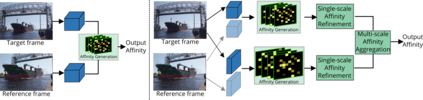
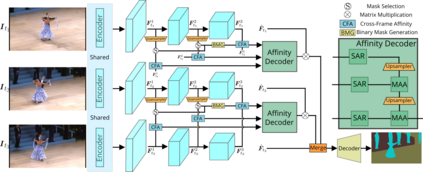
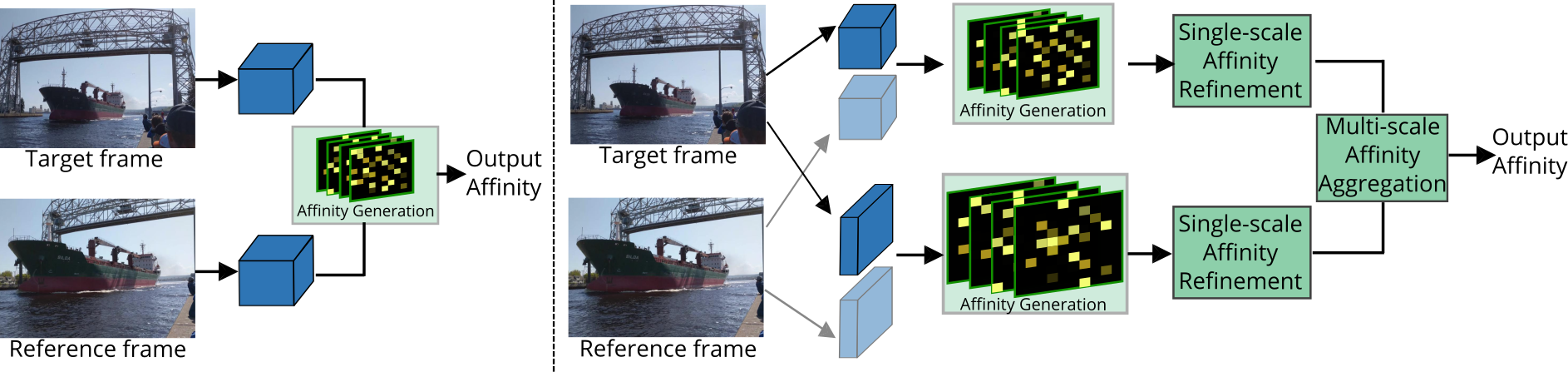
The essence of video semantic segmentation (VSS) is how to leverage temporal information for prediction. Previous efforts are mainly devoted to developing new techniques to calculate the cross-frame affinities such as optical flow and attention. Instead, this paper contributes from a different angle by mining relations among cross-frame affinities, upon which better temporal information aggregation could be achieved. We explore relations among affinities in two aspects: single-scale intrinsic correlations and multi-scale relations. Inspired by traditional feature processing, we propose Single-scale Affinity Refinement (SAR) and Multi-scale Affinity Aggregation (MAA). To make it feasible to execute MAA, we propose a Selective Token Masking (STM) strategy to select a subset of consistent reference tokens for different scales when calculating affinities, which also improves the efficiency of our method. At last, the cross-frame affinities strengthened by SAR and MAA are adopted for adaptively aggregating temporal information. Our experiments demonstrate that the proposed method performs favorably against state-of-the-art VSS methods. The code is publicly available at https://github.com/GuoleiSun/VSS-MRCFA
翻译:视频语义分解(VSS)的精髓在于如何利用时间信息进行预测。以前的努力主要致力于开发新技术,以计算光学流和注意力等跨框架的亲近性。相反,本文件通过跨框架的亲近关系从不同的角度提出,可以实现更好的时间信息汇总。我们从两个方面探讨亲近关系:单一规模的内在关联和多尺度的关系。在传统特征处理的启发下,我们提议单一规模的亲近精炼(SAR)和多尺度的亲近聚合(MAA)。为了使执行MAA成为可行,我们提议了一项选择性的托肯遮掩(STM)战略,以便在计算亲近性时为不同尺度选择一组一致的参考符号,这也提高了我们方法的效率。最后,通过SA和MAA加强的交叉框架用于适应性综合时间信息。我们的实验表明,拟议的方法优于国家-艺术VSS方法。在 https://gilub/Goub./GUNSS/公开提供该代码。