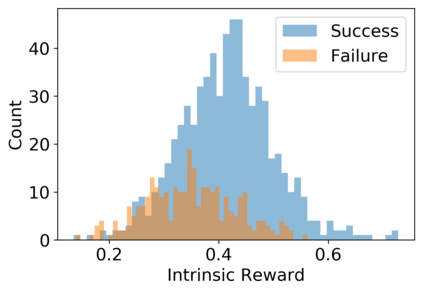
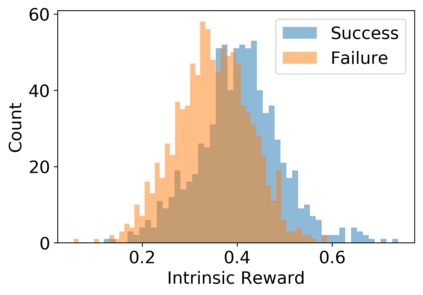
Vision-language navigation (VLN) is the task of navigating an embodied agent to carry out natural language instructions inside real 3D environments. In this paper, we study how to address three critical challenges for this task: the cross-modal grounding, the ill-posed feedback, and the generalization problems. First, we propose a novel Reinforced Cross-Modal Matching (RCM) approach that enforces cross-modal grounding both locally and globally via reinforcement learning (RL). Particularly, a matching critic is used to provide an intrinsic reward to encourage global matching between instructions and trajectories, and a reasoning navigator is employed to perform cross-modal grounding in the local visual scene. Evaluation on a VLN benchmark dataset shows that our RCM model significantly outperforms existing methods by 10% on SPL and achieves the new state-of-the-art performance. To improve the generalizability of the learned policy, we further introduce a Self-Supervised Imitation Learning (SIL) method to explore unseen environments by imitating its own past, good decisions. We demonstrate that SIL can approximate a better and more efficient policy, which tremendously minimizes the success rate performance gap between seen and unseen environments (from 30.7% to 11.7%).
翻译:视觉语言导航(VLN)是引导一个具有内涵的代理人在真实的 3D 环境中执行自然语言指令的任务。 在本文中,我们研究如何应对这一任务的三个关键挑战:跨模式地面、错误的反馈和一般化问题。首先,我们提出一个新的加强跨模式匹配(RCM)方法,通过强化学习(RL)在当地和全球实施跨模式地面。特别是,一个匹配的批评家被用来提供内在的奖励,鼓励在指令和轨迹之间进行全球匹配,并使用一个推理导航员在当地视觉场进行跨模式地面定位。对VLN基准数据集的评价表明,我们的RCM模型大大超越了现有方法10%的SPL,并实现了新的状态性能。为了提高学习政策的普遍性,我们进一步引入了一种自我超模的模拟学习(SIL)方法,通过模仿其自身的过去、良好的决定来探索隐蔽环境。我们证明,SLMMM模式在11 中可以更好地看到从最短的成绩到更短的30 % 环境之间。