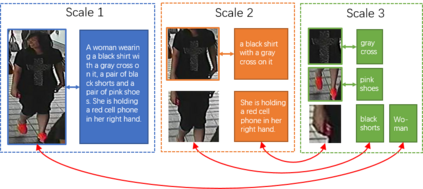
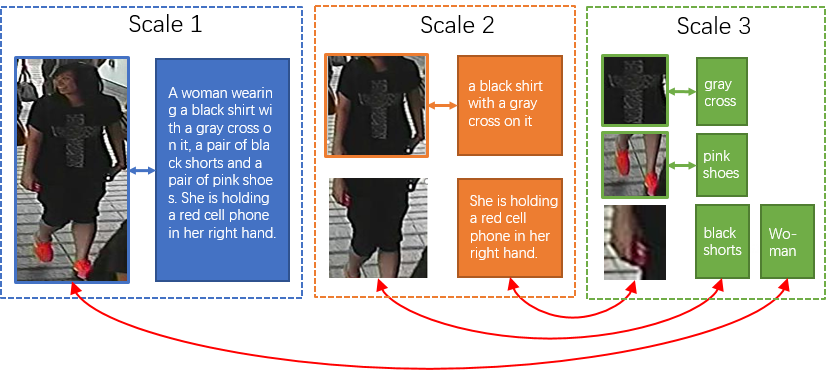
Text-based person search aims at retrieving target person in an image gallery using a descriptive sentence of that person. It is very challenging since modal gap makes effectively extracting discriminative features more difficult. Moreover, the inter-class variance of both pedestrian images and descriptions is small. So comprehensive information is needed to align visual and textual clues across all scales. Most existing methods merely consider the local alignment between images and texts within a single scale (e.g. only global scale or only partial scale) then simply construct alignment at each scale separately. To address this problem, we propose a method that is able to adaptively align image and textual features across all scales, called NAFS (i.e.Non-local Alignment over Full-Scale representations). Firstly, a novel staircase network structure is proposed to extract full-scale image features with better locality. Secondly, a BERT with locality-constrained attention is proposed to obtain representations of descriptions at different scales. Then, instead of separately aligning features at each scale, a novel contextual non-local attention mechanism is applied to simultaneously discover latent alignments across all scales. The experimental results show that our method outperforms the state-of-the-art methods by 5.53% in terms of top-1 and 5.35% in terms of top-5 on text-based person search dataset. The code is available at https://github.com/TencentYoutuResearch/PersonReID-NAFS
翻译:以文字为基础的个人搜索旨在使用某人的描述性句子在图像画廊中检索目标人物。 模式差距使得有效提取歧视特征更加困难, 是非常具有挑战性。 此外, 行人图像和描述的类别间差异很小。 因此, 需要全面的信息来协调所有尺度的视觉和文字线索。 大多数现有方法仅仅考虑图像和文本在单一尺度( 例如, 仅全球规模或仅部分规模) 中的地方对齐, 然后简单地在每一个尺度上分别构建对齐。 为了解决这个问题, 我们提出了一个能够在所有尺度上适应性地对图像和文字特征进行对齐的方法, 叫做 NAFS( 即非本地对齐全尺度表达式的对齐) 。 首先, 提出一个新的楼梯网络结构, 来将全尺度的图像和文字线索定位相匹配。 其次, 提议一个受地方制约的图像和文字对齐的图像对齐度, 之后, 将一个新的背景非局部关注机制用于同时发现所有尺度上的潜在对齐的图像和文字对齐。 实验结果显示, 以5.35 的搜索术语以5 的顶级格式, 将个人的搜索值 以5/ 格式以最高值 格式 格式 格式 。