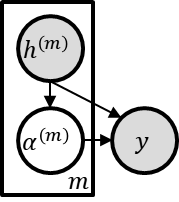
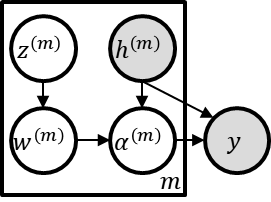
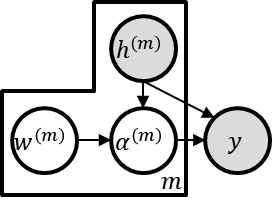
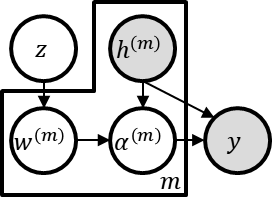
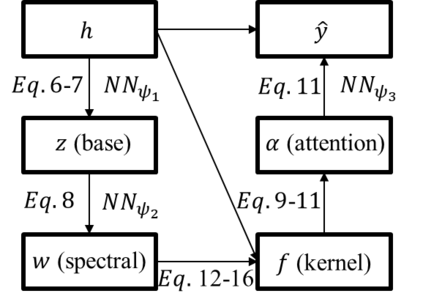
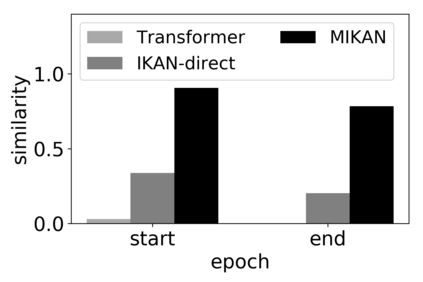
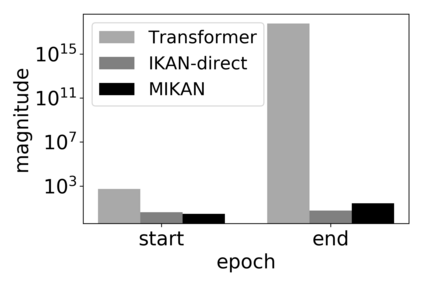
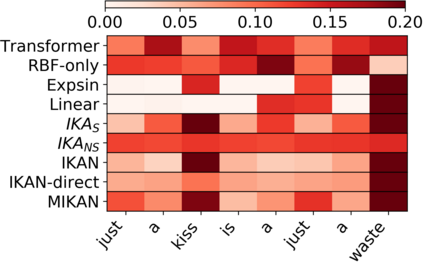
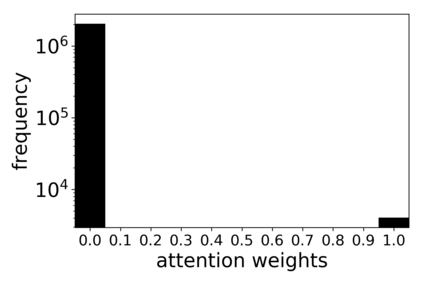
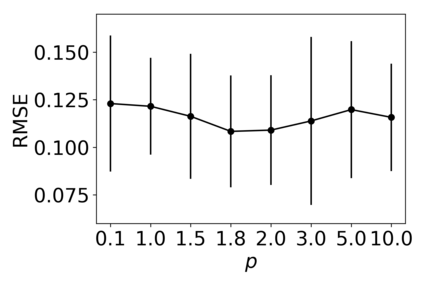
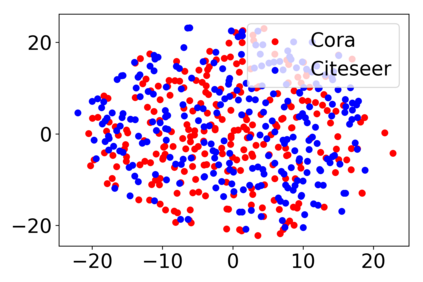
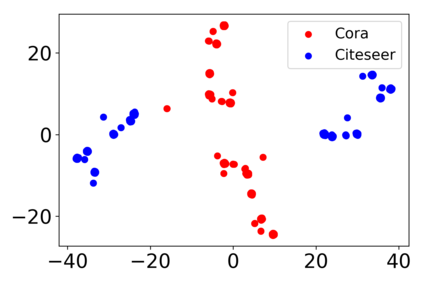
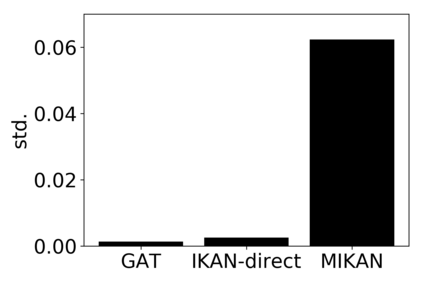
\textit{Attention} computes the dependency between representations, and it encourages the model to focus on the important selective features. Attention-based models, such as Transformer and graph attention network (GAT), are widely utilized for sequential data and graph-structured data. This paper suggests a new interpretation and generalized structure of the attention in Transformer and GAT. For the attention in Transformer and GAT, we derive that the attention is a product of two parts: 1) the RBF kernel to measure the similarity of two instances and 2) the exponential of $L^{2}$ norm to compute the importance of individual instances. From this decomposition, we generalize the attention in three ways. First, we propose implicit kernel attention with an implicit kernel function instead of manual kernel selection. Second, we generalize $L^{2}$ norm as the $L^{p}$ norm. Third, we extend our attention to structured multi-head attention. Our generalized attention shows better performance on classification, translation, and regression tasks.
翻译:\ textit{ 注意} 计算代表之间的依赖性, 它鼓励模型关注重要的选择性特征。 基于关注的模型, 如变换器和图形关注网络( GAT) 被广泛用于顺序数据和图形结构数据 。 本文建议了变换器和GAT 中新的解释和普遍关注结构 。 在变换器和GAT 中, 我们发现注意是两个部分的产物:(1) RBF 用于测量两个实例的相似性;(2) 用于计算单个实例重要性的 $L ⁇ 2} 标准指数。 从这种分解中, 我们以三种方式将注意力普遍化。 首先, 我们提出隐含内核功能而非人工内核选择的隐含内核关注。 其次, 我们将$L2} 标准作为 $L ⁇ p} 规范加以推广。 第三, 我们把注意力扩大到结构化的多头关注。 我们的普遍关注显示在分类、 翻译和回归任务上表现得更好。