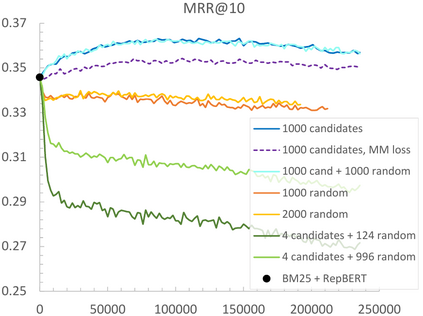
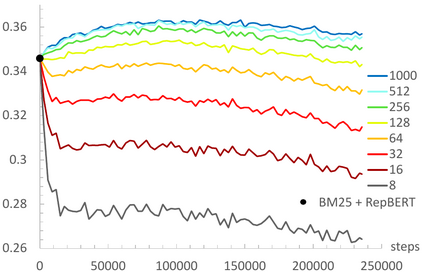
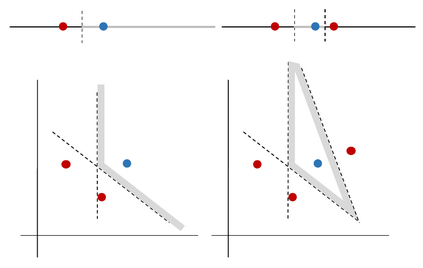
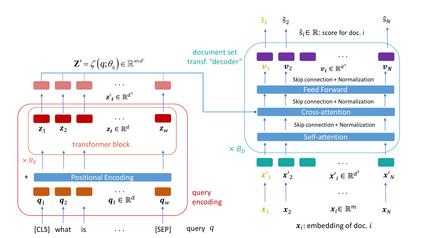
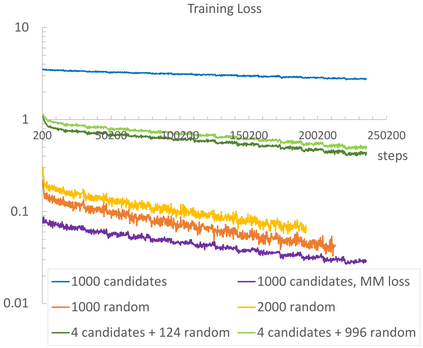
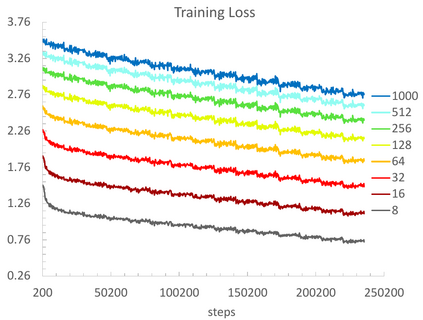
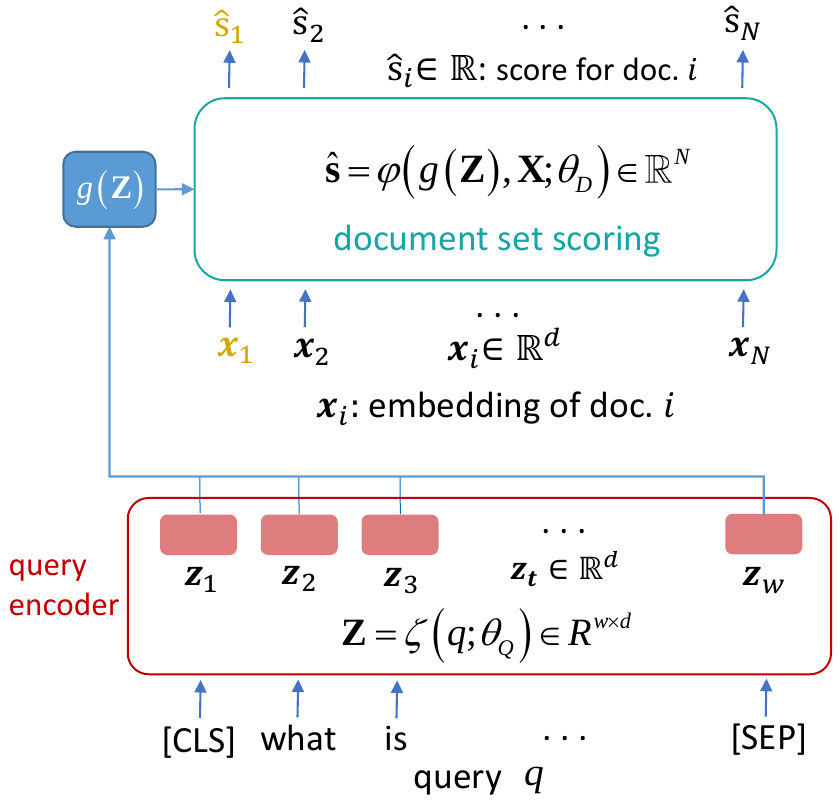
Contrastive learning has been the dominant approach to training dense retrieval models. In this work, we investigate the impact of ranking context - an often overlooked aspect of learning dense retrieval models. In particular, we examine the effect of its constituent parts: jointly scoring a large number of negatives per query, using retrieved (query-specific) instead of random negatives, and a fully list-wise loss. To incorporate these factors into training, we introduce Contextual Document Embedding Reranking (CODER), a highly efficient retrieval framework. When reranking, it incurs only a negligible computational overhead on top of a first-stage method at run time (delay per query in the order of milliseconds), allowing it to be easily combined with any state-of-the-art dual encoder method. After fine-tuning through CODER, which is a lightweight and fast process, models can also be used as stand-alone retrievers. Evaluating CODER in a large set of experiments on the MS~MARCO and TripClick collections, we show that the contextual reranking of precomputed document embeddings leads to a significant improvement in retrieval performance. This improvement becomes even more pronounced when more relevance information per query is available, shown in the TripClick collection, where we establish new state-of-the-art results by a large margin.
翻译:在这项工作中,我们调查了排名背景的影响,这是学习密集检索模型的一个经常被忽视的方面。特别是,我们检查了其组成部分的影响:使用检索的(特定查询)而不是随机的负数,每个查询联合评分大量负数,而不是随机的负数,以及完全列出损失。为了将这些因素纳入培训,我们引入了背景文件嵌入重排(CODER),这是一个高度高效的检索框架。在重新排队时,在运行的第一阶段方法顶端,它只产生微不足道的计算间接费用(按毫秒顺序排列每个查询间隔),使得它很容易与任何最先进的双编码器方法相结合。在通过CDCDER(轻量度和快速过程)微调后,模型也可以用作独立检索器。在MS~MARCO和TripClick收藏的大规模实验中评估CODER(CO),我们显示,在初始文件嵌入前文件的背景重新排列导致显著的改进,在检索成绩方面,我们通过显示的大幅度的进度,这种改进在每轨迹上显示,这种改进会更明显地显示新的进展。