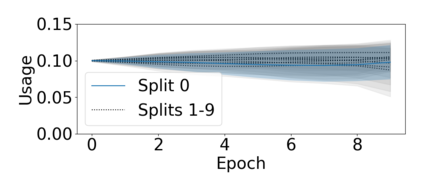
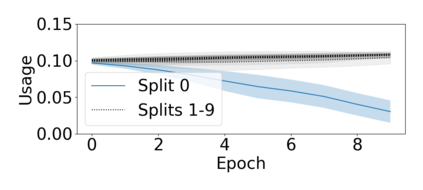
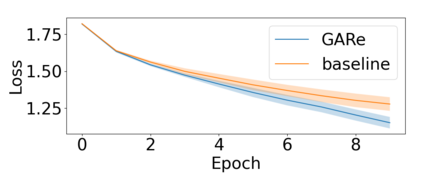
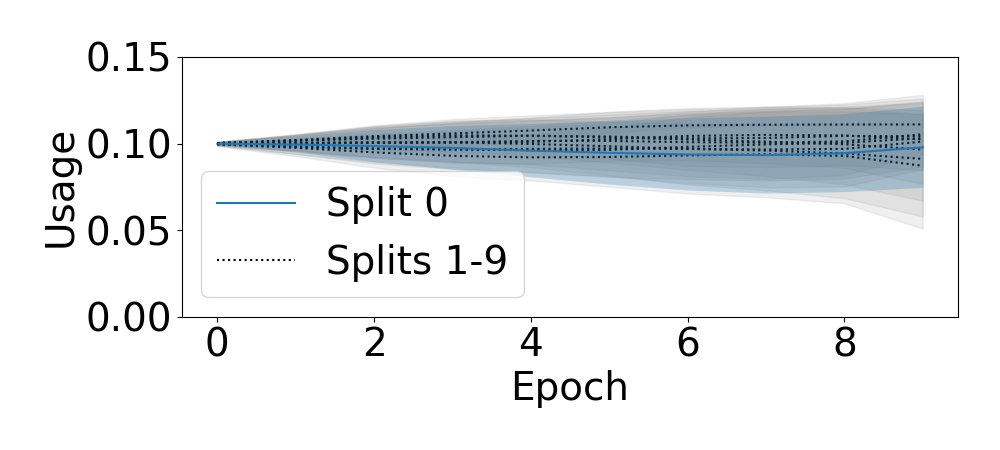
At the heart of the standard deep learning training loop is a greedy gradient step minimizing a given loss. We propose to add a second step to maximize training generalization. To do this, we optimize the loss of the next training step. While computing the gradient for this generally is very expensive and many interesting applications consider non-differentiable parameters (e.g. due to hard samples), we present a cheap-to-compute and memory-saving reward, the gradient-alignment reward (GAR), that can guide the optimization. We use this reward to optimize multiple distributions during model training. First, we present the application of GAR to choosing the data distribution as a mixture of multiple dataset splits in a small scale setting. Second, we show that it can successfully guide learning augmentation strategies competitive with state-of-the-art augmentation strategies on CIFAR-10 and CIFAR-100.
翻译:标准的深层学习培训循环的核心是贪婪的梯度步骤,最大限度地减少给定损失。 我们提议增加第二步, 尽量扩大培训的概括性。 为此, 我们优化下一个培训步骤的丢失。 计算梯度通常非常昂贵, 许多有趣的应用都考虑到非差别性参数( 例如由于硬抽样), 我们提出了一个廉价的计算和记忆保存奖项, 梯度比对奖项( GAR), 可以引导优化优化。 我们利用这一奖励来优化模型培训期间的多重分布。 首先, 我们提出应用GAR来选择数据分配方式, 将多个数据集分成一个小规模的混合体。 其次, 我们展示它能够成功地指导具有竞争力的增强战略, 与最新的CIFAR- 10 和 CIFAR- 100 增强战略相比具有竞争力。