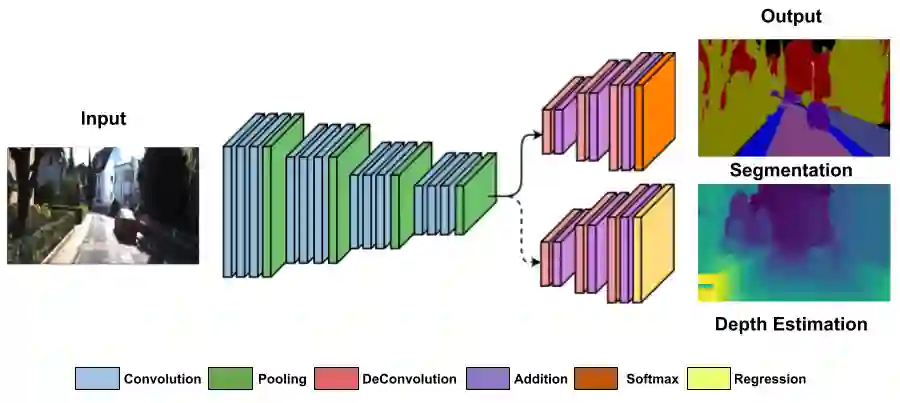
Decision making in automated driving is highly specific to the environment and thus semantic segmentation plays a key role in recognizing the objects in the environment around the car. Pixel level classification once considered a challenging task which is now becoming mature to be productized in a car. However, semantic annotation is time consuming and quite expensive. Synthetic datasets with domain adaptation techniques have been used to alleviate the lack of large annotated datasets. In this work, we explore an alternate approach of leveraging the annotations of other tasks to improve semantic segmentation. Recently, multi-task learning became a popular paradigm in automated driving which demonstrates joint learning of multiple tasks improves overall performance of each tasks. Motivated by this, we use auxiliary tasks like depth estimation to improve the performance of semantic segmentation task. We propose adaptive task loss weighting techniques to address scale issues in multi-task loss functions which become more crucial in auxiliary tasks. We experimented on automotive datasets including SYNTHIA and KITTI and obtained 3% and 5% improvement in accuracy respectively.
翻译:自动驾驶的决策对于环境非常特殊,因此,语义分解在识别汽车周围环境中的物体方面起着关键作用。像素级分类曾一度认为是一项挑战性的任务,现已成熟,可在汽车中产生。然而,语义解说费时费力,费用也相当高。使用域适应技术的合成数据集来缓解缺乏大量附加说明的数据集的问题。在这项工作中,我们探索了另一种办法,即利用其他任务的说明来改进语义分解。最近,多任务学习在自动化驾驶中成为流行模式,表明对多项任务的共同学习提高了每项任务的总体绩效。受此驱动,我们利用深度估算等辅助任务来改进语义分解任务的性能。我们提出了适应性任务减重估技术,以解决多任务损失功能中的规模问题,这些功能在辅助任务中变得更加关键。我们实验了包括SYNTHIA和KITTI在内的汽车数据集,并分别提高了3%和5%的准确性。