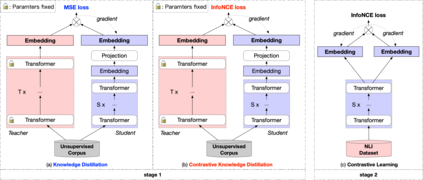
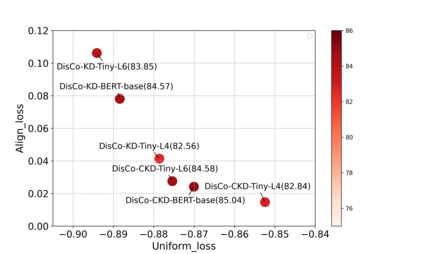
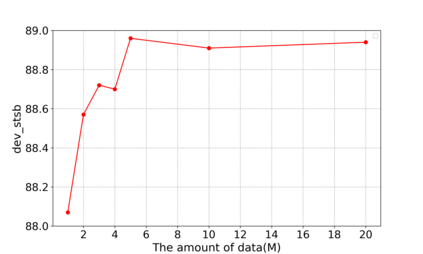
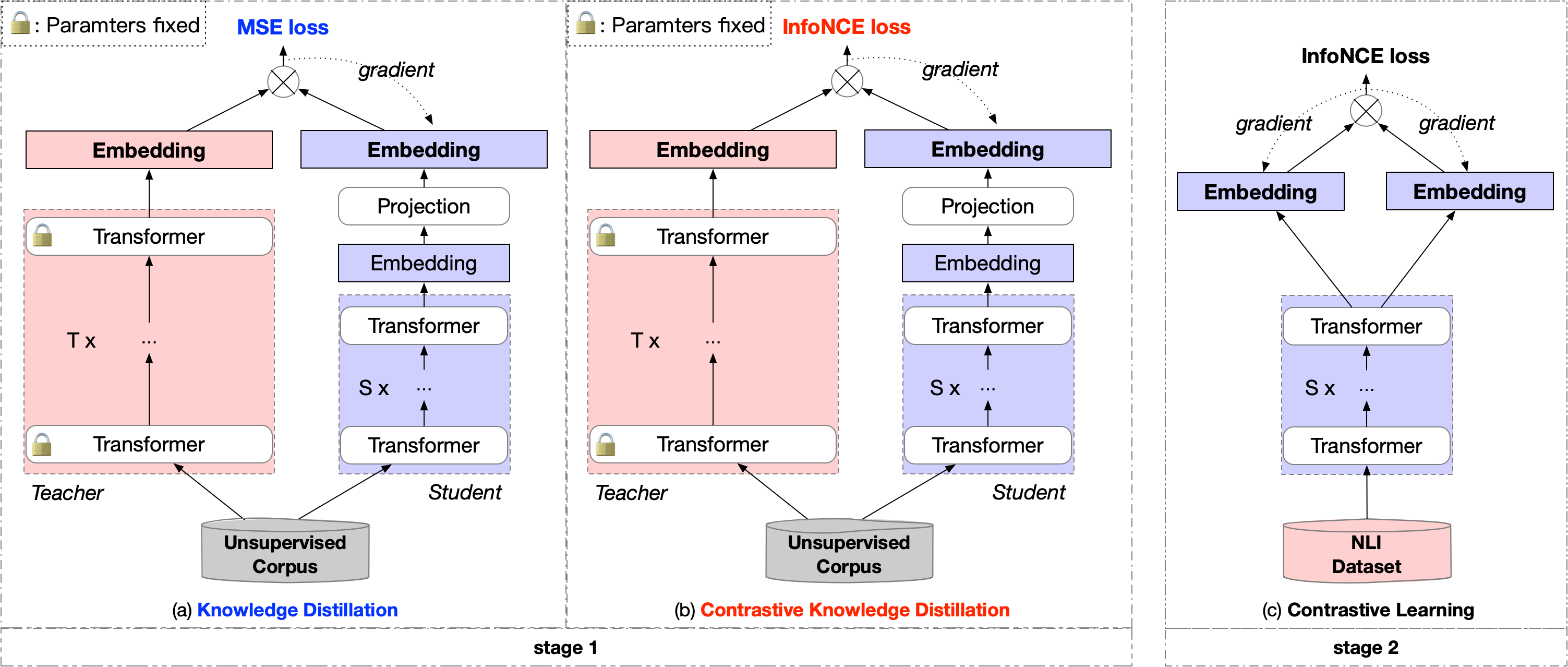
Contrastive learning has been proven suitable for learning sentence embeddings and can significantly improve the semantic textual similarity (STS) tasks. Recently, large contrastive learning models, e.g., Sentence-T5, tend to be proposed to learn more powerful sentence embeddings. Though effective, such large models are hard to serve online due to computational resources or time cost limits. To tackle that, knowledge distillation (KD) is commonly adopted, which can compress a large "teacher" model into a small "student" model but generally suffer from some performance loss. Here we propose an enhanced KD framework termed Distill-Contrast (DisCo). The proposed DisCo framework firstly utilizes KD to transfer the capability of a large sentence embedding model to a small student model on large unlabelled data, and then finetunes the student model with contrastive learning on labelled training data. For the KD process in DisCo, we further propose Contrastive Knowledge Distillation (CKD) to enhance the consistencies among teacher model training, KD, and student model finetuning, which can probably improve performance like prompt learning. Extensive experiments on 7 STS benchmarks show that student models trained with the proposed DisCo and CKD suffer from little or even no performance loss and consistently outperform the corresponding counterparts of the same parameter size. Amazingly, our 110M student model can even outperform the latest state-of-the-art (SOTA) model, i.e., Sentence-T5(11B), with only 1% parameters.
翻译:实践证明, 反向学习已被证明适合于学习句子嵌入, 并且可以大大改进语义文本相似( STS) 的任务。 最近, 大型对比学习模式, 例如, 句子- T5, 通常会建议学习更强大的句子嵌入。 虽然如此大的模型有效, 但由于计算资源或时间成本的限制, 很难在线使用。 要解决这个问题, 通常会采用知识蒸馏( KD) 模式, 它可以将一个大型的“ 教师” 模式压缩成一个小“ 学生” 模式, 但通常会受到一些性能损失。 我们在这里提议了一个强化的 KD 框架, 称为 蒸馏- Contrast ( Disco) 。 拟议的 Disco 框架首先利用 KD 将一个大句子嵌入模块的能力转换成一个大型无标签数据的学生模型, 然后对学生模式进行微量的微量的学习。 对于 Disco 模式, 我们进一步提议( CKDD) 的对比性能加强师范培训、 KD- 甚至是学生模型的校验的校验大小。