【MIT-伯克利-ICLR2020】对比表示蒸馏,Contrastive Representation Distillation

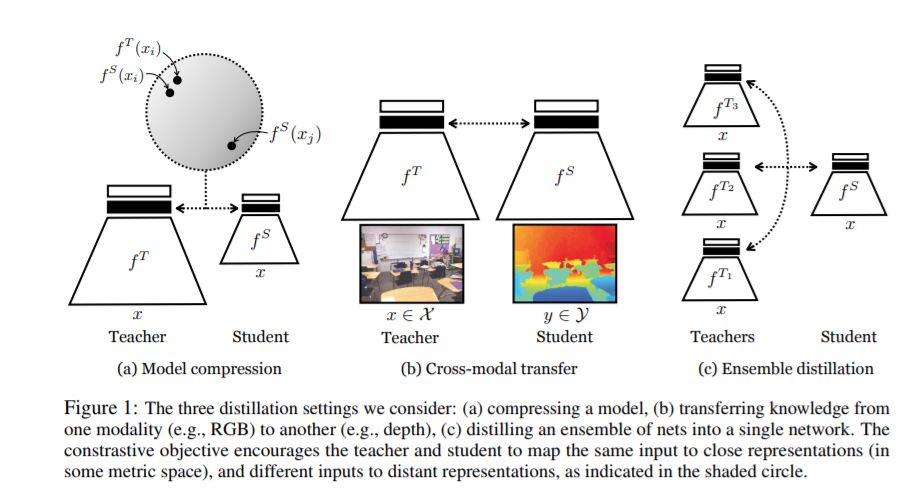
我们常常希望将表征性知识从一个神经网络转移到另一个神经网络。例如,将一个大的网络提炼成一个较小的网络,将知识从一种感觉模态传递到另一种感觉模态,或者将一组模型集成到一个单独的估计器中。知识蒸馏是解决这些问题的标准方法,它最小化了教师和学生网络的概率输出之间的KL分歧。我们证明这一目标忽视了教师网络的重要结构知识。这激发了另一个目标,通过这个目标,我们训练学生从老师对数据的描述中获取更多的信息。我们把这个目标称为对比学习。实验表明,我们得到的新目标在各种知识转移任务(包括单模型压缩、集成蒸馏和跨模态转移)上的性能优于知识蒸馏和其他前沿蒸馏器。我们的方法在许多转移任务中设置了一个新的水平,有时甚至超过教师网络与知识蒸馏相结合。
https://arxiv.org/abs/1910.10699
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“CRD” 就可以获取《【MIT-伯克利-ICLR2020】对比表示蒸馏,Contrastive Representation Distillation》论文专知下载链接



登录查看更多
相关内容

专知会员服务
78+阅读 · 2020年5月31日
专知会员服务
36+阅读 · 2020年4月14日
Arxiv
12+阅读 · 2019年9月26日

相关VIP内容
专知会员服务
78+阅读 · 2020年5月31日
专知会员服务
36+阅读 · 2020年4月14日
相关资讯
相关论文
Arxiv
12+阅读 · 2019年9月26日