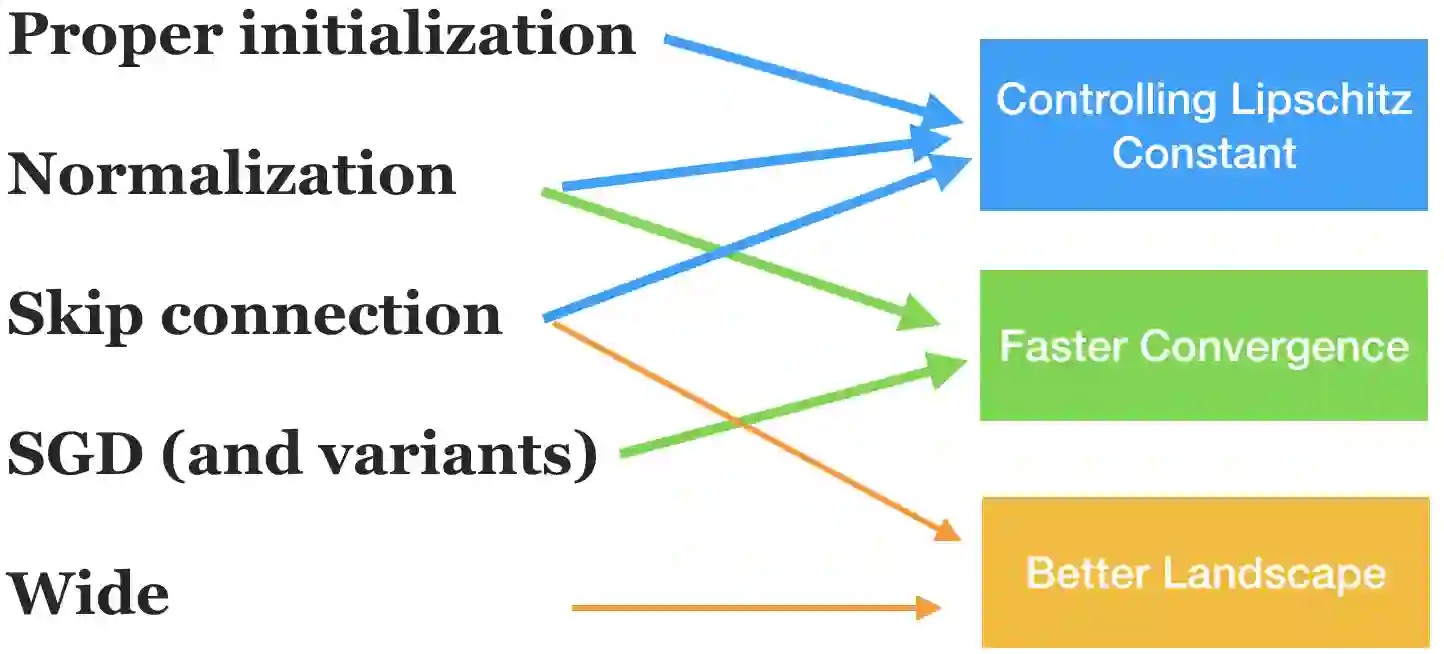
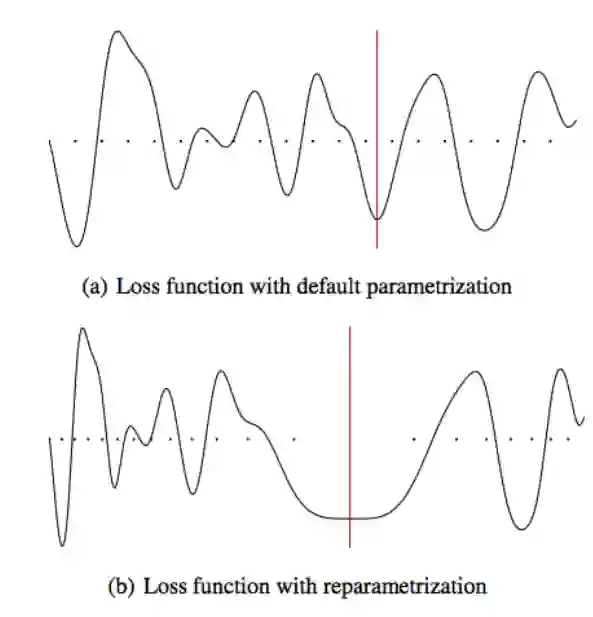
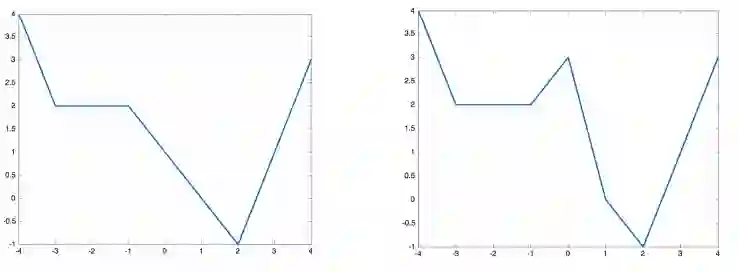
When and why can a neural network be successfully trained? This article provides an overview of optimization algorithms and theory for training neural networks. First, we discuss the issue of gradient explosion/vanishing and the more general issue of undesirable spectrum, and then discuss practical solutions including careful initialization and normalization methods. Second, we review generic optimization methods used in training neural networks, such as SGD, adaptive gradient methods and distributed methods, and theoretical results for these algorithms. Third, we review existing research on the global issues of neural network training, including results on bad local minima, mode connectivity, lottery ticket hypothesis and infinite-width analysis.
翻译:何时和为什么能够成功培训神经网络? 文章概述了用于培训神经网络的优化算法和理论。 首先,我们讨论梯度爆炸/衰落问题以及更普遍的不良频谱问题,然后讨论实际解决办法,包括谨慎的初始化和正常化方法。 其次,我们审查用于培训神经网络的通用优化方法,如SGD、适应性梯度方法和分布方法,以及这些算法的理论结果。 第三,我们审查关于神经网络培训全球问题的现有研究,包括当地微米、模式连接、彩票假设和无限分析的结果。