【AAAI2021】对比聚类,Contrastive Clustering
背景:现有的大部分深度聚类(Deep Clustering)算法需要迭代进行表示学习和聚类这两个过程,利用聚类结果来优化表示,再对更优的表示进行聚类,此类方法主要存在以下两个缺陷,一是迭代优化的过程中容易出现误差累计,二是聚类过程通常采用k-means等需要全局相似性信息的算法,使得需要数据全部准备好后才能进行聚类,故面临不能处理在线数据的局限性。针对上述问题,本文提出了一种基于对比学习的聚类算法,其同时进行表示学习和聚类分析,且能实现流式数据的聚类。
方法:本文基于“标签即表示”的思想[2],将聚类任务统一到表示学习框架下,对每个样本学习其聚类软标签作为特征表示。具体地,我们在国际上首次揭示数据特征矩阵的行和列事实上分别对应实例和类别的表示(图1)。也即,特征矩阵的列是一种特殊的类别表示,其对应某一实例属于某一类别的概率。基于该洞见,本文提出同时在特征矩阵的行空间与列空间,即实例级别和类别级别,进行对比学习即可进行聚类。
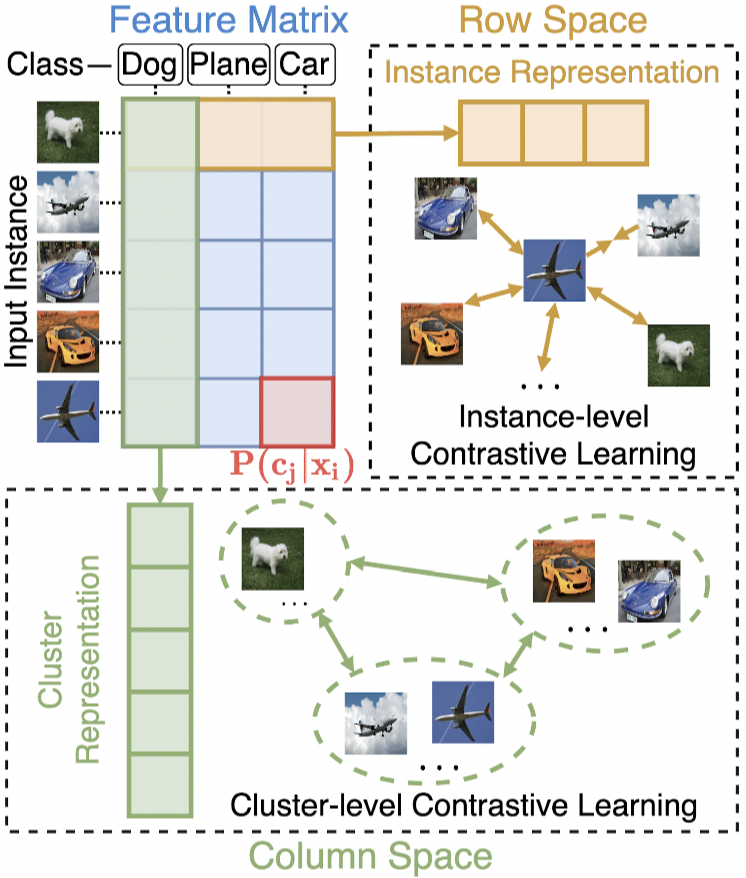
图1 特征矩阵的行、列空间分别对应实例和类别的表示,可在其中分别进行实例和类别级别的表示学习来进行聚类
我们的方法如图2所示,首先利用数据增广构造用于对比学习的正负样本对,通过骨干网络提取特征,并分别投影到行、列空间进行实例和类别级别的对比学习。训练完成后,通过直接计算各个样本的软标签,取最大概率的类别作为预测结果即可实现聚类。显然,该方法适用于大规模在线的数据,因为其将聚类过程转化为表示学习过程。
创新:一方面,从聚类的角度,受益于“标签即表示”及“列空间对应类别表示空间”的洞见,本文提出的方法无需所有数据输入后才能进行聚类,而是采用在线的方式实时对当前数据进行聚类隶属预测,适用于大规模在线场景和流式数据处理。大量实验表明,提出的方法在CIFAR10,CIFAR100等数据集上比当时最优聚类算法提升精度30%以上。另一方面,从对比学习角度,该工作是最早的面向任务的对比学习方法,而不再是流行的任务无关无监督表示学习范式。此外,本文提出的算法也可认为是一种新的引入聚类性质从而增强表示学习能力的对比学习方法,为对比学习研究领域引入新的洞见。本文的整个idea非常优雅、简洁及自洽。相对于最新的SimCLR等对比学习算法,本文提出的算法仅需在考虑数据特征行空间对比学习的同时再考虑列空间的对比学习即可。
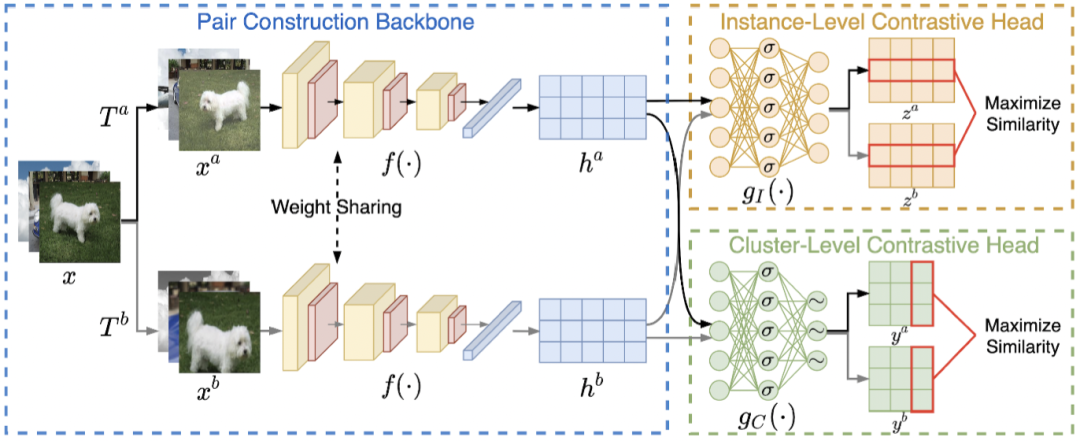
图2 网络结构
结果:为验证方法的有效性,我们在6个常用图片数据集上对比了17种代表性的聚类算法(图3)。实验结果表明,本文提出的方法在3个通用聚类指标NMI(标准化互信息),ACC(准确率),ARI(调兰德指数)上均取得了最优。特别地,本方法在CIFAR-10数据集上相比当前最优方法取得了39%的NMI提升,在CIFAR-100和Tiny-ImageNet数据集上相比当前方法取得了超过50%的ARI提升,充分验证了本方法的有效性。
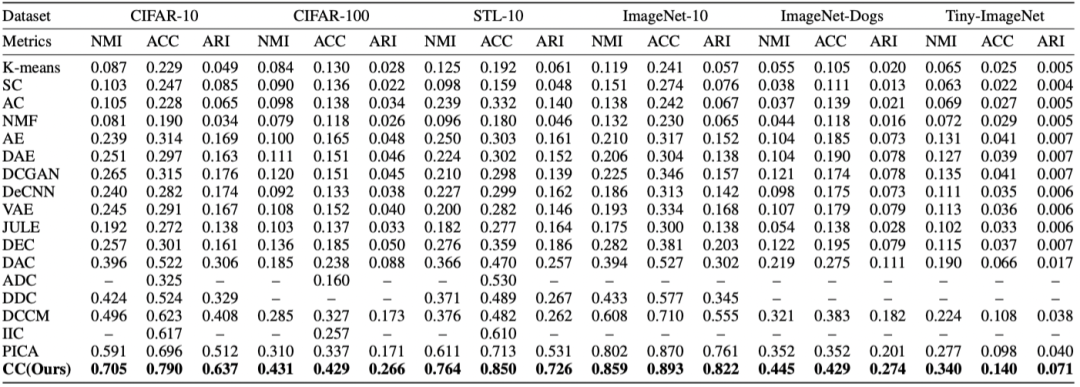
图3 实验结果
https://www.zhuanzhi.ai/paper/a039c5d3a74350accaa6676994c0adbb
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“CC2021” 可以获取《【AAAI2021】对比聚类,Contrastive Clustering》专知下载链接索引






