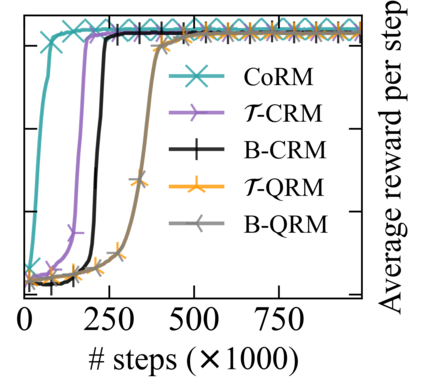
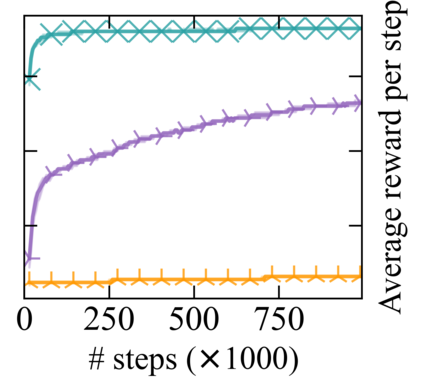
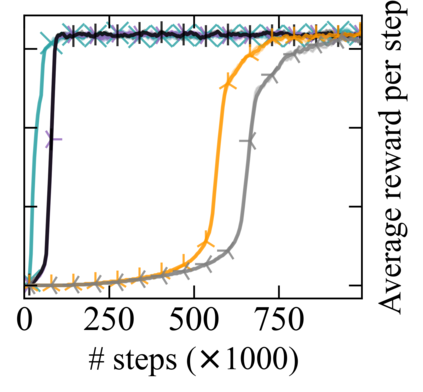
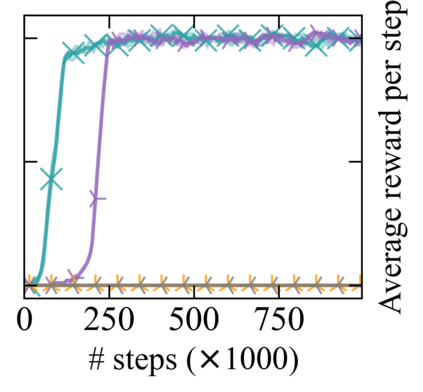
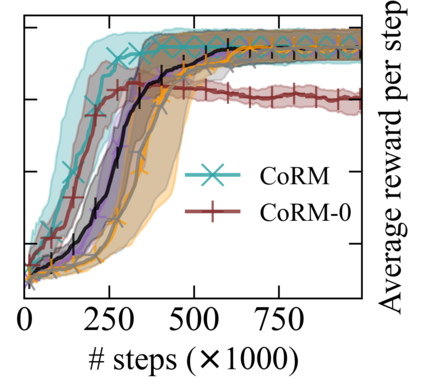
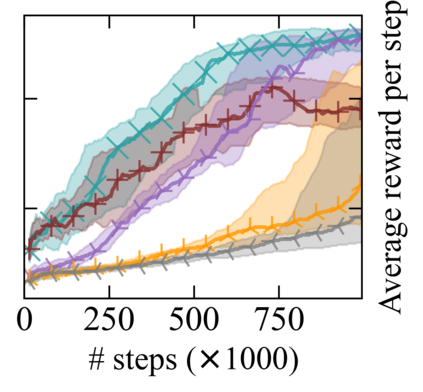
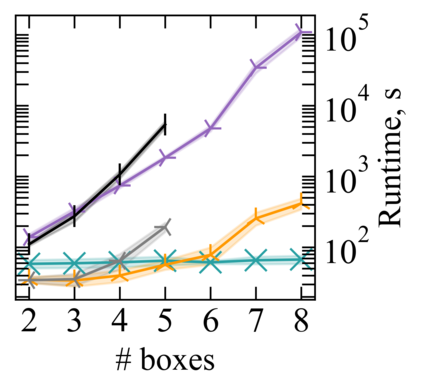
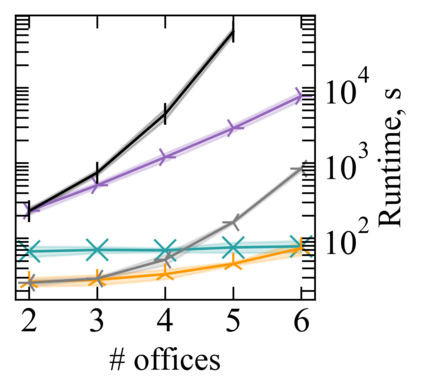
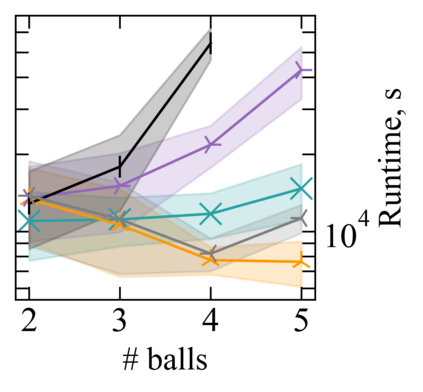
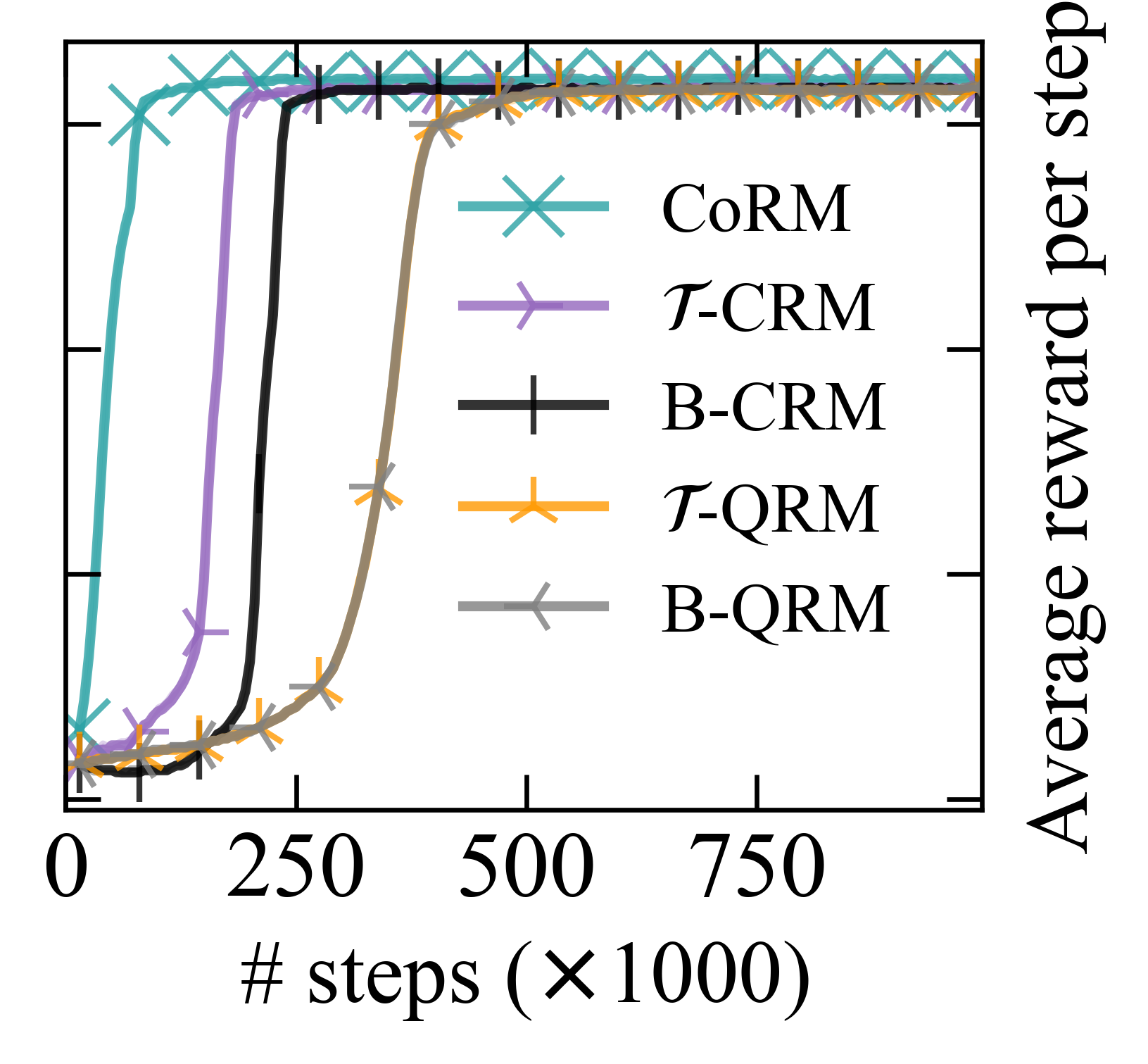
Reward machines (RMs) inform reinforcement learning agents about the reward structure of the environment. This is particularly advantageous for complex non-Markovian tasks because agents with access to RMs can learn more efficiently from fewer samples. However, learning with RMs is ill-suited for long-horizon problems in which a set of subtasks can be executed in any order. In such cases, the amount of information to learn increases exponentially with the number of unordered subtasks. In this work, we address this limitation by introducing three generalisations of RMs: (1) Numeric RMs allow users to express complex tasks in a compact form. (2) In Agenda RMs, states are associated with an agenda that tracks the remaining subtasks to complete. (3) Coupled RMs have coupled states associated with each subtask in the agenda. Furthermore, we introduce a new compositional learning algorithm that leverages coupled RMs: Q-learning with coupled RMs (CoRM). Our experiments show that CoRM scales better than state-of-the-art RM algorithms for long-horizon problems with unordered subtasks.
翻译:暂无翻译