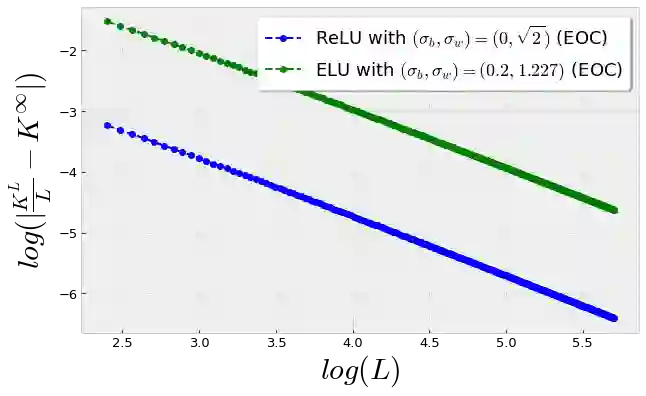
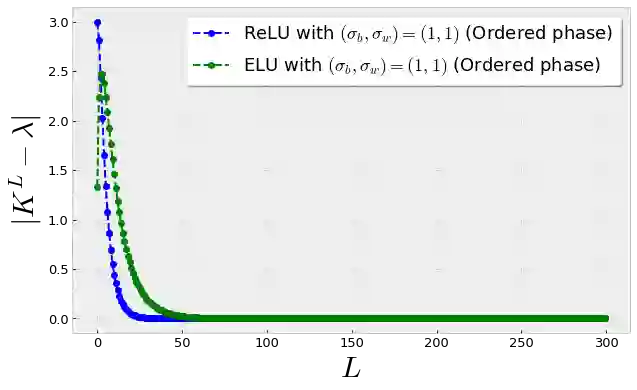
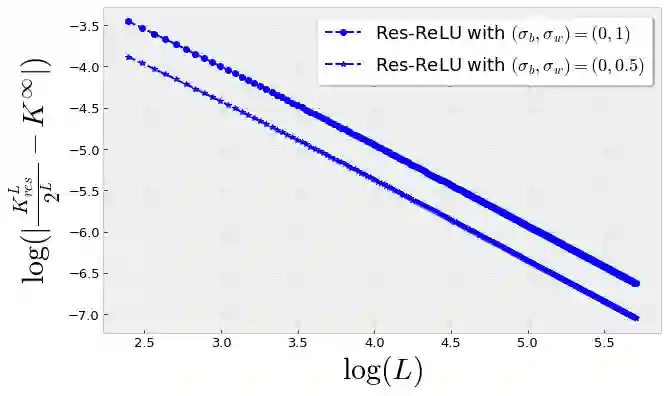
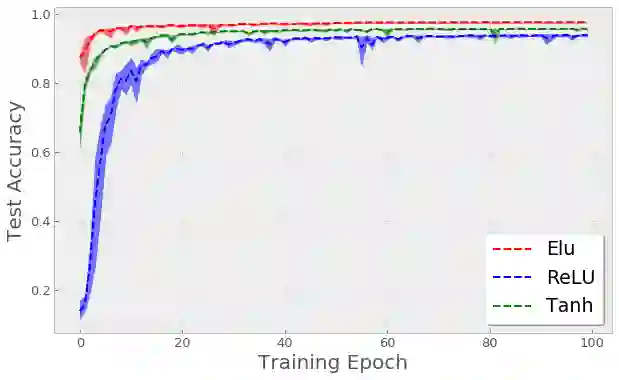
Recent work by Jacot et al. (2018) has showed that training a neural network of any kind with gradient descent in parameter space is equivalent to kernel gradient descent in function space with respect to the Neural Tangent Kernel (NTK). Lee et al. (2019) built on this result to show that the output of a neural network trained using full batch gradient descent can be approximated by a linear model for wide networks. In parallel, a recent line of studies (Schoenholz et al. (2017), Hayou et al. (2019)) suggested that a special initialization known as the Edge of Chaos leads to good performance. In this paper, we bridge the gap between these two concepts and show the impact of the initialization and the activation function on the NTK as the network depth becomes large. We provide experiments illustrating our theoretical results.
翻译:Jacot等人(2018年)最近的工作表明,在参数空间中,对具有梯度下行的任何类型的神经网络进行培训,相当于神经唐氏内核(NTK)在功能空间中的内核梯度下行。 Lee等人(2019年)以这一结果为基础,表明利用整批梯度下行进行训练的神经网络的产出可以用宽网络的线性模型近似。与此同时,最近的一系列研究(Schoenholz等人(2017年)、Hayou等人(2019年))表明,被称为Chaos Edge的特种初始化可以带来良好的表现。在本文件中,我们弥合这两个概念之间的差距,并表明随着网络深度的扩大,初始化和启动功能对NTK的影响。我们提供实验,说明我们的理论结果。