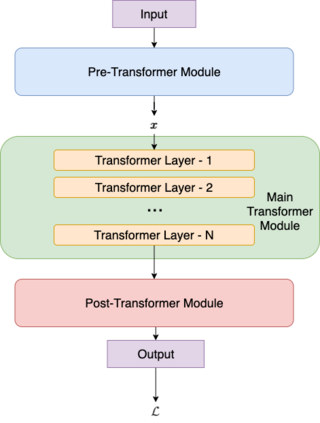
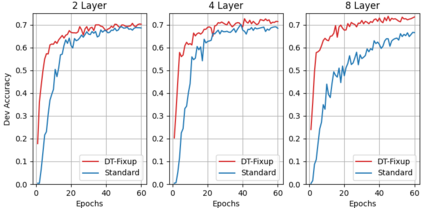
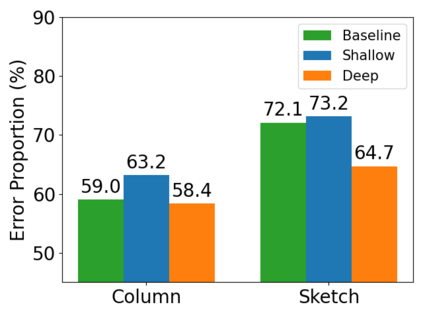
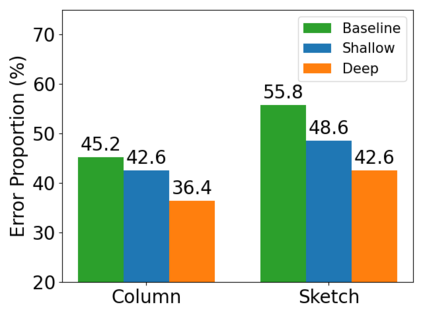
It is a common belief that training deep transformers from scratch requires large datasets. Consequently, for small datasets, people usually use shallow and simple additional layers on top of pre-trained models during fine-tuning. This work shows that this does not always need to be the case: with proper initialization and optimization, the benefits of very deep transformers can carry over to challenging tasks with small datasets, including Text-to-SQL semantic parsing and logical reading comprehension. In particular, we successfully train $48$ layers of transformers, comprising $24$ fine-tuned layers from pre-trained RoBERTa and $24$ relation-aware layers trained from scratch. With fewer training steps and no task-specific pre-training, we obtain the state-of-the-art performance on the challenging cross-domain Text-to-SQL parsing benchmark Spider. We achieve this by deriving a novel Data-dependent Transformer Fixed-update initialization scheme (DT-Fixup), inspired by the prior T-Fixup work. Further error analysis shows that increasing depth can help improve generalization on small datasets for hard cases that require reasoning and structural understanding.
翻译:人们普遍认为,从零开始培训深变压器需要大量数据集。 因此,对于小型数据集,人们在微调时通常在经过预先训练的模型上使用浅层和简单的额外层。 这项工作表明,这并不一定总是需要做到:如果适当初始化和优化,非常深变压器的好处可以转移到具有挑战性的小型数据集任务,包括文本到SQL的语义解析和逻辑读解理解。特别是,我们成功地培训了48亿美元的变压器层,其中包括预先培训的RoBERTA的24美元微调层和从零开始培训的24美元关系观测层。随着培训步骤的减少和没有具体任务前培训,我们在具有挑战性的跨边际文本到SQL解析基准蜘蛛方面获得了最先进的表现。我们通过在前一个Tix-Fixup工作启发下推出的新型数据依赖变压器固定更新初始化计划(DT-Fixup),我们实现了这一点。 进一步的错误分析表明,增加的深度可以帮助改进小型数据系统对硬案例的简单理解,需要推理和结构。