RoBERTa中文预训练模型:RoBERTa for Chinese

RoBERTa for Chinese, TensorFlow & PyTorch
项目主页:https://github.com/brightmart/roberta_zh
中文预训练RoBERTa模型
RoBERTa是BERT的改进版,通过改进训练任务和数据生成方式、训练更久、使用更大批次、使用更多数据等获得了State of The Art的效果;可以用Bert直接加载。
本项目是用TensorFlow实现了在大规模中文上RoBERTa的预训练,也会提供PyTorch的预训练模型和加载方式。
中文预训练RoBERTa模型-下载
** 推荐 RoBERTa-zh-Large 通过验证**
RoBERTa-zh-Large TensorFlow版本,Bert 直接加载
RoBERTa 24层版训练数据:30G原始文本,近3亿个句子,100亿个中文字(token),产生了2.5亿个训练数据(instance);
覆盖新闻、社区问答、多个百科数据等。
Roberta_l24_zh_base TensorFlow版本,Bert 直接加载
24层base版训练数据:10G文本,包含新闻、社区问答、多个百科数据等。
What is RoBERTa:
A robustly optimized method for pretraining natural language processing (NLP) systems that improves on Bidirectional Encoder Representations from Transformers, or BERT, the self-supervised method released by Google in 2018.
RoBERTa, produces state-of-the-art results on the widely used NLP benchmark, General Language Understanding Evaluation (GLUE). The model delivered state-of-the-art performance on the MNLI, QNLI, RTE, STS-B, and RACE tasks and a sizable performance improvement on the GLUE benchmark. With a score of 88.5, RoBERTa reached the top position on the GLUE leaderboard, matching the performance of the previous leader, XLNet-Large.
(Introduction from Facebook blog)
发布计划 Release Plan:
1、24层RoBERTa模型(roberta_l24_zh),使用30G文件训练, 9月8日
2、12层RoBERTa模型(roberta_l12_zh),使用30G文件训练, 9月8日
3、6层RoBERTa模型(roberta_l6_zh), 使用30G文件训练, 9月8日
4、PyTorch版本的模型(roberta_l6_zh_pytorch) 9月8日
5、30G中文语料,预训练格式,可直接训练(bert,xlent,gpt2) 9月14日或待定
6、测试集测试和效果对比 9月14日
效果测试与对比 Performance
自然语言推断:XNLI
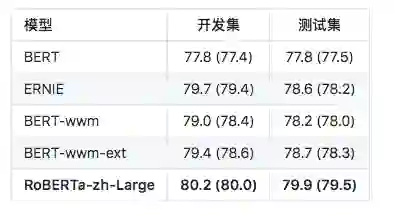
注:RoBERTa_l24_zh,只跑了两次,Performance可能还会提升
Sentence Pair Matching (SPM): LCQMC
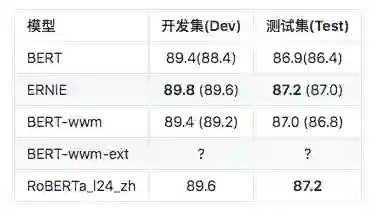
注:RoBERTa_l24_zh,只跑了一次,目前还不是最佳成绩。保存训练轮次和论文一致:
? 处地方,将会很快更新到具体的值
RoBERTa中文版 Chinese Version
本项目所指的中文预训练RoBERTa模型只指按照RoBERTa论文主要精神训练的模型。包括:
1、数据生成方式和任务改进:取消下一个句子预测,并且数据连续从一个文档中获得(见:Model Input Format and Next Sentence Prediction,DOC-SENTENCES)
2、更大更多样性的数据:使用30G中文训练,包含3亿个句子,100亿个字(即token)。由新闻、社区讨论、多个百科,包罗万象,覆盖数十万个主题,
所以数据具有多样性(为了更有多样性,可以可以加入网络书籍、小说、故事类文学、微博等)。
3、训练更久:总共训练了近20万,总共见过近16亿个训练数据(instance); 在Cloud TPU v3-256 上训练了24小时,相当于在TPU v3-8(128G显存)上需要训练一个月。
4、更大批次:使用了超大(8k)的批次batch size。
5、调整优化器等超参数。
除以上外,本项目中文版,使用了全词mask(whole word mask)。在全词Mask中,如果一个完整的词的部分WordPiece子词被mask,则同属该词的其他部分也会被mask,即全词Mask。
本项目中并没有直接实现dynamic mask。通过复制一个训练样本得到多份数据,每份数据使用不同mask,并加大复制的分数,可间接得到dynamic mask效果。
中文全词遮蔽 Whole Word Mask

模型加载(以Sentence Pair Matching即句子对任务,LCQMC为例)
下载LCQMC数据集,包含训练、验证和测试集,训练集包含24万口语化描述的中文句子对,标签为1或0。1为句子语义相似,0为语义不相似。
tensorFlow版本:
1、复制本项目: git clone https://github.com/brightmart/roberta_zh
2、进到项目(roberta_zh)中。
假设你将RoBERTa预训练模型下载并解压到该改项目的roberta_zh_large目录,即roberta_zh/roberta_zh_large
运行命令:
export BERT_BASE_DIR=./roberta_zh_large
export MY_DATA_DIR=./data/lcqmc
python run_classifier.py \
--task_name=lcqmc_pair \
--do_train=true \
--do_eval=true \
--data_dir=$MY_DATA_DIR \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--bert_config_file=$BERT_BASE_DIR/bert_config_large.json \
--init_checkpoint=$BERT_BASE_DIR/roberta_zh_large_model.ckpt \
--max_seq_length=128 \
--train_batch_size=64 \
--learning_rate=2e-5 \
--num_train_epochs=3 \
--output_dir=./checkpoint_lcqmc
注:task_name为lcqmc_pair。这里已经在run_classifier.py中的添加一个processor,并加到processors中,用于指定做lcqmc任务,并加载训练和验证数据。
PyTorch加载方式,先参考issue 9;将很快提供更具体方式。
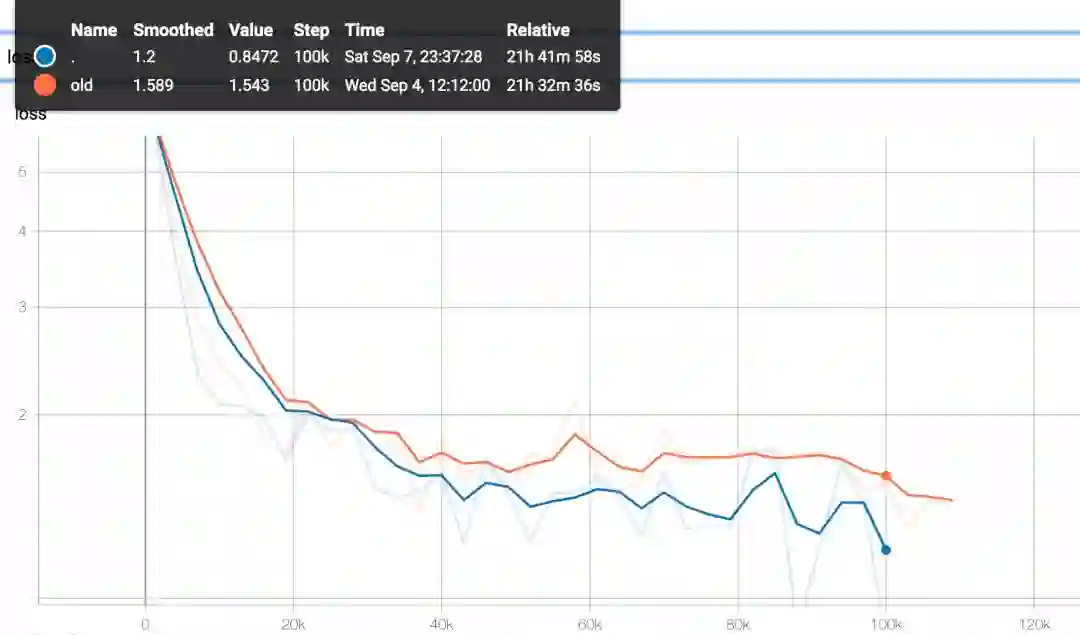
Learning Curve 学习曲线
If you have any question, you can raise an issue, or send me an email: brightmart@hotmail.com
项目贡献者,还包括:
skyhawk1990
本项目受到 TensorFlow Research Cloud (TFRC) 资助 / Project supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC)
Reference
1、RoBERTa: A Robustly Optimized BERT Pretraining Approach
2、Pre-Training with Whole Word Masking for Chinese BERT
3、BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
4、LCQMC: A Large-scale Chinese Question Matching Corpus
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 访问项目主页




