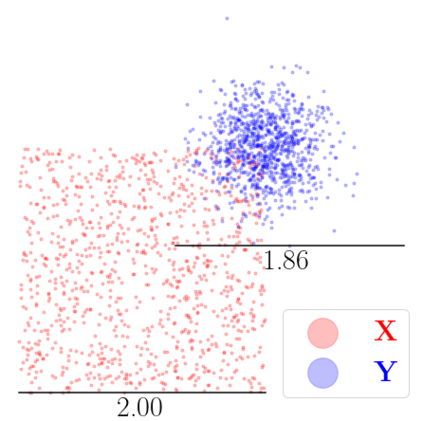
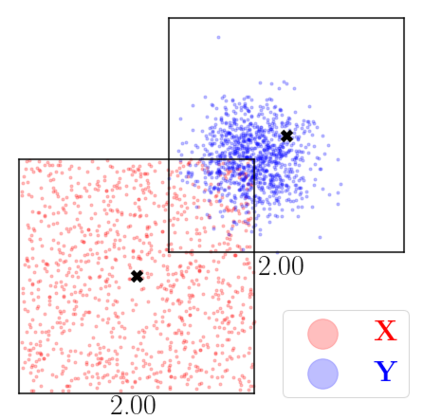
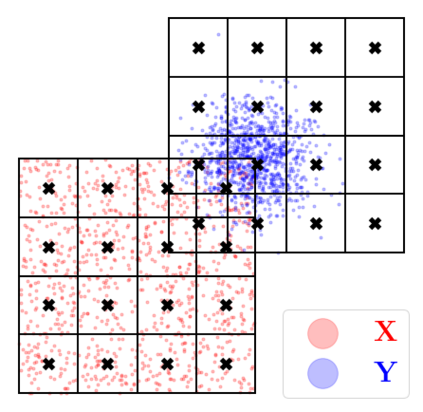
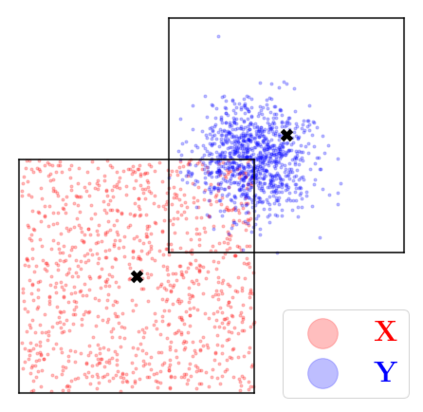
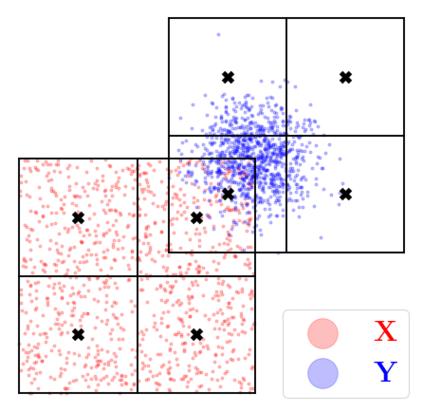
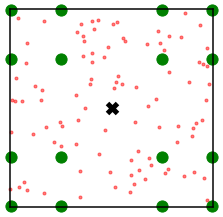
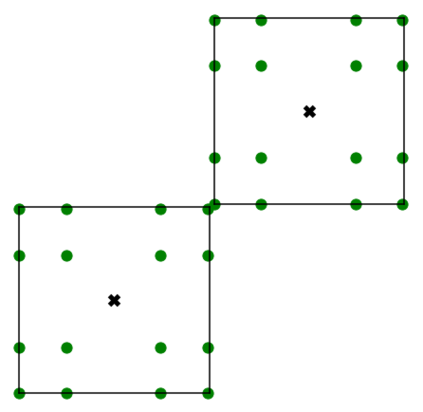
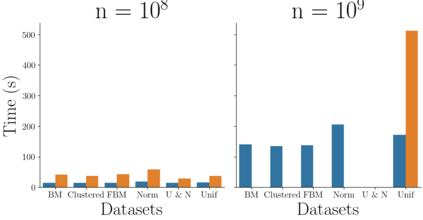
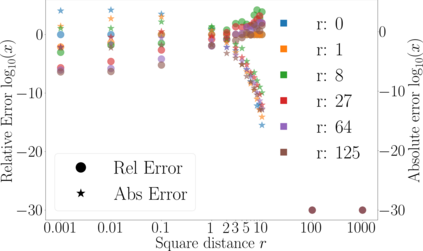
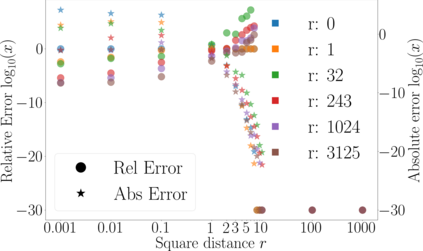
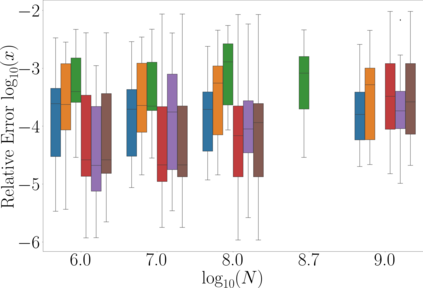
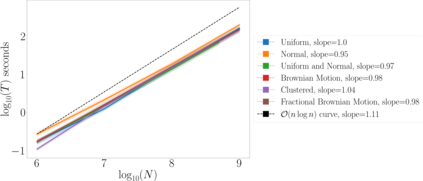
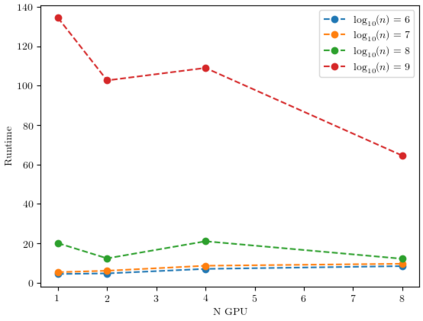
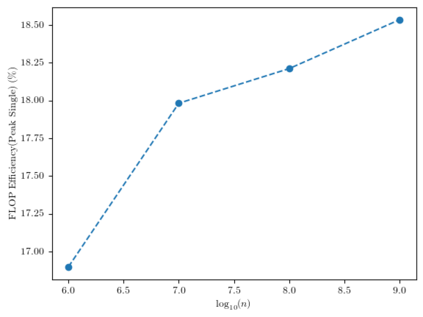
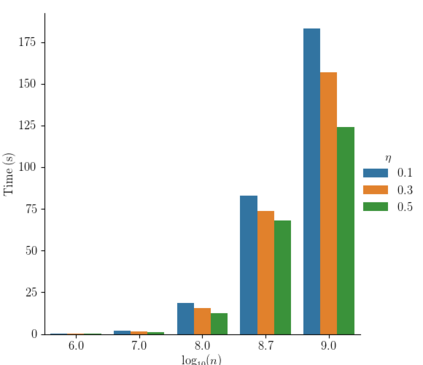
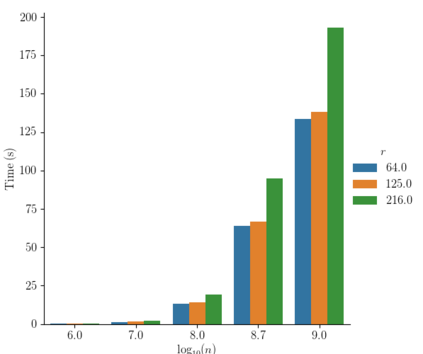
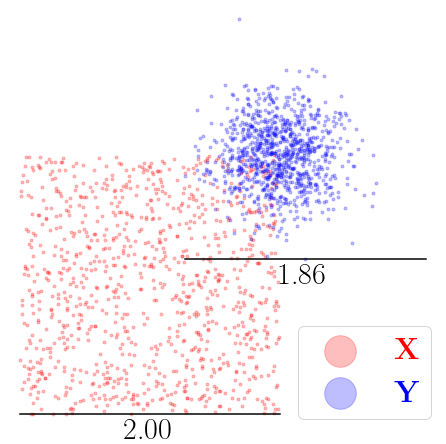
Kernel matrix-vector multiplication (KMVM) is a foundational operation in machine learning and scientific computing. However, as KMVM tends to scale quadratically in both memory and time, applications are often limited by these computational constraints. In this paper, we propose a novel approximation procedure coined \textit{Faster-Fast and Free Memory Method} ($\text{F}^3$M) to address these scaling issues of KMVM for tall~($10^8\sim 10^9$) and skinny~($D\leq7$) data. Extensive experiments demonstrate that $\text{F}^3$M has empirical \emph{linear time and memory} complexity with a relative error of order $10^{-3}$ and can compute a full KMVM for a billion points \emph{in under a minute} on a high-end GPU, leading to a significant speed-up in comparison to existing CPU methods. We demonstrate the utility of our procedure by applying it as a drop-in for the state-of-the-art GPU-based linear solver FALKON, \emph{improving speed 1.5-5.5 times} at the cost of $<1\%$ drop in accuracy. We further demonstrate competitive results on \emph{Gaussian Process regression} coupled with significant speedups on a variety of real-world datasets.
翻译:KMMM 是机器学习和科学计算的基础操作 。 然而, KMMM 通常在记忆和时间上以四倍的缩放, 应用程序往往受这些计算限制的限制 。 在本文中, 我们提议了一个全新的近似程序, 在高端的GPU上, 以10. 8\sim 10. 9美元解决KMVM的这些缩放问题, 高端的数据为10. 8\sim 10. 9美元, 瘦质的 ~ ($D\leq7$) 。 广泛的实验表明, $\ text {F} 3$M 具有经验性\ emph{线性时间和记忆} 复杂性, 相对的错误为 10. 3 美元 美元 美元 和 自由记忆 方法 ($\ f\ 3$) 3$, 我们可以在高端的 GMVMPM 中以十亿 点 /emph{ in a minate production production production the real- prial- prial- procalimal- promoclementalyal translationalyal 5) a we we we prog- produstrational- procumental- procumental- procumental- progyal moclemental__ $GPyal___ moxxxxxxxxxxxxxx