
题目: Learning Problem-agnostic Speech Representations from Multiple Self-supervised Tasks
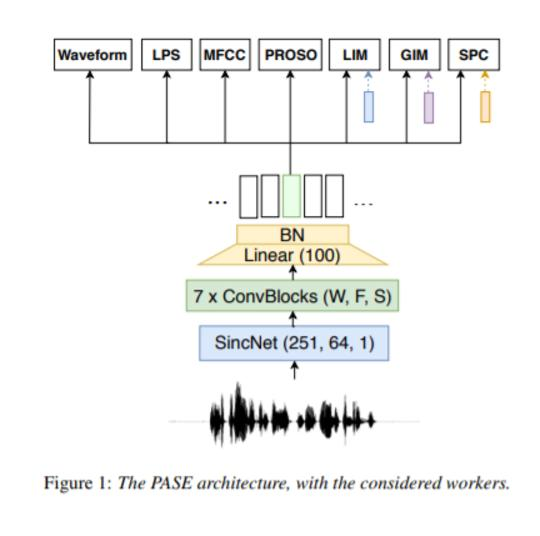
摘要: 无监督学习的表示仍然是机器学习中的一个开放问题,尤其是语音信号的挑战,语音信号的特征通常是长序列和复杂的层次结构。然而,最近的一些研究表明,通过使用一种自监督的编码器-鉴别器方法来获得有用的语音表示是可能的。本文提出了一种改进的自监督方法,即一个神经编码器由多个工作者共同完成不同的自监督任务。不同任务之间所需的一致意见自然会给编码人员带来有意义的约束,有助于发现一般的表示,并将学习浅显表示的风险降至最低。实验表明,该方法可以学习可迁移的、具有鲁棒性的、与问题无关的特征,这些特征从语音信号中传递相关信息,如说话人身份、音素,甚至更高层次的特征,如情感线索。此外,大量的设计选择使编码器易于输出,方便其直接使用或适应不同的问题。
成为VIP会员查看完整内容
相关内容

专知会员服务
69+阅读 · 2020年6月19日
专知会员服务
51+阅读 · 2020年2月22日
专知会员服务
39+阅读 · 2020年1月30日
专知会员服务
33+阅读 · 2020年1月5日
专知会员服务
115+阅读 · 2020年1月3日
Arxiv
5+阅读 · 2019年2月14日

相关VIP内容
专知会员服务
69+阅读 · 2020年6月19日
专知会员服务
51+阅读 · 2020年2月22日
专知会员服务
39+阅读 · 2020年1月30日
专知会员服务
33+阅读 · 2020年1月5日
专知会员服务
115+阅读 · 2020年1月3日
相关资讯
相关论文
Arxiv
5+阅读 · 2019年2月14日