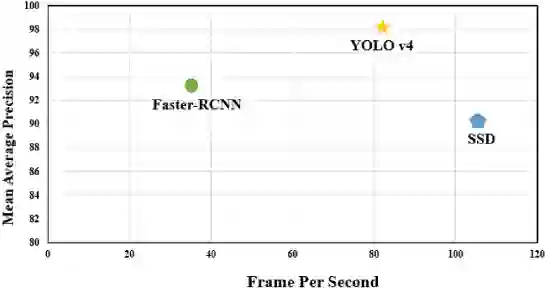
Purpose: Object detection is rapidly evolving through machine learning technology in automation systems. Well prepared data is necessary to train the algorithms. Accordingly, the objective of this paper is to describe a re-evaluation of the so-called Logistics Objects in Context (LOCO) dataset, which is the first dataset for object detection in the field of intralogistics. Methodology: We use an experimental research approach with three steps to evaluate the LOCO dataset. Firstly, the images on GitHub were analyzed to understand the dataset better. Secondly, Google Drive Cloud was used for training purposes to revisit the algorithmic implementation and training. Lastly, the LOCO dataset was examined, if it is possible to achieve the same training results in comparison to the original publications. Findings: The mean average precision, a common benchmark in object detection, achieved in our study was 64.54%, and shows a significant increase from the initial study of the LOCO authors, achieving 41%. However, improvement potential is seen specifically within object types of forklifts and pallet truck. Originality: This paper presents the first critical replication study of the LOCO dataset for object detection in intralogistics. It shows that the training with better hyperparameters based on LOCO can even achieve a higher accuracy than presented in the original publication. However, there is also further room for improving the LOCO dataset.
翻译:目的: 物体探测正在通过自动化系统中的机器学习技术迅速演变。 良好的数据是培训算法所需要的。 因此, 本文的目的是描述对所谓的“ 内地后勤物体” 数据集的重新评价, 这是在内部后勤领域用于物体探测的第一个数据集。 方法: 我们使用实验研究方法, 分三个步骤来评价LOCO数据集。 首先, 对GitHub的图像进行了分析, 以便更好地了解数据集。 其次, Google Dread Cluud 被用于培训目的, 以重新审视算法实施和培训。 最后, LOCO 数据集接受了审查, 如果有可能实现与原始出版物相同的培训结果的话。 研究结果: 我们的研究中实现的平均精确度, 目标探测的共同基准是64.54%, 显示与LOCO作者的初步研究相比, 有了显著的增加, 达到41%。 然而, 改进的潜力被具体表现在叉车和托莱卡车的物体类型中。 原始文件展示了LOCO 更精确度, 也显示在内部的原始出版物上实现更精确性。