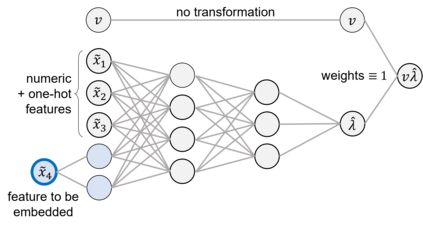
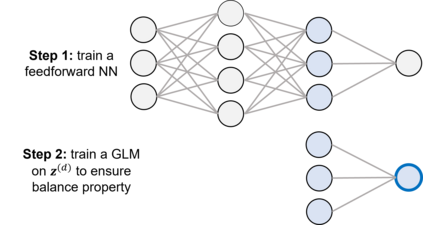
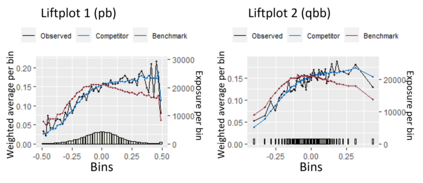
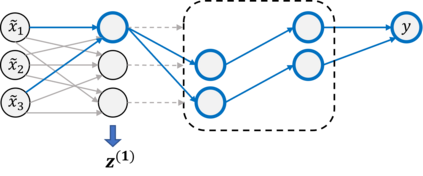
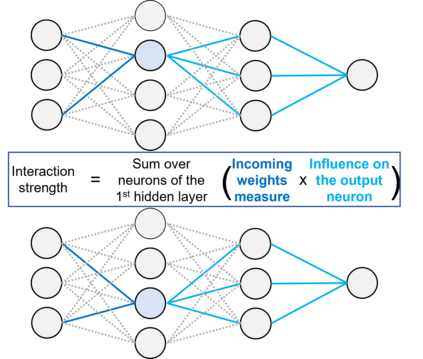
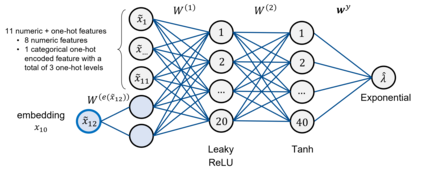
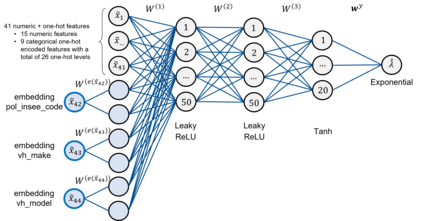
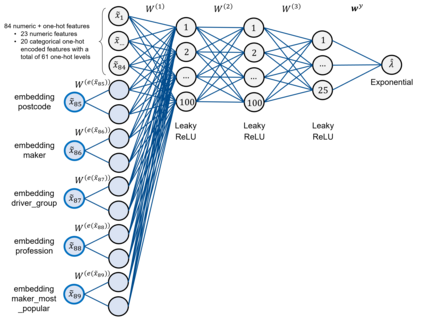
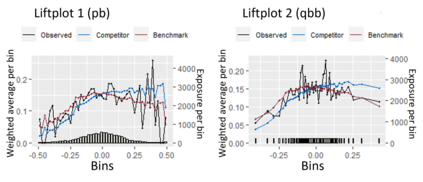
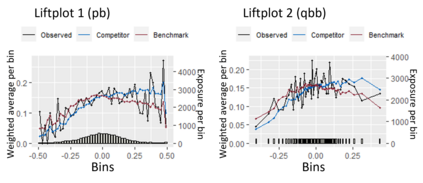
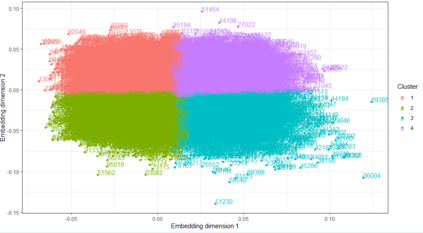
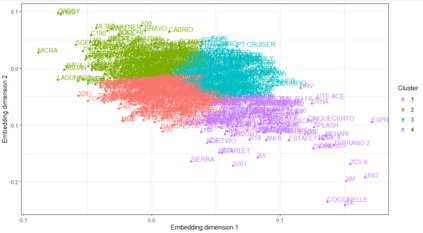
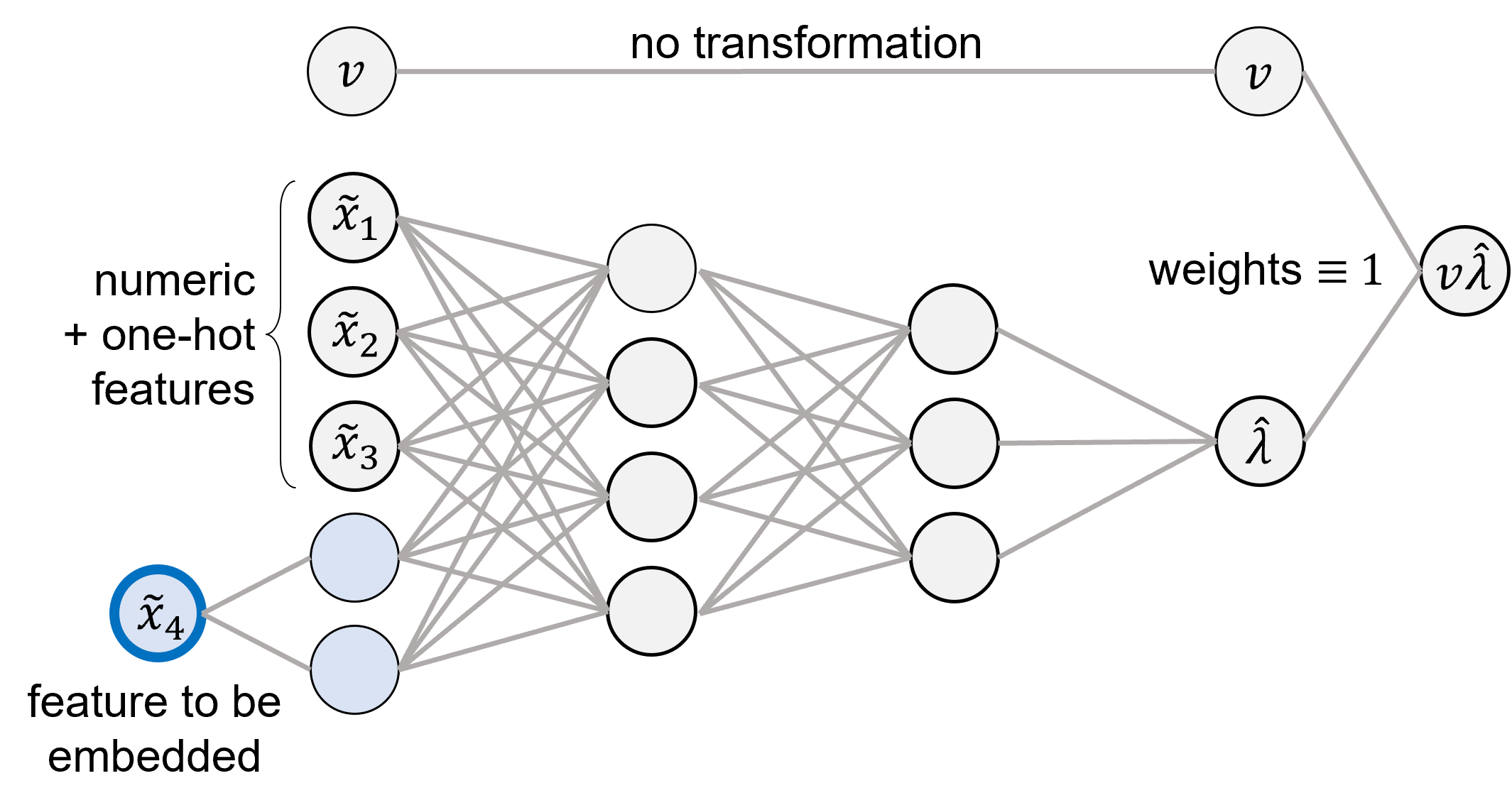
The quality of generalized linear models (GLMs), frequently used by insurance companies, depends on the choice of interacting variables. The search for interactions is time-consuming, especially for data sets with a large number of variables, depends much on expert judgement of actuaries, and often relies on visual performance indicators. Therefore, we present an approach to automating the process of finding interactions that should be added to GLMs to improve their predictive power. Our approach relies on neural networks and a model-specific interaction detection method, which is computationally faster than the traditionally used methods like Friedman H-Statistic or SHAP values. In numerical studies, we provide the results of our approach on different data sets: open-source data, artificial data, and proprietary data.
翻译:保险公司经常使用的通用线性模型(GLM)的质量取决于互动变量的选择。寻找互动需要时间,对于具有大量变量的数据集来说尤其如此,这在很大程度上取决于精算师的专家判断,而且往往依赖视觉性能指标。因此,我们提出了一个方法,将寻找互动的过程自动化,在GLM中增加这些互动,以提高其预测力。我们的方法依靠的是神经网络和模型特有的互动检测方法,该方法的计算速度比Friedman H-Statistic 或 SHAP 等传统使用的方法要快。在数字研究中,我们提供了关于不同数据集的方法的结果:公开源数据、人工数据和专有数据。