【论文推荐】最新六篇主题模型相关论文—收敛率、大规模、深度主题建模、优化、情绪强度、广义动态主题模型
【导读】专知内容组整理了最近六篇主题模型(Topic Model)相关文章,为大家进行介绍,欢迎查看!
1.Convergence Rates of Latent Topic Models Under Relaxed Identifiability Conditions(在松弛可识别性条件下潜在主题模型的收敛率)
作者:Yining Wang
机构:Carnegie Mellon University
摘要:In this paper we study the frequentist convergence rate for the Latent Dirichlet Allocation (Blei et al., 2003) topic models. We show that the maximum likelihood estimator converges to one of the finitely many equivalent parameters in Wasserstein's distance metric at a rate of $n^{-1/4}$ without assuming separability or non-degeneracy of the underlying topics and/or the existence of more than three words per document, thus generalizing the previous works of Anandkumar et al. (2012, 2014) from an information-theoretical perspective. We also show that the $n^{-1/4}$ convergence rate is optimal in the worst case.

期刊:arXiv, 2018年3月18日
网址:
http://www.zhuanzhi.ai/document/791bd044fe3db3e6de1b4c3a328de3ea
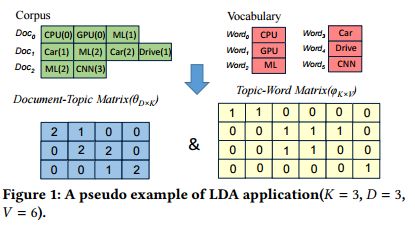
2.CuLDA_CGS: Solving Large-scale LDA Problems on GPUs(CuLDA_CGS:解决GPUs上的大规模LDA问题)
作者:Xiaolong Xie,Yun Liang,Xiuhong Li,Wei Tan
机构:Peking University
摘要:Latent Dirichlet Allocation(LDA) is a popular topic model. Given the fact that the input corpus of LDA algorithms consists of millions to billions of tokens, the LDA training process is very time-consuming, which may prevent the usage of LDA in many scenarios, e.g., online service. GPUs have benefited modern machine learning algorithms and big data analysis as they can provide high memory bandwidth and computation power. Therefore, many frameworks, e.g. Ten- sorFlow, Caffe, CNTK, support to use GPUs for accelerating the popular machine learning data-intensive algorithms. However, we observe that LDA solutions on GPUs are not satisfying. In this paper, we present CuLDA_CGS, a GPU-based efficient and scalable approach to accelerate large-scale LDA problems. CuLDA_CGS is designed to efficiently solve LDA problems at high throughput. To it, we first delicately design workload partition and synchronization mechanism to exploit the benefits of mul- tiple GPUs. Then, we offload the LDA sampling process to each individual GPU by optimizing from the sampling algorithm, par- allelization, and data compression perspectives. Evaluations show that compared with state-of-the-art LDA solutions, CuLDA_CGS outperforms them by a large margin (up to 7.3X) on a single GPU. CuLDA_CGS is able to achieve extra 3.0X speedup on 4 GPUs. The source code is publicly available on https://github.com/cuMF/ CuLDA_CGS.
期刊:arXiv, 2018年3月13日
网址:
http://www.zhuanzhi.ai/document/34a1e75e4ab744eec51bb1b8096a13b4
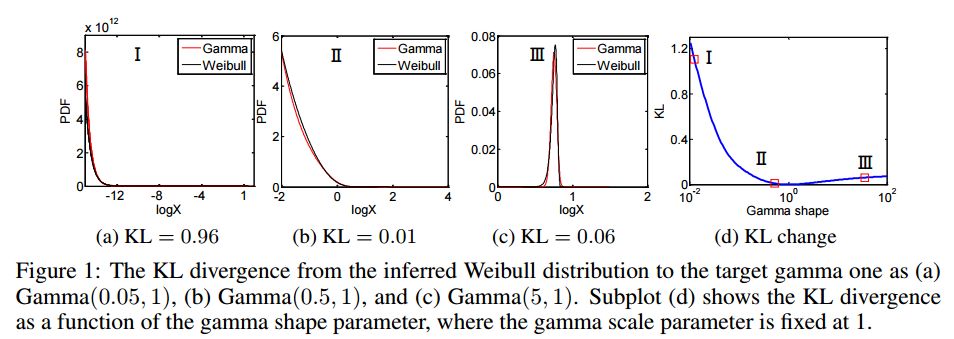
3.WHAI: Weibull Hybrid Autoencoding Inference for Deep Topic Modeling(WHAI:威布尔混合自编码推理的深度主题建模)
作者:Hao Zhang,Bo Chen,Dandan Guo,Mingyuan Zhou
机构:Xidian University,The University of Texas at Austin
摘要:To train an inference network jointly with a deep generative topic model, making it both scalable to big corpora and fast in out-of-sample prediction, we develop Weibull hybrid autoencoding inference (WHAI) for deep latent Dirichlet allocation, which infers posterior samples via a hybrid of stochastic-gradient MCMC and autoencoding variational Bayes. The generative network of WHAI has a hierarchy of gamma distributions, while the inference network of WHAI is a Weibull upward-downward variational autoencoder, which integrates a deterministic-upward deep neural network, and a stochastic-downward deep generative model based on a hierarchy of Weibull distributions. The Weibull distribution can be used to well approximate a gamma distribution with an analytic Kullback-Leibler divergence, and has a simple reparameterization via the uniform noise, which help efficiently compute the gradients of the evidence lower bound with respect to the parameters of the inference network. The effectiveness and efficiency of WHAI are illustrated with experiments on big corpora.
期刊:arXiv, 2018年3月4日
网址:
http://www.zhuanzhi.ai/document/bc25b1fdf3ff6db4ac6ba4fa28c63ac1
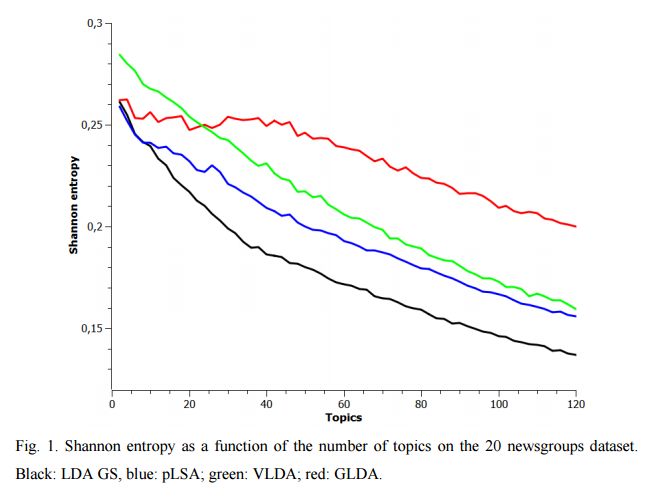
4.Application of Rényi and Tsallis Entropies to Topic Modeling Optimization(Renyi和Tsallis熵在主题建模优化中的应用)
作者:Koltcov Sergei
摘要:This is full length article (draft version) where problem number of topics in Topic Modeling is discussed. We proposed idea that Renyi and Tsallis entropy can be used for identification of optimal number in large textual collections. We also report results of numerical experiments of Semantic stability for 4 topic models, which shows that semantic stability play very important role in problem topic number. The calculation of Renyi and Tsallis entropy based on thermodynamics approach.
期刊:arXiv, 2018年3月1日
网址:
http://www.zhuanzhi.ai/document/816c7644baa708ae678d14b7f8abdf28
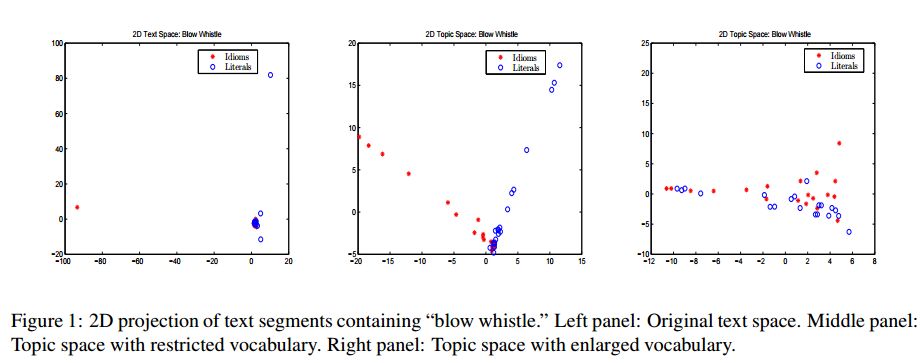
5.Classifying Idiomatic and Literal Expressions Using Topic Models and Intensity of Emotions(使用主题模型和情绪的强度将习语和文字分类)
作者:Jing Peng,Anna Feldman,Ekaterina Vylomova
机构:Bauman State Technical University,Montclair State University
摘要:We describe an algorithm for automatic classification of idiomatic and literal expressions. Our starting point is that words in a given text segment, such as a paragraph, that are highranking representatives of a common topic of discussion are less likely to be a part of an idiomatic expression. Our additional hypothesis is that contexts in which idioms occur, typically, are more affective and therefore, we incorporate a simple analysis of the intensity of the emotions expressed by the contexts. We investigate the bag of words topic representation of one to three paragraphs containing an expression that should be classified as idiomatic or literal (a target phrase). We extract topics from paragraphs containing idioms and from paragraphs containing literals using an unsupervised clustering method, Latent Dirichlet Allocation (LDA) (Blei et al., 2003). Since idiomatic expressions exhibit the property of non-compositionality, we assume that they usually present different semantics than the words used in the local topic. We treat idioms as semantic outliers, and the identification of a semantic shift as outlier detection. Thus, this topic representation allows us to differentiate idioms from literals using local semantic contexts. Our results are encouraging.
期刊:arXiv, 2018年2月27日
网址:
http://www.zhuanzhi.ai/document/3a2e1b8fb8dfebf67b9d077c7064302e
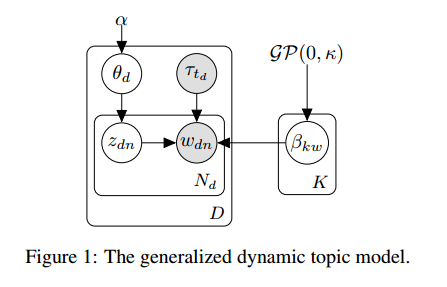
6.Scalable Generalized Dynamic Topic Models(可伸缩的广义动态主题模型)
作者:Patrick Jähnichen,Florian Wenzel,Marius Kloft,Stephan Mandt
机构:Humboldt-Universität zu Berlin
摘要:Dynamic topic models (DTMs) model the evolution of prevalent themes in literature, online media, and other forms of text over time. DTMs assume that word co-occurrence statistics change continuously and therefore impose continuous stochastic process priors on their model parameters. These dynamical priors make inference much harder than in regular topic models, and also limit scalability. In this paper, we present several new results around DTMs. First, we extend the class of tractable priors from Wiener processes to the generic class of Gaussian processes (GPs). This allows us to explore topics that develop smoothly over time, that have a long-term memory or are temporally concentrated (for event detection). Second, we show how to perform scalable approximate inference in these models based on ideas around stochastic variational inference and sparse Gaussian processes. This way we can train a rich family of DTMs to massive data. Our experiments on several large-scale datasets show that our generalized model allows us to find interesting patterns that were not accessible by previous approaches.
期刊:arXiv, 2018年3月21日
网址:
http://www.zhuanzhi.ai/document/b0d86c66d398e7a43f7a4b445251e1ae
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

点击“阅读原文”,使用专知!




