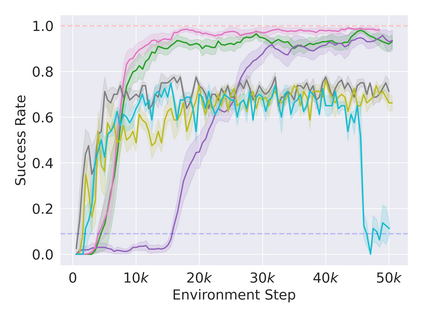
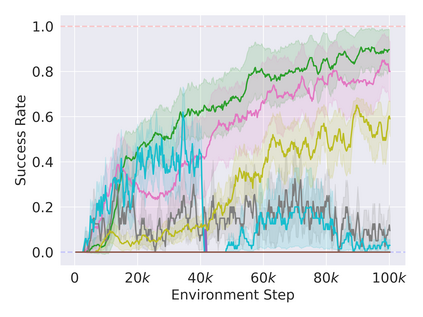
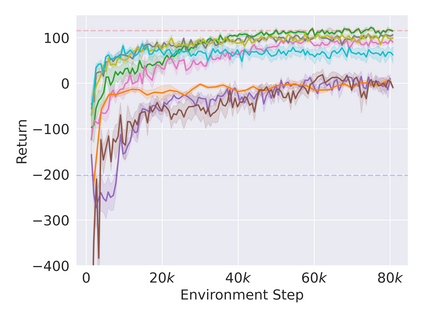
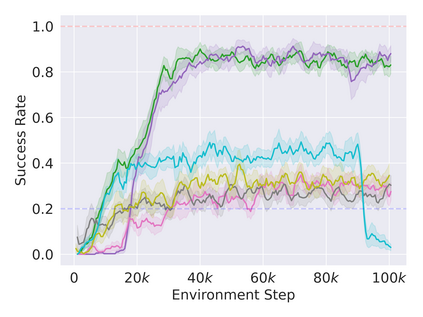
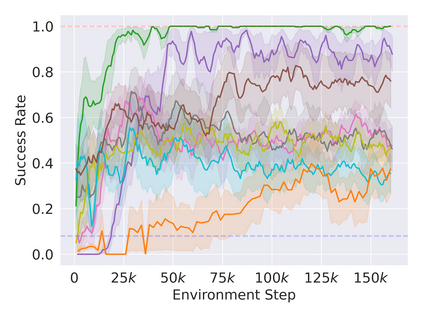
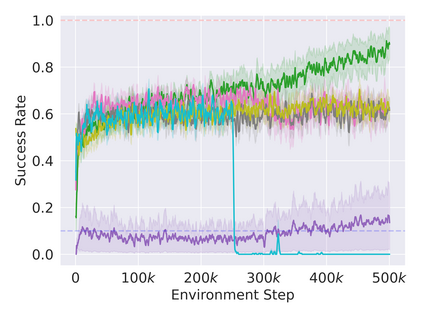
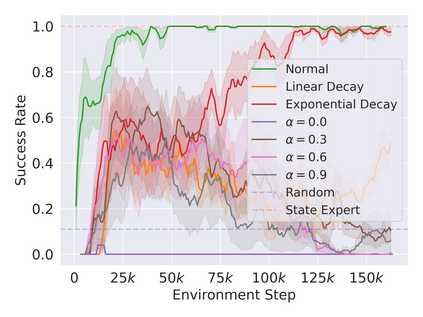
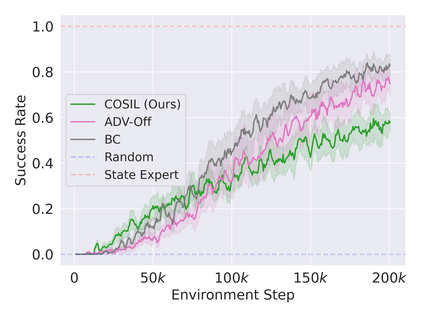
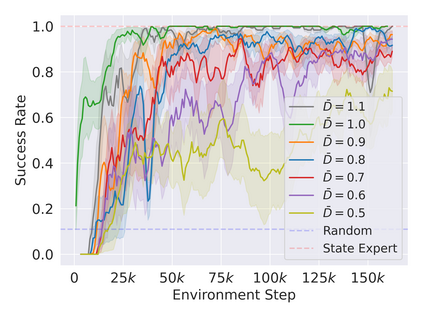
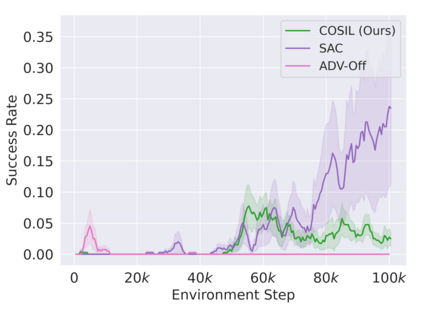
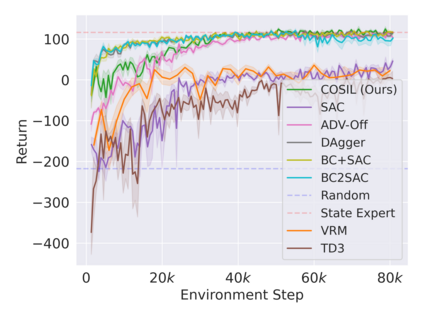
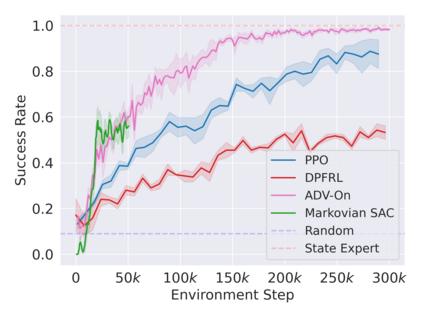
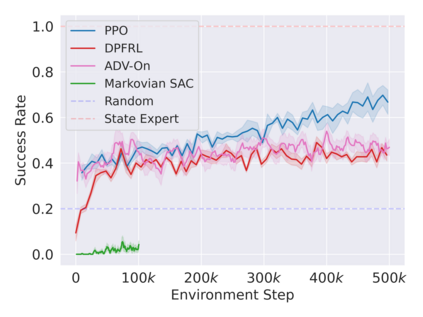
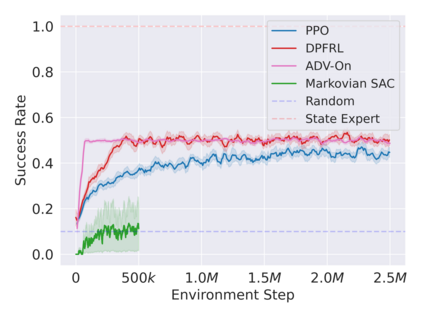
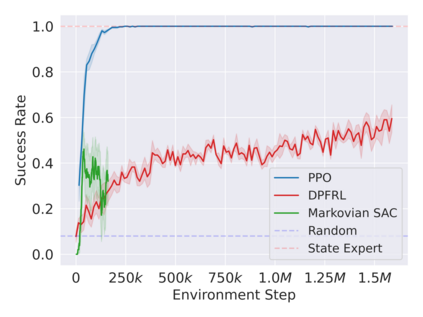
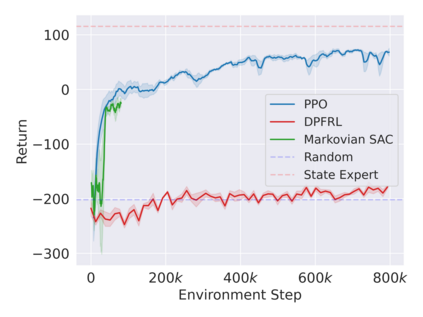
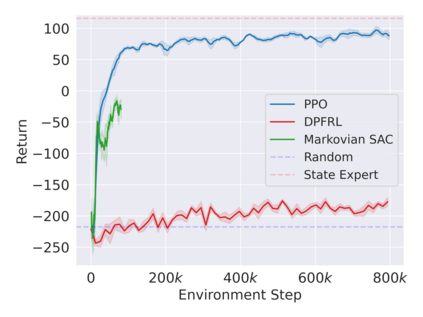
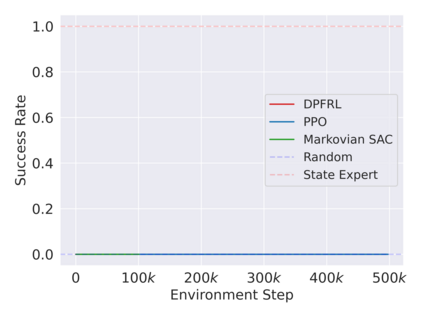
Reinforcement learning in partially observable domains is challenging due to the lack of observable state information. Thankfully, learning offline in a simulator with such state information is often possible. In particular, we propose a method for partially observable reinforcement learning that uses a fully observable policy (which we call a state expert) during offline training to improve online performance. Based on Soft Actor-Critic (SAC), our agent balances performing actions similar to the state expert and getting high returns under partial observability. Our approach can leverage the fully-observable policy for exploration and parts of the domain that are fully observable while still being able to learn under partial observability. On six robotics domains, our method outperforms pure imitation, pure reinforcement learning, the sequential or parallel combination of both types, and a recent state-of-the-art method in the same setting. A successful policy transfer to a physical robot in a manipulation task from pixels shows our approach's practicality in learning interesting policies under partial observability.
翻译:由于缺乏可见状态信息,在部分可观测的领域中强化学习具有挑战性。 值得庆幸的是,在模拟器中以这种状态信息进行离线学习往往是可能的。 特别是,我们提出了一种在离线培训中使用完全可见的政策(我们称之为州专家)来提高在线绩效的半可见强化学习方法。 基于软动作- critic (SAC), 我们的代理方平衡了与州专家相似的行动和在部分可观测性下获得高回报。 我们的方法可以利用完全可观测的勘探政策和部分领域完全可观测但仍在部分可观测条件下学习的部分内容。 在六个机器人领域,我们的方法超越了纯仿造、纯强化学习、两种类型相继或平行的组合,以及在同一环境中的一种最新的最新状态方法。 从像素中成功地将政策转移到一个操作任务中的物理机器人,表明了我们的方法在学习部分可观测性政策方面的实际意义。