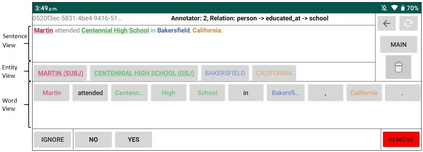
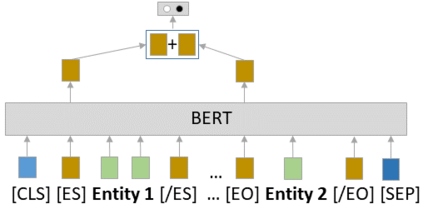
To effectively train accurate Relation Extraction models, sufficient and properly labeled data is required. Adequately labeled data is difficult to obtain and annotating such data is a tricky undertaking. Previous works have shown that either accuracy has to be sacrificed or the task is extremely time-consuming, if done accurately. We are proposing an approach in order to produce high-quality datasets for the task of Relation Extraction quickly. Neural models, trained to do Relation Extraction on the created datasets, achieve very good results and generalize well to other datasets. In our study, we were able to annotate 10,022 sentences for 19 relations in a reasonable amount of time, and trained a commonly used baseline model for each relation.
翻译:为了有效地培训准确的采掘模型,需要足够和贴有适当标签的数据。很难获得贴上充分标签的数据,说明这类数据是一项棘手的工作。以前的工作表明,要么必须牺牲准确性,要么如果准确完成,任务十分耗时。我们提出一种方法,以便迅速产生高质量的数据集,完成Relation采掘任务。神经模型,经过培训,能够根据创建的数据集进行采掘,取得非常好的结果,并与其他数据集相提并论。在我们的研究中,我们能够在合理的时间内对19个关系中的10,022个句子进行注解,并培训了每种关系的通用基准模型。