
题目: Large Batch Optimization for Deep Learning: Training BERT in 76 minutes
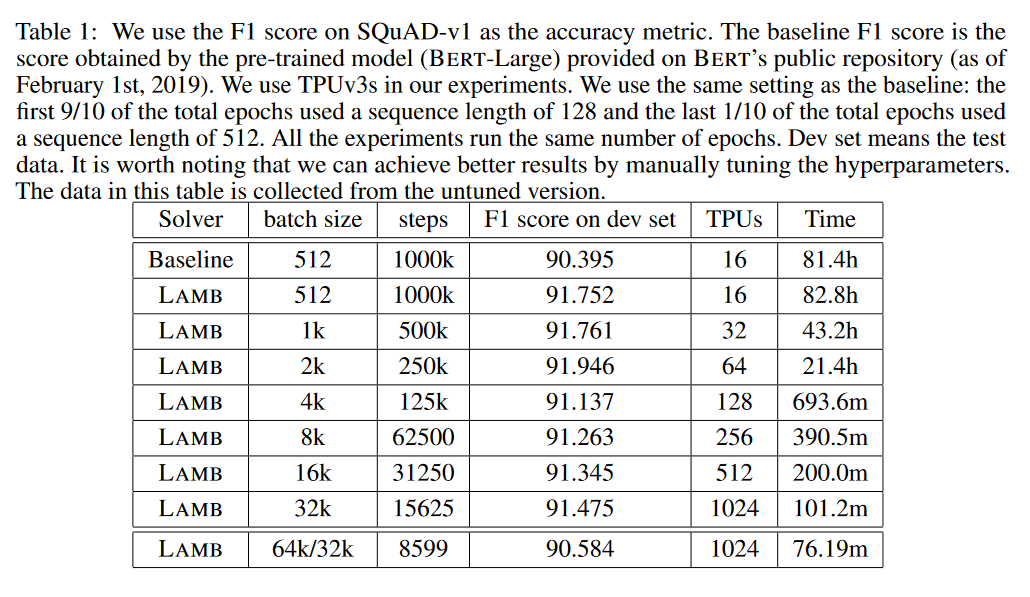
摘要: 在海量数据集上训练大型深层神经网络在计算上具有很大的挑战性。最近,人们对使用大批量随机优化方法来解决这个问题的兴趣激增。在这方面最突出的算法是LARS,它通过采用分层自适应学习率在几分钟内在ImageNet上训练ResNet。然而,LARS对于像BERT这样的注意模型表现不佳,这表明它的性能增益在任务之间并不一致。本文首先研究了一种原则性的分层自适应策略,以加速大批量、小批量的深层神经网络训练。利用该策略,我们发展了一种新的分层自适应大批量优化技术LAMB,并给出了LAMB和LARS的收敛性分析,给出了一般非凸情形下LAMB和LARS的收敛性。实验结果表明,LAMB在BERT和ResNet-50训练等任务中具有很好的性能,且超参数调整很少。特别是,对于BERT训练,我们的优化器允许使用非常大的批量大小32868,而不会降低性能。通过将批处理大小增加到TPUv3 Pod的内存限制,BERT训练时间可以从3天减少到76分钟。
作者简介: Sashank J. Reddi,他是卡内基梅隆大学机器学习系的博士生。他的主要兴趣是机器学习、优化、统计学和计算机科学理论。个人主页:http://www.cs.cmu.edu/~sjakkamr/index.html。
Sanjiv Kumar,博士,谷歌研究科学家。他的研究方向未大型机器学习,人工智能,健康人工智能,计算机视觉,机器人。个人主页:[http://www.sanjivk.com/}(http://www.sanjivk.com/) 

成为VIP会员查看完整内容




相关VIP内容
相关资讯
相关论文
Arxiv
16+阅读 · 2019年5月24日