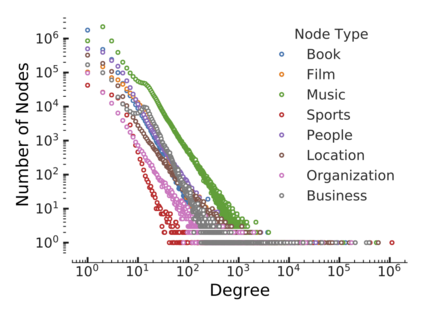
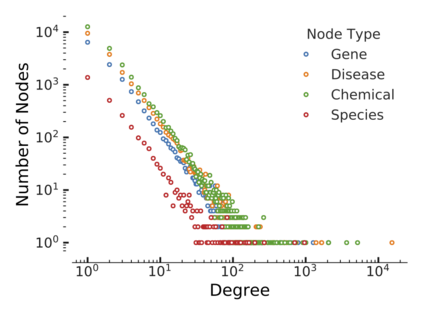
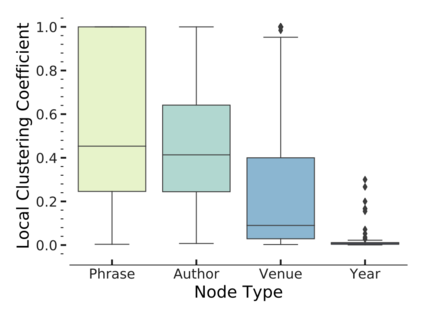
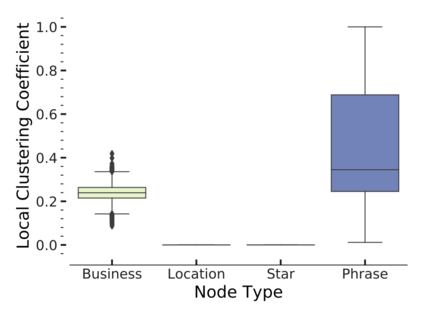
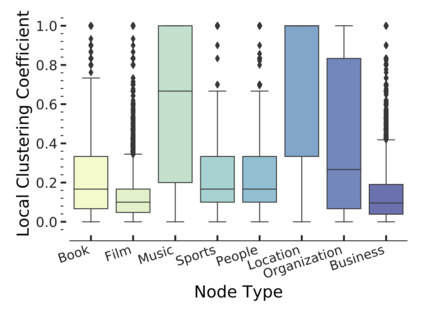
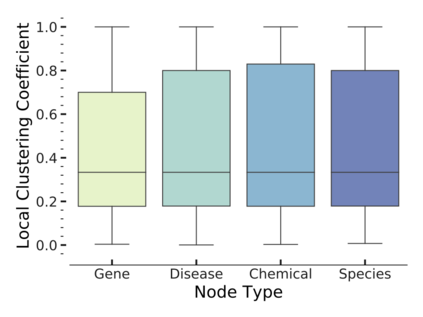
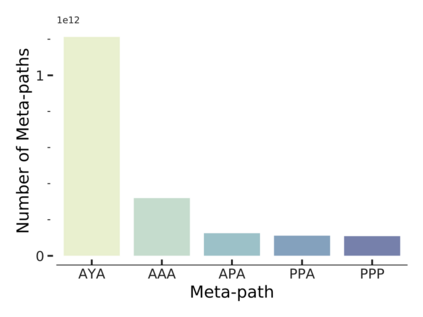
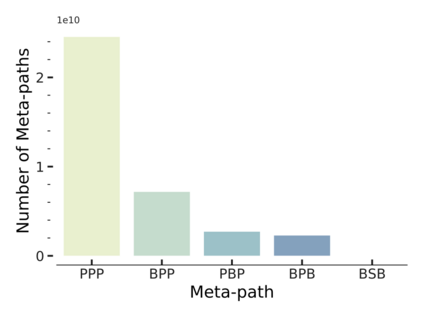
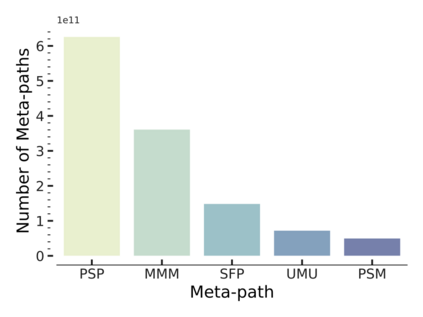
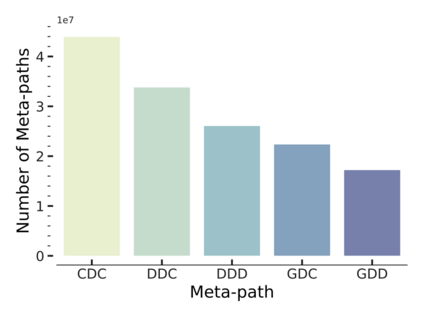
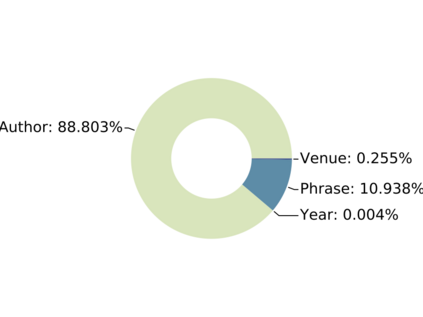
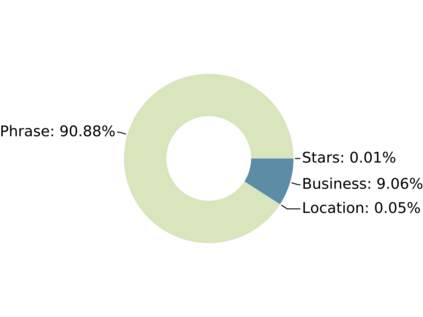
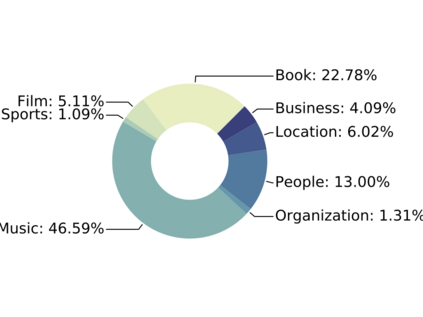
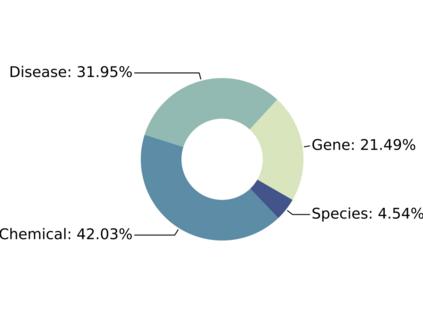
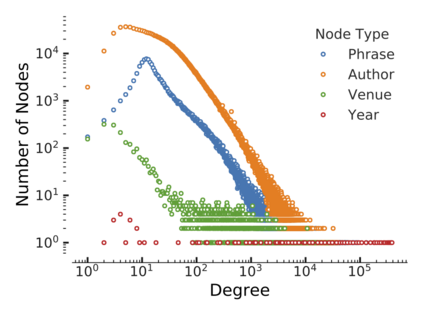
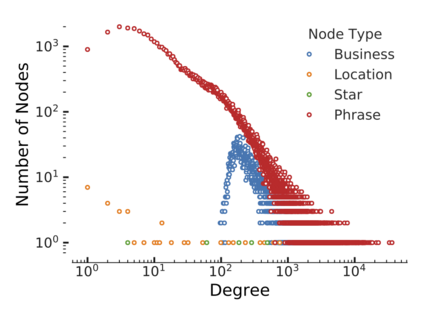
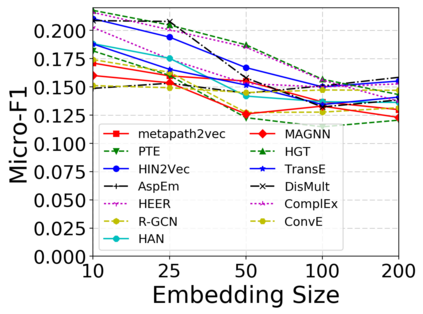
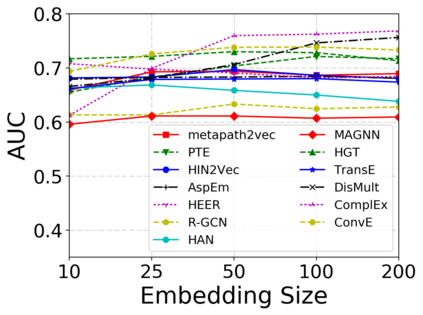
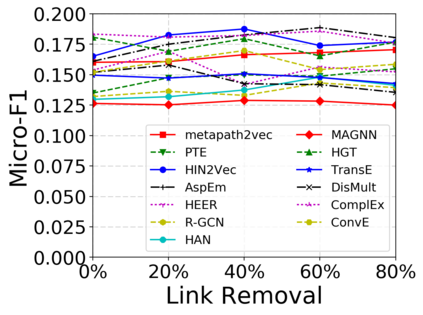
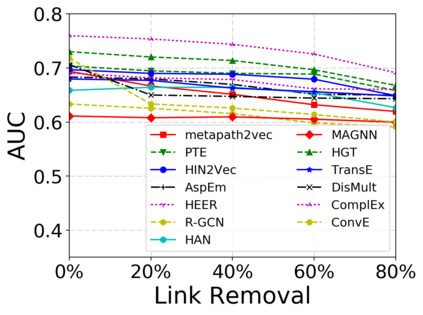
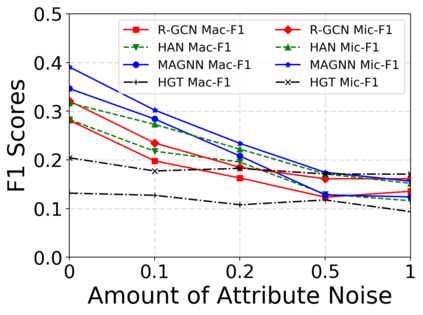
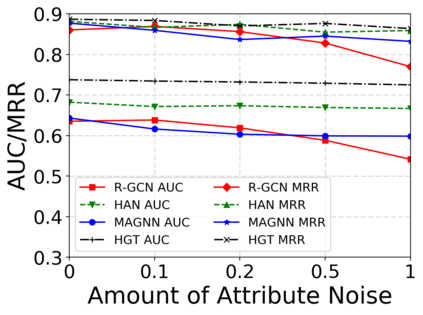
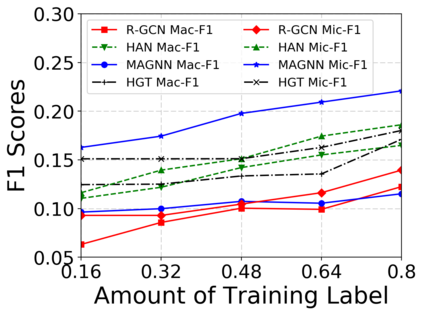
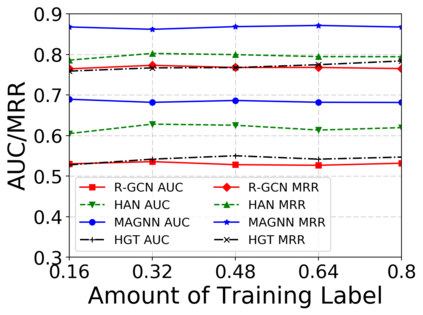
Since real-world objects and their interactions are often multi-modal and multi-typed, heterogeneous networks have been widely used as a more powerful, realistic, and generic superclass of traditional homogeneous networks (graphs). Meanwhile, representation learning (\aka~embedding) has recently been intensively studied and shown effective for various network mining and analytical tasks. In this work, we aim to provide a unified framework to deeply summarize and evaluate existing research on heterogeneous network embedding (HNE), which includes but goes beyond a normal survey. Since there has already been a broad body of HNE algorithms, as the first contribution of this work, we provide a generic paradigm for the systematic categorization and analysis over the merits of various existing HNE algorithms. Moreover, existing HNE algorithms, though mostly claimed generic, are often evaluated on different datasets. Understandable due to the application favor of HNE, such indirect comparisons largely hinder the proper attribution of improved task performance towards effective data preprocessing and novel technical design, especially considering the various ways possible to construct a heterogeneous network from real-world application data. Therefore, as the second contribution, we create four benchmark datasets with various properties regarding scale, structure, attribute/label availability, and \etc.~from different sources, towards handy and fair evaluations of HNE algorithms. As the third contribution, we carefully refactor and amend the implementations and create friendly interfaces for 13 popular HNE algorithms, and provide all-around comparisons among them over multiple tasks and experimental settings.
翻译:由于现实世界的物体及其相互作用往往是多式和多型的,因此,多样化的网络被广泛用作传统同质网络的更强大、更现实和通用超级类;与此同时,最近对代表性学习(aaka-embeding)进行了深入研究,并展示了对各种网络采矿和分析任务的有效性;在这项工作中,我们的目标是提供一个统一框架,以便深入总结和评估关于混杂网络嵌入(HNE)的现有研究,其中包括但超越了正常调查;由于这项工作的最初贡献,已经有一个广泛的HNE算法体系,因此,我们为对现有HNE算法的优点进行系统化的分类和分析提供了一个通用的范例;此外,现有的HNE算法尽管大多称为通用,但经常在不同数据集上得到评价;由于HNE的运用,这种间接比较在很大程度上妨碍了将改进的任务业绩适当归结为有效的数据处理前和新技术设计,特别是考虑到从现实世界应用数据中建立多种可能的方法,因此,我们为现有各种不同结构、不同结构、不同结构、不同结构、不同结构、不同结构、不同结构、不同结构、不同结构、不同结构、我们修正了四个基准数据集,从不同结构、不同结构、不同结构、不同结构、不同结构、不同结构、不同结构、不同结构的可变换了。