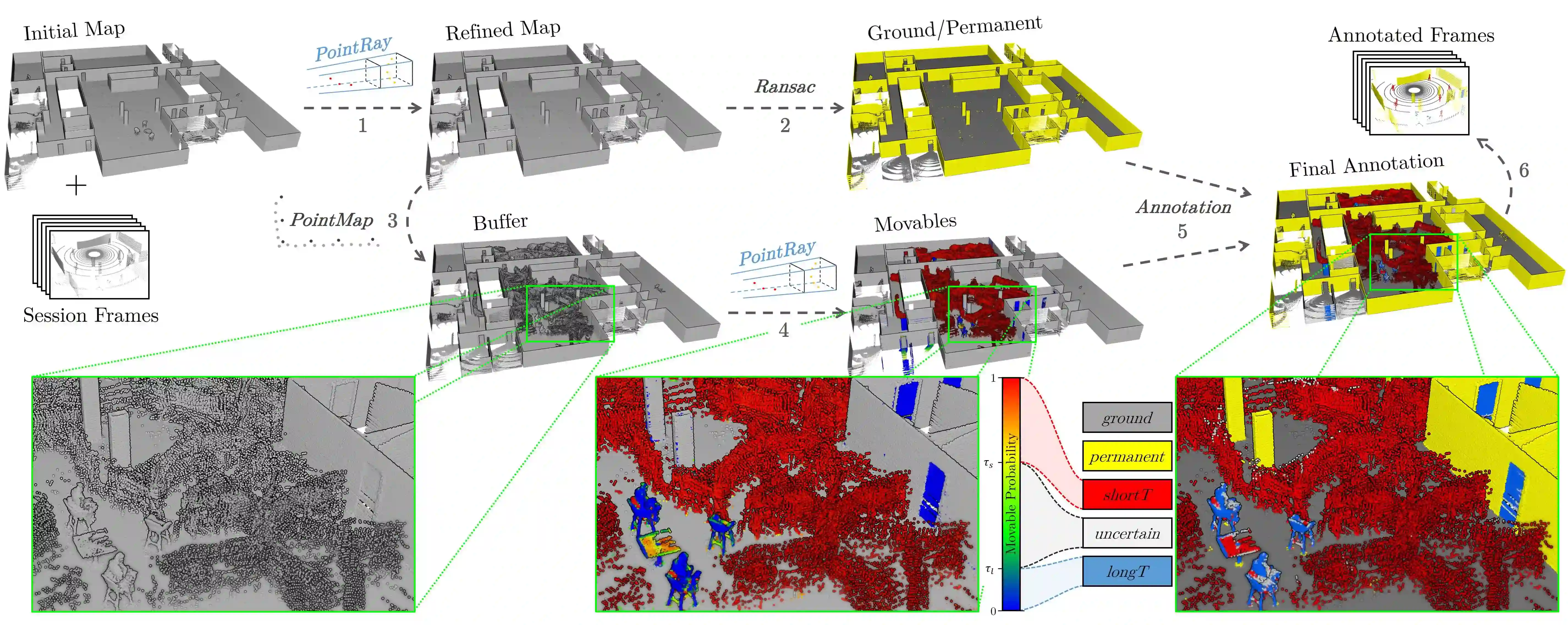
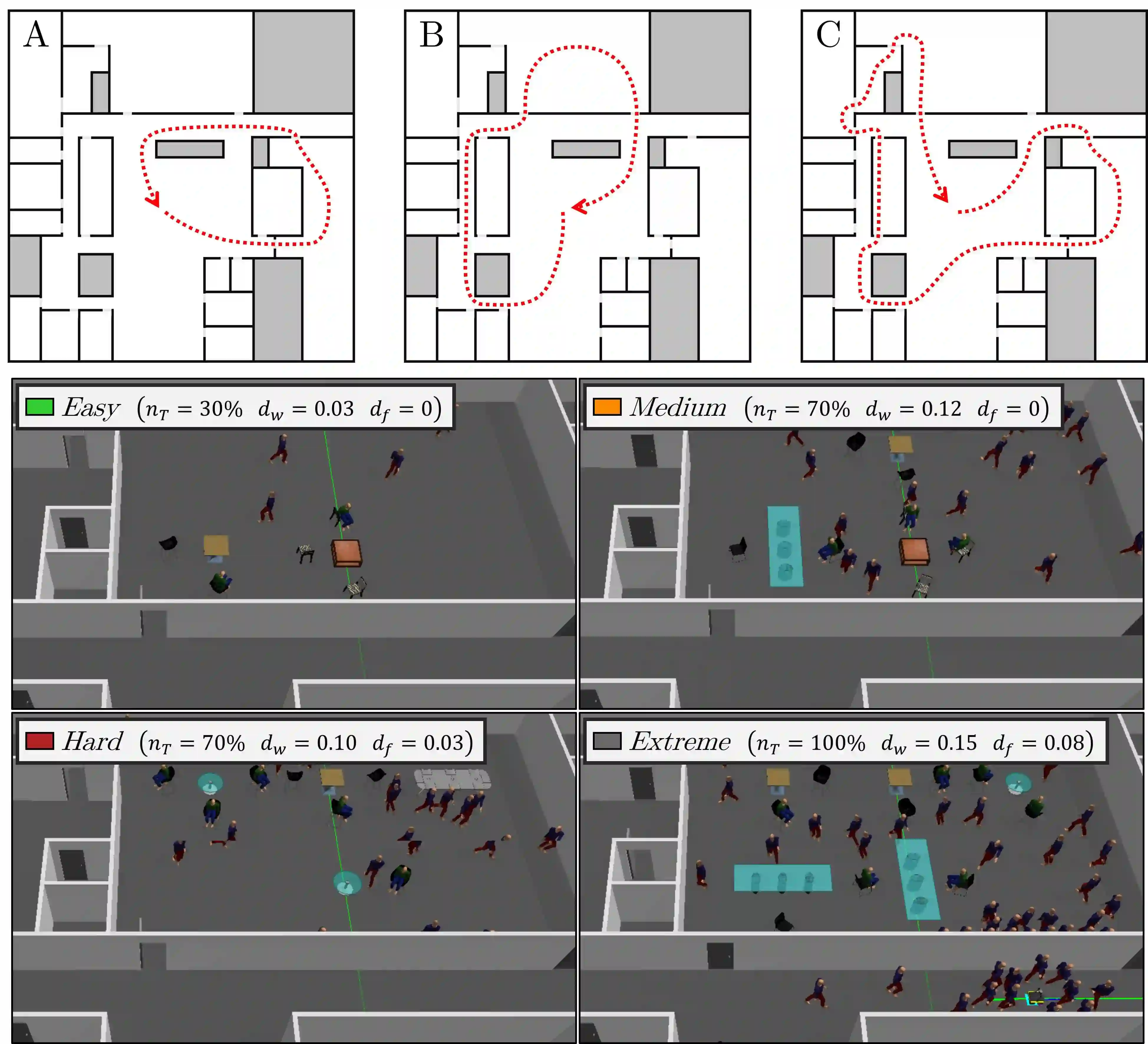
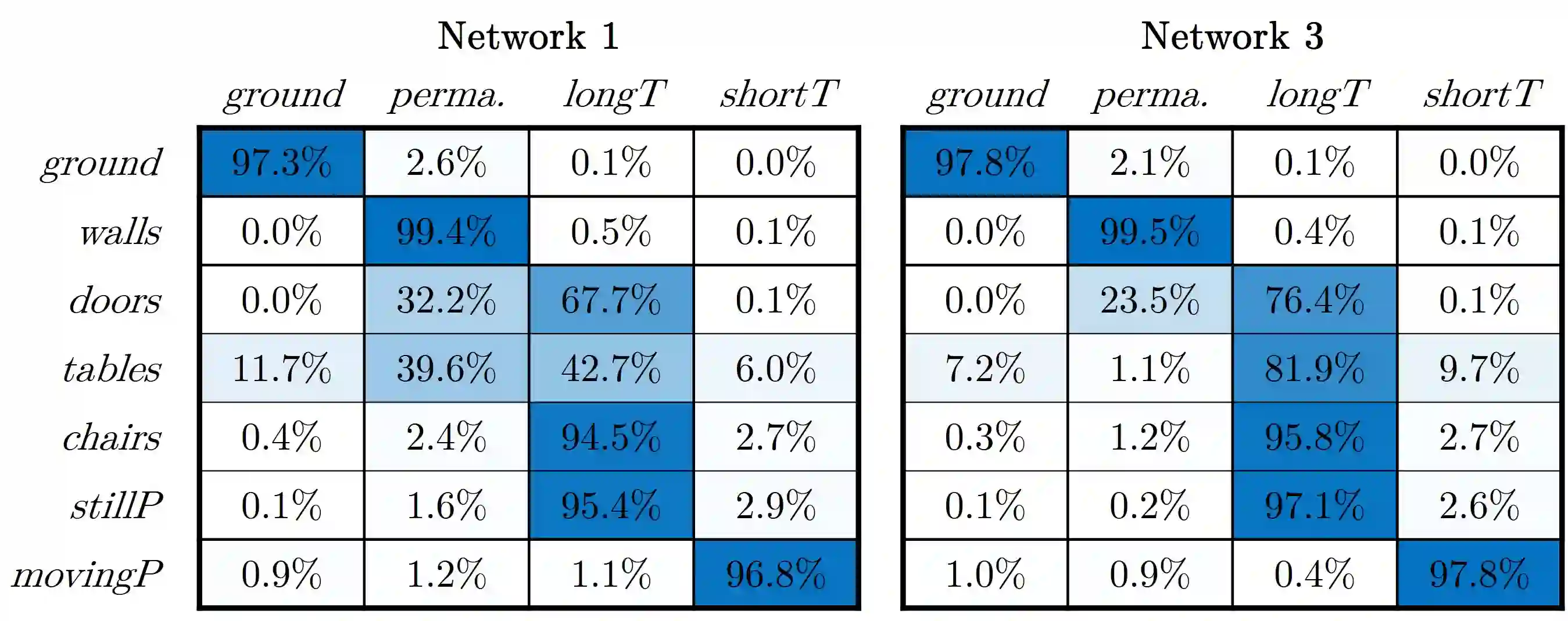
We present a self-supervised learning approach for the semantic segmentation of lidar frames. Our method is used to train a deep point cloud segmentation architecture without any human annotation. The annotation process is automated with the combination of simultaneous localization and mapping (SLAM) and ray-tracing algorithms. By performing multiple navigation sessions in the same environment, we are able to identify permanent structures, such as walls, and disentangle short-term and long-term movable objects, such as people and tables, respectively. New sessions can then be performed using a network trained to predict these semantic labels. We demonstrate the ability of our approach to improve itself over time, from one session to the next. With semantically filtered point clouds, our robot can navigate through more complex scenarios, which, when added to the training pool, help to improve our network predictions. We provide insights into our network predictions and show that our approach can also improve the performances of common localization techniques.
翻译:我们为lidar 框架的语义分解提供了一个自监督的学习方法。 我们的方法被用来在不做人类笔记的情况下训练一个深点云分解结构。 批注过程是自动化的, 结合同时的本地化和绘图( SLAM) 和射线追踪算法。 通过在同一环境中进行多次导航, 我们能够识别永久结构, 如墙壁, 以及分解短期和长期移动物体, 如人和表格。 然后, 新的会话可以使用经过训练的网络进行, 以预测这些语义标签。 我们展示了我们的方法在时间上从一个会话到下一个会话的改进自己的能力。 借助静态过滤的点云, 我们的机器人可以浏览更复杂的场景, 当添加到培训池, 帮助改进我们的网络预测。 我们提供网络预测的洞察, 并表明我们的方法也可以改进共同的本地化技术的性能 。