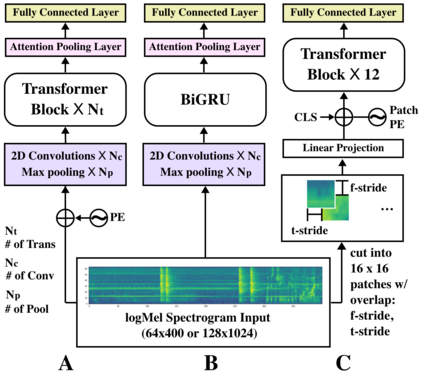
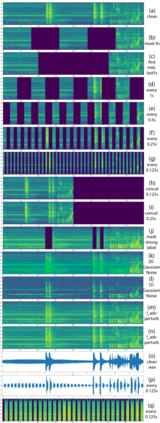
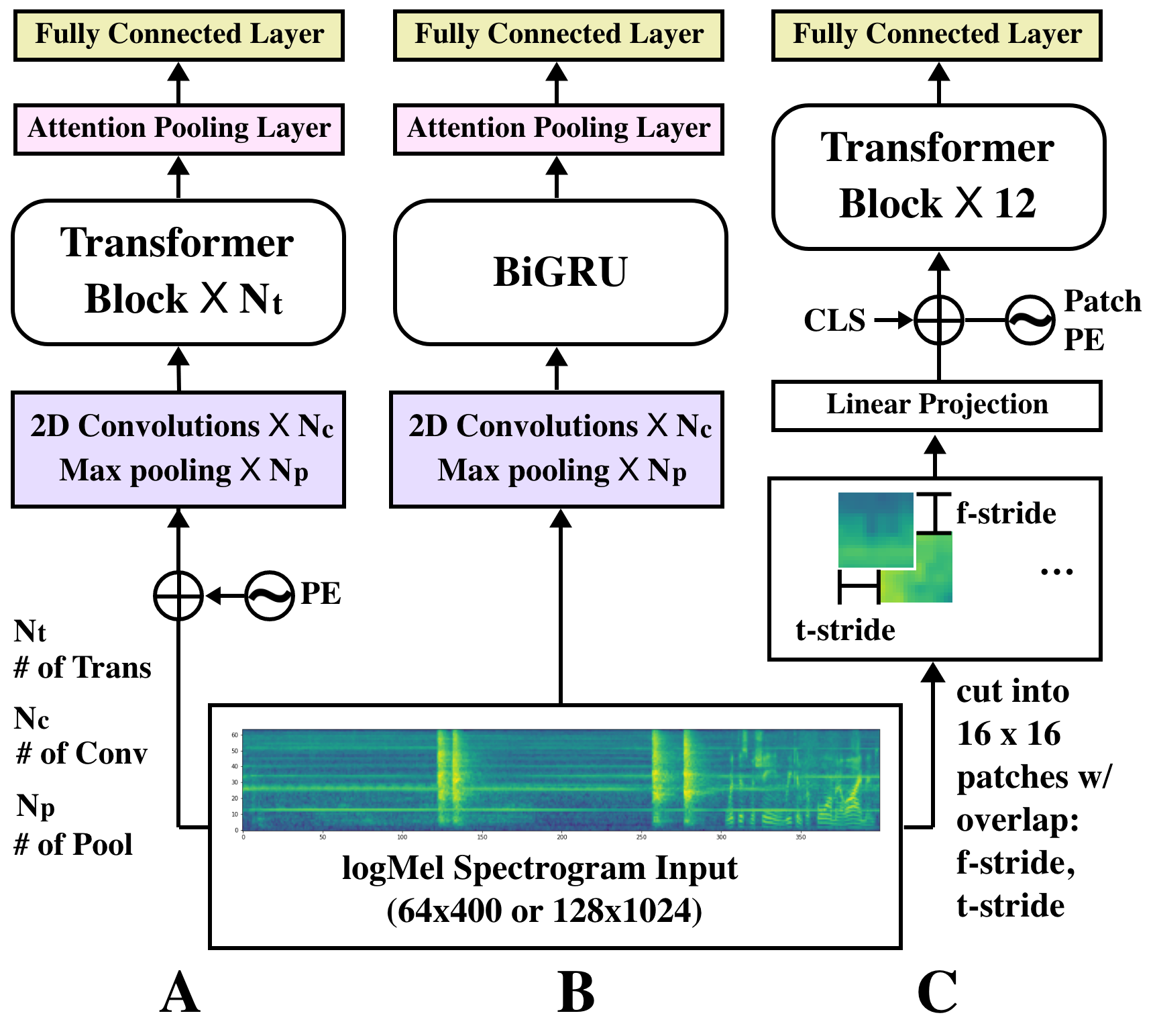
Traditionally, in Audio Recognition pipeline, noise is suppressed by the "frontend", relying on preprocessing techniques such as speech enhancement. However, it is not guaranteed that noise will not cascade into downstream pipelines. To understand the actual influence of noise on the entire audio pipeline, in this paper, we directly investigate the impact of noise on a different types of neural models without the preprocessing step. We measure the recognition performances of 4 different neural network models on the task of environment sound classification under the 3 types of noises: \emph{occlusion} (to emulate intermittent noise), \emph{Gaussian} noise (models continuous noise), and \emph{adversarial perturbations} (worst case scenario). Our intuition is that the different ways in which these models process their input (i.e. CNNs have strong locality inductive biases, which Transformers do not have) should lead to observable differences in performance and/ or robustness, an understanding of which will enable further improvements. We perform extensive experiments on AudioSet which is the largest weakly-labeled sound event dataset available. We also seek to explain the behaviors of different models through output distribution change and weight visualization.
翻译:在传统意义上,在音频识别管道中,噪音被“前端”抑制,依靠语音增强等预处理技术。然而,不能保证噪音不会扩散到下游管道。为了了解噪音对整个音频管道的实际影响,我们在本文件中直接调查噪音对不同类型神经模型的影响,而没有预处理步骤。我们测量四个不同的神经网络模型在三类噪音类型下的环境无害分类任务方面的认知性能: \emph{clusion} (模仿间歇噪音)、 emph{Gausian} 噪音(模型连续噪音)和\emph{对抗性扰动} (最糟糕的情况假设)。我们的直觉是,这些模型处理其输入的不同方式(即CNN具有强烈的感应偏差,而变换者没有这种偏差)应该导致在性能和/或稳健度方面的可见差异,从而可以进一步改进。我们对音频Set进行了广泛的实验,这是最大的微标签事件变音频重模型,我们还寻求通过可视的输出方式解释不同的行为。