
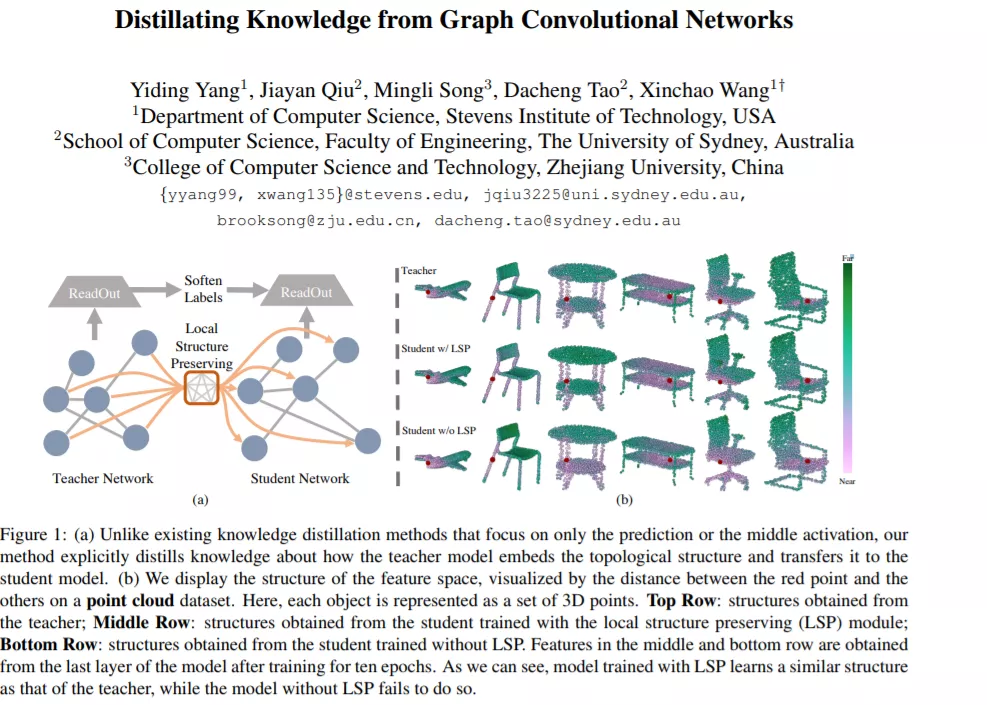
现有的知识蒸馏方法主要集中在卷积神经网络(convolutional neural networks~, CNNs)上,其中图像等输入样本位于一个网格域内,而处理非网格数据的graph convolutional networks~(GCN)则在很大程度上被忽略。在这篇论文中,我们提出从一个预先训练好的GCN模型中蒸馏知识的第一个专门方法。为了实现知识从教师到学生的迁移,我们提出了一个局部结构保留模块,该模块明确地考虑了教师的拓扑语义。在这个模块中,来自教师和学生的局部结构信息被提取为分布,因此最小化这些分布之间的距离,使得来自教师的拓扑感知的知识转移成为可能,从而产生一个紧凑但高性能的学生模型。此外,所提出的方法很容易扩展到动态图模型,其中教师和学生的输入图可能不同。我们使用不同架构的GCN模型,在两个不同的数据集上对所提出的方法进行了评估,并证明我们的方法达到了GCN模型最先进的知识蒸馏性能。
成为VIP会员查看完整内容
相关内容
专知会员服务
66+阅读 · 2020年4月17日
专知会员服务
78+阅读 · 2020年3月1日
专知会员服务
76+阅读 · 2020年1月16日
专知会员服务
116+阅读 · 2019年12月30日
专知会员服务
102+阅读 · 2019年11月24日
相关VIP内容
专知会员服务
66+阅读 · 2020年4月17日
专知会员服务
78+阅读 · 2020年3月1日
专知会员服务
76+阅读 · 2020年1月16日
专知会员服务
116+阅读 · 2019年12月30日
专知会员服务
102+阅读 · 2019年11月24日
相关资讯
相关论文