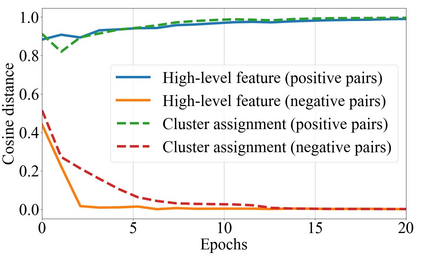
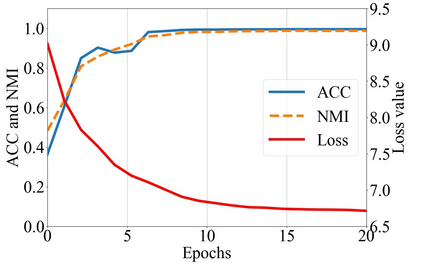
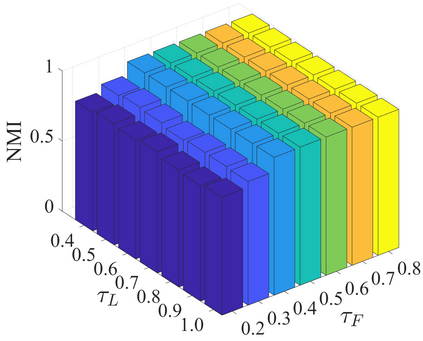
Multi-modal clustering, which explores complementary information from multiple modalities or views, has attracted people's increasing attentions. However, existing works rarely focus on extracting high-level semantic information of multiple modalities for clustering. In this paper, we propose Contrastive Multi-Modal Clustering (CMMC) which can mine high-level semantic information via contrastive learning. Concretely, our framework consists of three parts. (1) Multiple autoencoders are optimized to maintain each modality's diversity to learn complementary information. (2) A feature contrastive module is proposed to learn common high-level semantic features from different modalities. (3) A label contrastive module aims to learn consistent cluster assignments for all modalities. By the proposed multi-modal contrastive learning, the mutual information of high-level features is maximized, while the diversity of the low-level latent features is maintained. In addition, to utilize the learned high-level semantic features, we further generate pseudo labels by solving a maximum matching problem to fine-tune the cluster assignments. Extensive experiments demonstrate that CMMC has good scalability and outperforms state-of-the-art multi-modal clustering methods.
翻译:多模式集群探索多种模式或观点的补充信息,吸引了人们越来越多的注意力;然而,现有工作很少侧重于提取关于多种组合模式的高层次语义信息;在本文件中,我们提议通过对比性学习,对高层次语义信息进行反向多式组合(CMMC),通过高层次语义信息进行开采;具体地说,我们的框架由三个部分组成:(1) 多自动分类器得到优化,以保持每种模式的多样性,从而学习补充信息;(2) 提出一个特征对比性模块,以学习不同模式的共同高层次语义特征;(3) 标签对比性模块,旨在学习所有模式的一致集群任务;通过拟议的多模式对比性学习,高层次特征的相互信息得到最大化,同时保持低层次潜在特征的多样性;此外,为了利用学到的高层次语义特征,我们还通过解决最大程度的匹配问题来改进集群任务,产生假标签。