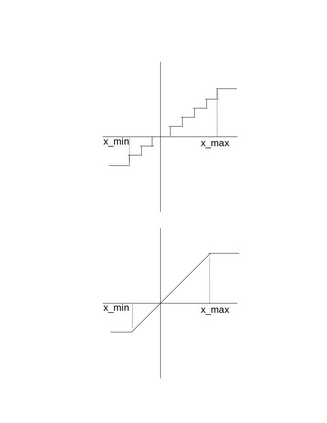
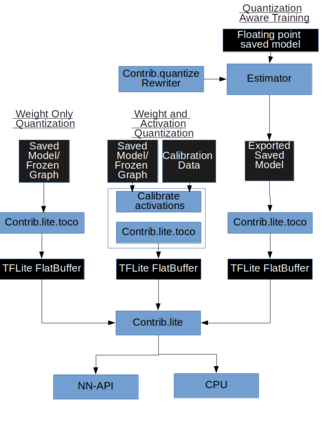
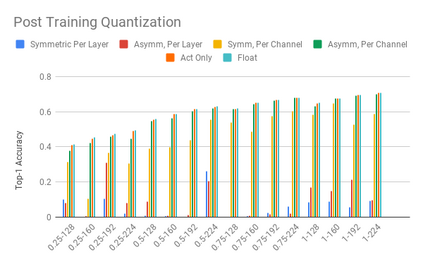
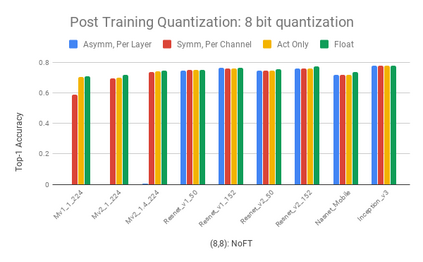
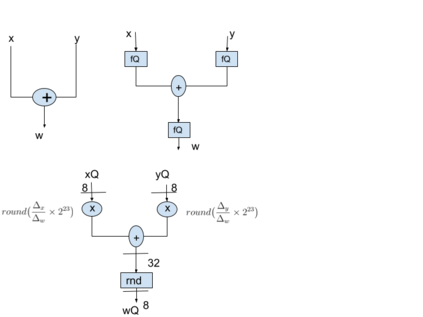
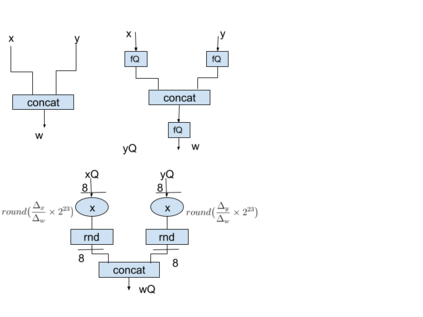
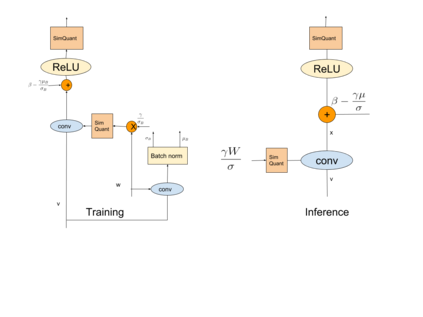
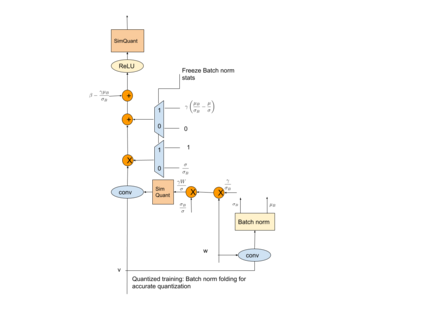
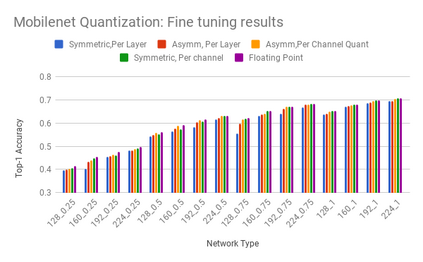
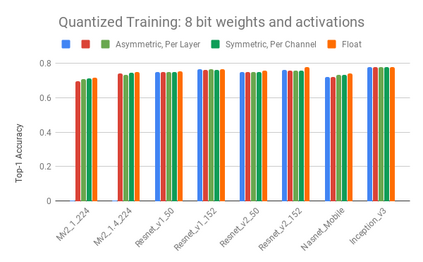
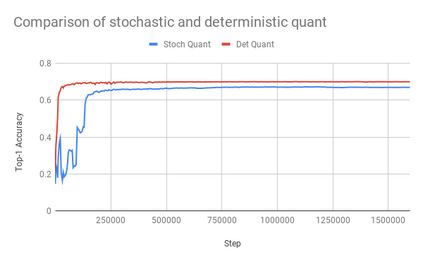
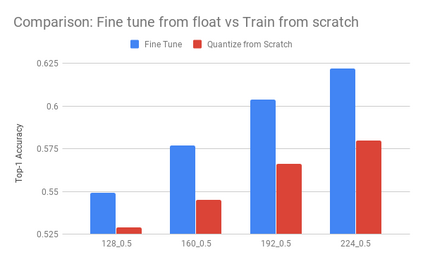
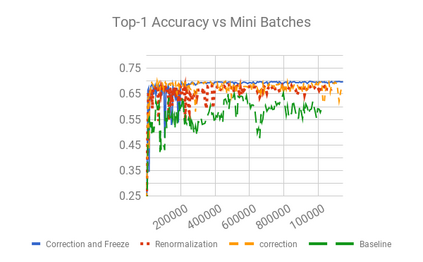
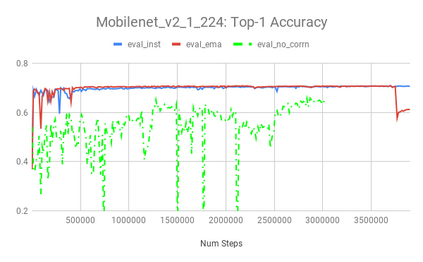
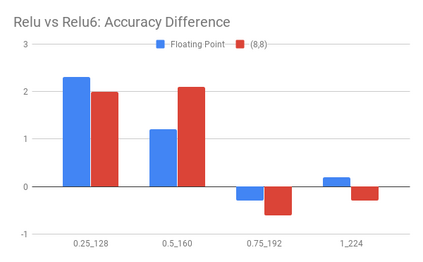
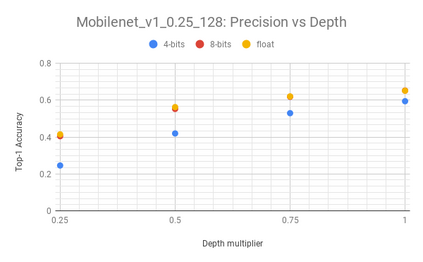
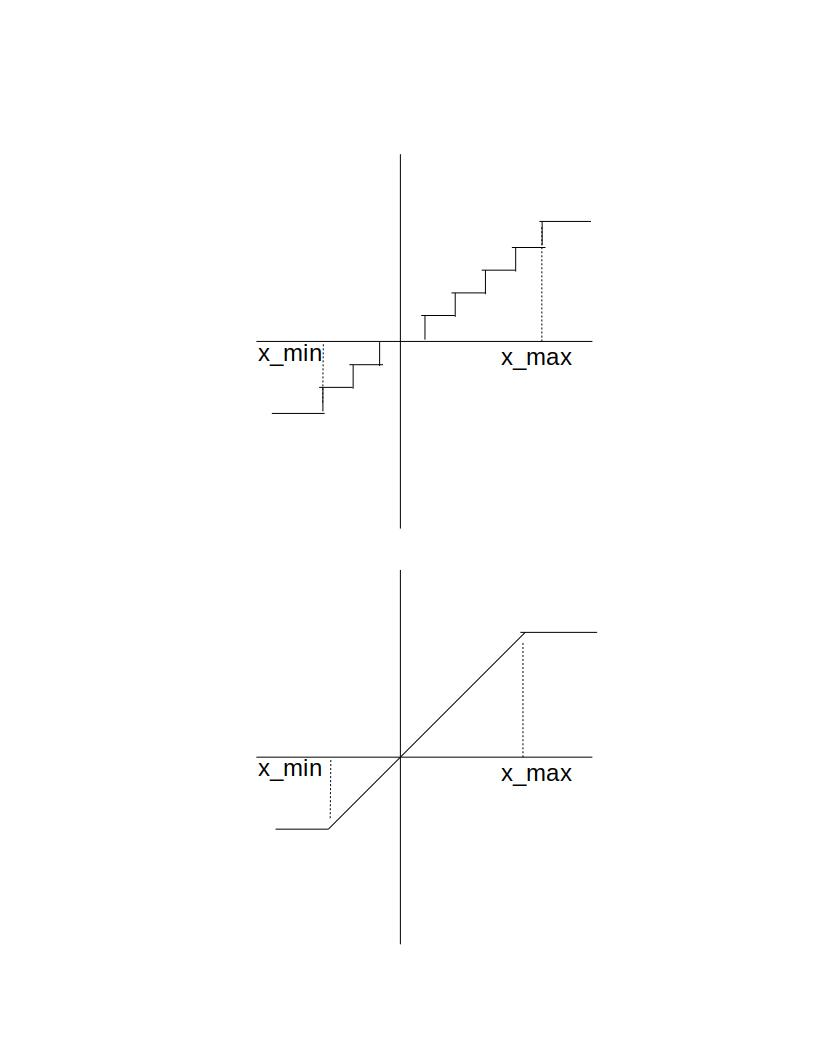
We present an overview of techniques for quantizing convolutional neural networks for inference with integer weights and activations. Per-channel quantization of weights and per-layer quantization of activations to 8-bits of precision post-training produces classification accuracies within 2% of floating point networks for a wide variety of CNN architectures. Model sizes can be reduced by a factor of 4 by quantizing weights to 8-bits, even when 8-bit arithmetic is not supported. This can be achieved with simple, post training quantization of weights.We benchmark latencies of quantized networks on CPUs and DSPs and observe a speedup of 2x-3x for quantized implementations compared to floating point on CPUs. Speedups of up to 10x are observed on specialized processors with fixed point SIMD capabilities, like the Qualcomm QDSPs with HVX. Quantization-aware training can provide further improvements, reducing the gap to floating point to 1% at 8-bit precision. Quantization-aware training also allows for reducing the precision of weights to four bits with accuracy losses ranging from 2% to 10%, with higher accuracy drop for smaller networks.We introduce tools in TensorFlow and TensorFlowLite for quantizing convolutional networks and review best practices for quantization-aware training to obtain high accuracy with quantized weights and activations. We recommend that per-channel quantization of weights and per-layer quantization of activations be the preferred quantization scheme for hardware acceleration and kernel optimization. We also propose that future processors and hardware accelerators for optimized inference support precisions of 4, 8 and 16 bits.
翻译:我们展示了以整数重量和激活作用来量化螺旋神经网络的技术概览。 精密后训练中, 将重量和启动量的每层量量化到8比特的精度8比特的精度后, 将在浮动点网络的2%范围内为各种CNN结构进行分类。 模型大小可以通过四倍的重量量化到8比特, 即使不支持 8比特的算术。 可以通过简单、 培训后重量的定量来实现这一目标。 我们为CPS 和 DSP 的精度和每个端点的精度网络设定过量网络的延迟值,并观察到与8比8比特的精度相比,在8比特的精度网络中,将精度为2x-3x的精度实施速度加速。 在具有固定点的SIMD能力的专门处理器上, 可以观察到高达10比特的加速度, 例如Qalcomm QDSPs 和HVX。 定量支持- 培训可以提供进一步的改进, 将差距降至1比特的精确度, 在8比特的精度网络上, 将精度的精度的精度的精度中, 将精度的精度的精度的精度测试到10比的精度的精度的精度测试的精度的精度提高到的精度提高到的精度的精度提高到的精度的精度的精度 。