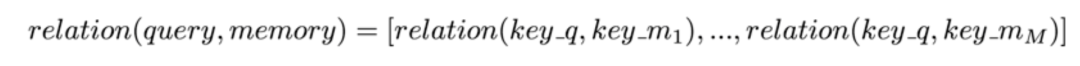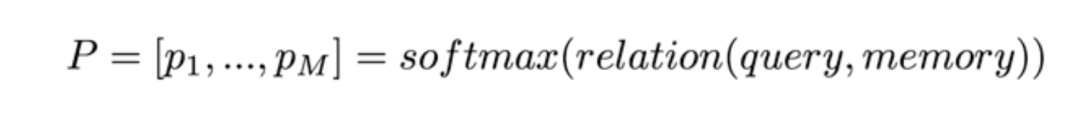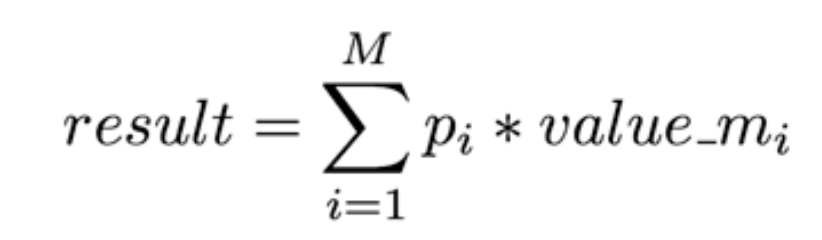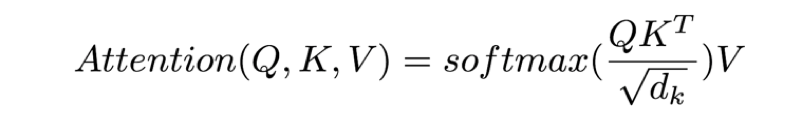![]()
最近打算好好整理下
Attention在深度推荐系统中的应用
,所以就写了这关于Attention的先导篇,Attention自2015年ICLR 《Neural machine translation by jointly learning to align and translate》被提出后,在 NLP 领域,图像领域遍地开花。Attention 到底有什么特别之处?他的原理和本质是什么?是否可以用统一框架进行理解?如何理解Attention的各种变体?
Attention 的本质是什么
Attention机制源自于人类视觉注意力机制:将有限的注意力集中在重点信息上,「从关注全部到关注重点」,从而节省资源,快速获得最有效的信息。对于Attention而言,就是一种权重参数的分配机制,目标是协助模型捕捉重要信息,“带权求和”就可以高度概括,在不同的 context 下,focusing 不同的信息。在很多的应用场景,attention肩负起了部分 feature-selection,featue-representation 的责任。
Attention 的原理
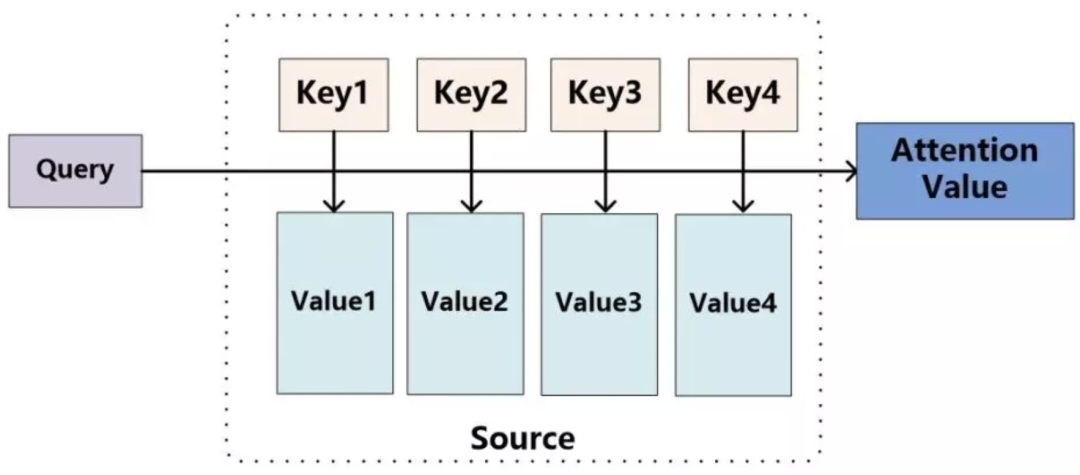
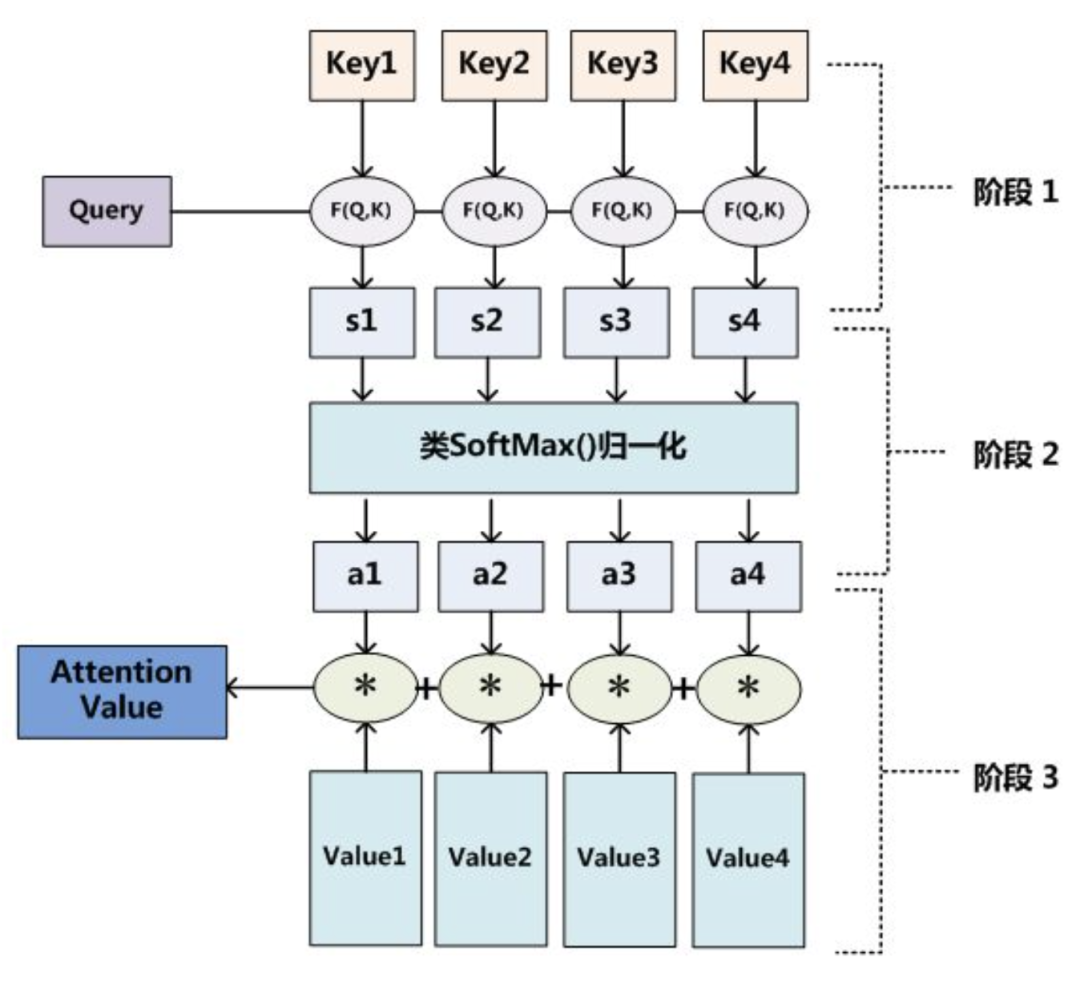
可以将attention机制看做一种query机制,即用一个query来检索一个memory区域。我们将query表示为key_q,memory是一个键值对集合(a set of key-value pairs),共有M项,其中的第i项我们表示为<key_m[i], value_m[i]>。通过计算query和key_m[i]的相关度,来决定查询结果中,value_m[i]所占的权重比例。注意,这里的key_q,key_m,value_m都是vector。因此
Attention函数的本质可以被描述为
一个查询(query)到一系列(键key-值value)对的映射
,如下图。
![]()
score function :度量环境向量(memory)与当前输入向量(query)的相似性;找到当前环境下,应该 focus 哪些输入信息;![]()
alignment function :计算 attention weight,通常都使用 softmax 进行归一化;
![]()
context vector function :根据 attention weight,对所有value进行加权平均得到输出向量;
![]()
![]()
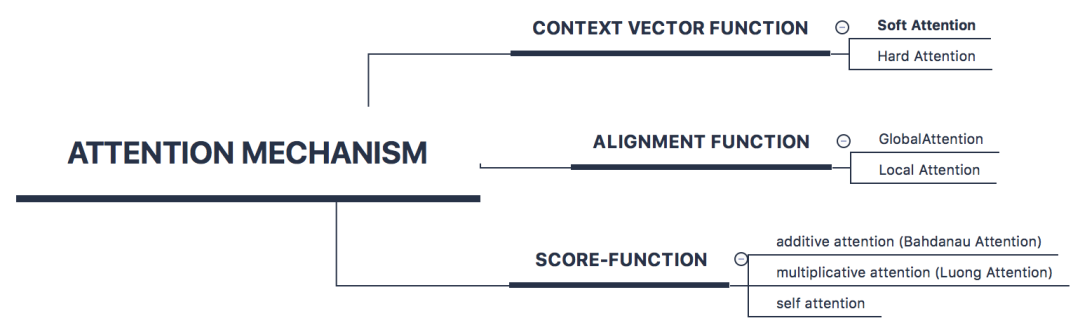
Attention 的常见类型
![]()
Attention的类型通常围绕score function 、alignment function 、context vector function,这三者之间的变化展开:
如何生成输出向量,有上面提及的那些变换。接下来是变化更加丰富的 score function。最为常用的 score function 有上文图中的那几种(基本全乎了吧)。其实本质就是度量两个向量的相似度。如果两个向量在同一个空间,那么可以使用 dot 点乘方式(或者 scaled dot product,scaled 背后的原因是为了减小数值,softmax 的梯度大一些,学得更快一些),简单好使。如果不在同一个空间,需要一些变换(在一个空间也可以变换),additive 对输入分别进行线性变换后然后相加,multiplicative 是直接通过矩阵乘法来变换(你是不是也曾迷惑过为什么attention 要叫做 additive 和 multiplicative attention?)。
2. alignment function — global/local attention
直观理解就是带权求和的集合不一样,global attention 是所有输入向量作为加权集合,使用 softmax 作为 alignment function,local 是部分输入向量才能进入这个池子。为什么用 local,背后逻辑是要减小噪音,进一步缩小重点关注区域。接下来的问题就是,怎么确定这个 local 范围?文中提了两个方案 local-m 和 local-p。local-m 基于的假设生硬简单,就直接 pass了。local-p 有一个预估操作,预计当前时刻应该关注输入序列(总长度为S)的什么位置 pt(引入了两个参数向量,vp,wp),然后在 alignment function 中做了一点儿调整,在 softmax 算出来的attention wieght 的基础上,加了一个以 pt 为中心的高斯分布来调整 alignment 的结果。
作者最后阐述 local-p + general(score-function 参考上图中multiplicative attention 中的 general 版本)的方式效果是最好的。但从global/local 视角的分类来看,更常用的依然还是 global attention,因为复杂化的local attention 带来的效果增益感觉并不大。
3. context vector function — hard / soft attention
hard attention 是一个随机采样,采样集合是输入向量的集合,采样的概率分布是alignment function 产出的 attention weight。因此,hard attention 的输出是某一个特定的输入向量。soft attention 是一个带权求和的过程,求和集合是输入向量的集合,对应权重是 alignment function 产出的 attention weight。hard / soft attention 中,soft attention 是更常用的(后文提及的所有 attention 都在这个范畴),因为它可导,可直接嵌入到模型中进行训练。
Attention举例:Bahdanau Attention & Luong Attention
下面列出两者的对比图:
![]()
Attention举例: self-Attention
在上文Attention的常见类型下,这里着重介绍self-attention。一般情况Q,K,V中Q 和 K是不一致的,而Self-Attention顾名思义,每个词汇以自己的embedding为query,查询由所有词汇的embedding构成的memory空间,得到查询结果作为本词的表示。假如句子长度为n,所有的词分别查询一遍memory得到的结果长度依然会是n。。
![]()
可视化Self-Attention实例
在图8中我们展示了可视化后的Self-Attention机制,Self-Attention可以捕获同一个句子中单词之间的一些句法特征或者语义特征。上图展示了Self-Attention捕获了同一个句子中单词之间的语义特征,“it”的指代对象是“the animal”。
Self-Attention方法中,句子中的每个词都能与句子中任意距离的其他词建立一个敏感的关系,所以远距离依赖特征之间的距离被极大缩短,有利于有效地利用这些特征。并且,Self-Attention对于增加计算的并行性也有直接帮助作用。所以,这也是Self-Attention逐渐被广泛使用的主要原因。
Self-attention In Transform
首先,还是来讲一下Transformer中的self-attention机制。上面讲到了self-attention的基本形式,但是Transformer里面的self-attention机制是一种新的变种,体现在两点,一方面是加了一个缩放因子(scaling factor),另一方面是引入了多头机制(multi-head attention)。
缩放因子体现在Attention的计算公式中多了一个向量的维度作为分母,目的是想避免维度过大导致的点乘结果过大,进入softmax函数的饱和域,引起梯度过小。Transformer中的self-attention计算公式如下:
多头机制是指,引入多组的参数矩阵来分别对Q、K、V进行线性变换求self-attention的结果,然后将所有的结果拼接起来作为最后的self-attention输出。这样描述可能不太好理解,一看公式和示意图就会明白了,如下:
这种方式使得模型具有多套比较独立的attention参数,理论上可以增强模型的能力。
Attention 的优点
attention 机制具有如下优点:
-
一步到位的全局联系捕捉,且关注了元素的局部联系;attention 函数在计算 attention value 时,是进行序列的每一个元素和其它元素的对比,在这个过程中每一个元素间的距离都是一;而在时间序列 RNNs 中,元素的值是通过一步步递推得到的长期依赖关系获取的,而越长的序列捕捉长期依赖关系的能力就会越弱。
-
并行计算减少模型训练时间;Attention 机制每一步的计算都不依赖于上一步的计算结果,因此可以并行处理。
-
但 attention 机制的缺点也比较明显,因为是对序列的所有元素并行处理的,所以无法考虑输入序列的元素顺序。
总结
简而言之,Attention 机制就是对输入的每个元素考虑不同的权重参数,从而更加关注与输入的元素相似的部分,而抑制其它无用的信息。其最大的优势就是能一步到位的考虑全局联系和局部联系,且能并行化计算,这在大数据的环境下尤为重要。同时,我们需要注意的是 Attention 机制作为一种思想,并不是只能依附在 Encoder-Decoder 框架下的,而是可以根据实际情况和多种模型进行结合。
推荐阅读
深度总结 | 知识蒸馏在推荐系统中的应用
模型工程化部署方式总结
炼丹手册 | 神经网络训练tricks总结
你点的每个好看,我都认真当成了喜欢![]()