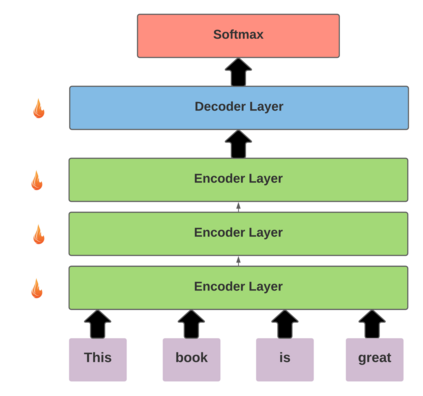
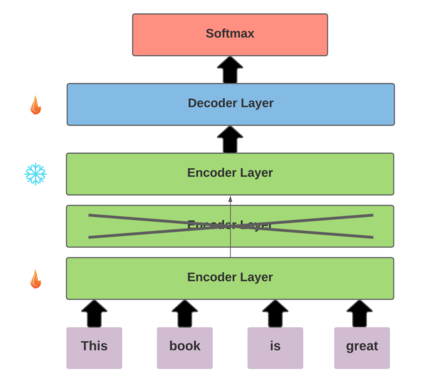
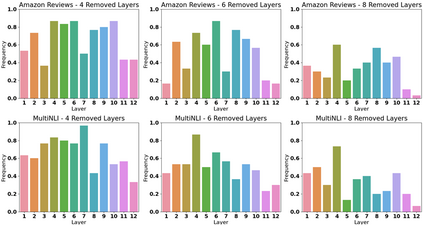
Recent improvements in the predictive quality of natural language processing systems are often dependent on a substantial increase in the number of model parameters. This has led to various attempts of compressing such models, but existing methods have not considered the differences in the predictive power of various model components or in the generalizability of the compressed models. To understand the connection between model compression and out-of-distribution generalization, we define the task of compressing language representation models such that they perform best in a domain adaptation setting. We choose to address this problem from a causal perspective, attempting to estimate the \textit{average treatment effect} (ATE) of a model component, such as a single layer, on the model's predictions. Our proposed ATE-guided Model Compression scheme (AMoC), generates many model candidates, differing by the model components that were removed. Then, we select the best candidate through a stepwise regression model that utilizes the ATE to predict the expected performance on the target domain. AMoC outperforms strong baselines on 46 of 60 domain pairs across two text classification tasks, with an average improvement of more than 3\% in F1 above the strongest baseline.
翻译:最近自然语言处理系统的预测质量的改善往往取决于模型参数数目的大量增加。这导致各种压缩模型的尝试,但现有方法没有考虑到各种模型组成部分的预测力或压缩模型的一般性的差异。为了理解模型压缩和分配外一般化之间的联系,我们界定了压缩语言代表模型的任务,使其在领域适应环境中表现最佳。我们选择从因果角度解决这一问题,试图估计模型预测中诸如单层的模型组成部分的\textit{平均处理效果}(ATE),以估计模型预测中的单层。我们提议的ATE指导模型压缩方案(AMC)产生了许多模型候选人,但因删除模型组成部分而不同。然后,我们通过一个渐进式回归模型选择最佳候选人,利用ATE来预测目标领域的预期业绩。AMC在两个文本分类任务中,在60个域对对应的46个方面,如在两个文本分类任务中,平均改进了F1以上最强基线的3个以上。