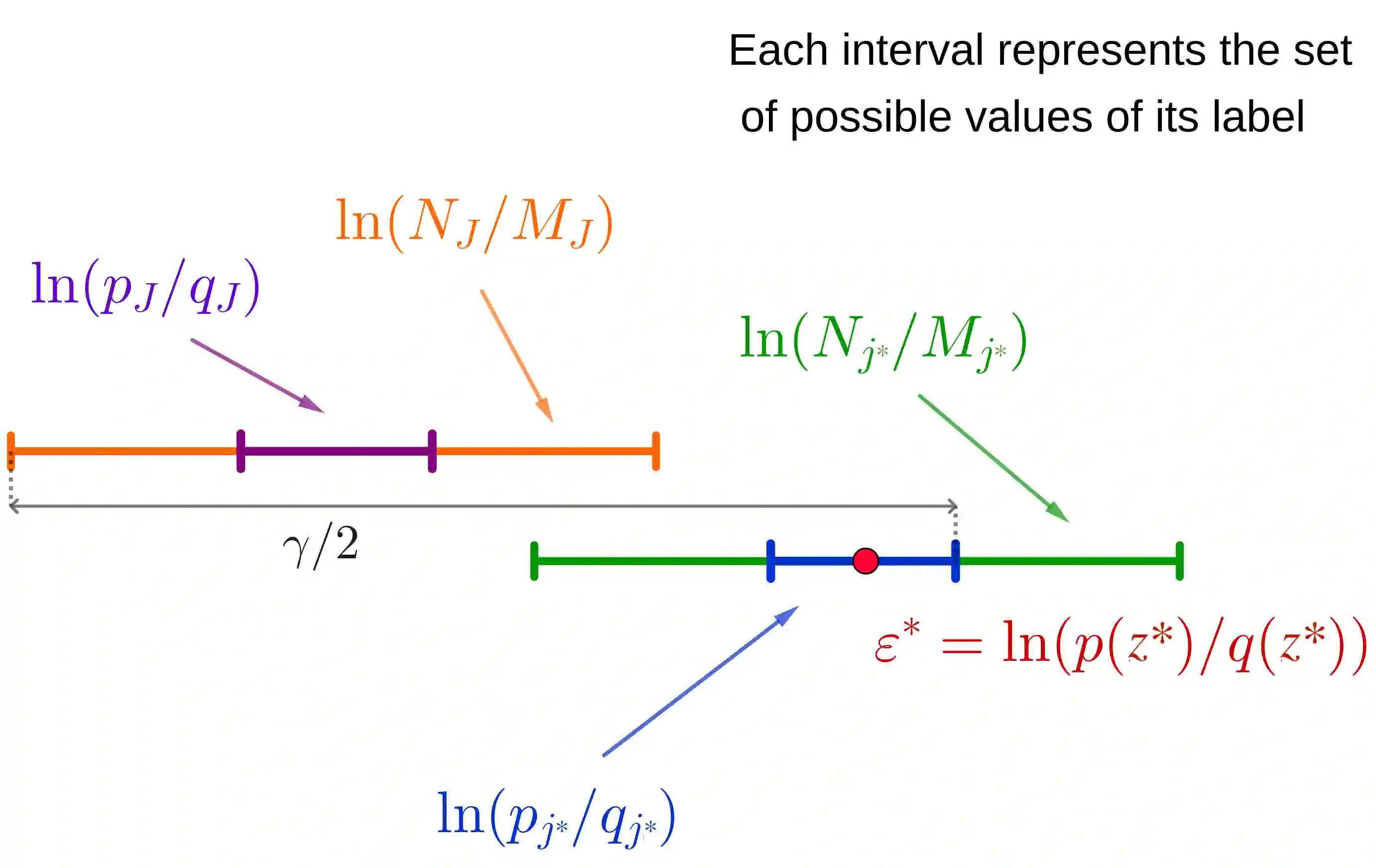
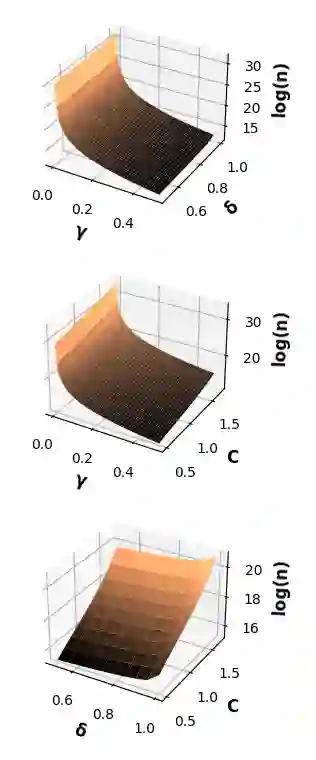
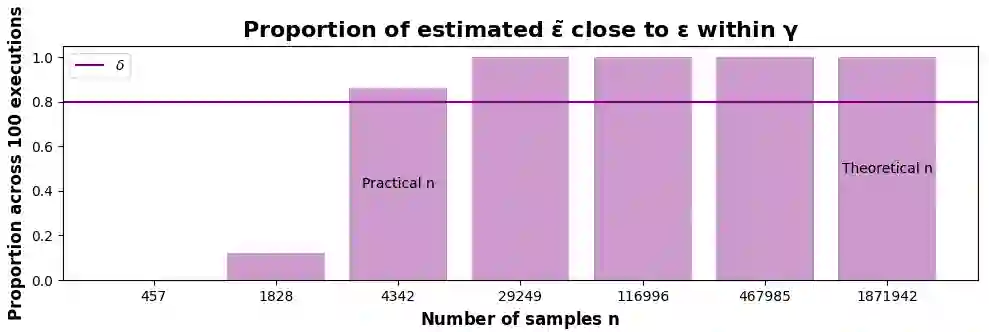
We analyze to what extent final users can infer information about the level of protection of their data when the data obfuscation mechanism is a priori unknown to them (the so-called ''black-box'' scenario). In particular, we delve into the investigation of two notions of local differential privacy (LDP), namely {\epsilon}-LDP and R\'enyi LDP. On one hand, we prove that, without any assumption on the underlying distributions, it is not possible to have an algorithm able to infer the level of data protection with provable guarantees; this result also holds for the central versions of the two notions of DP considered. On the other hand, we demonstrate that, under reasonable assumptions (namely, Lipschitzness of the involved densities on a closed interval), such guarantees exist and can be achieved by a simple histogram-based estimator. We validate our results experimentally and we note that, on a particularly well-behaved distribution (namely, the Laplace noise), our method gives even better results than expected, in the sense that in practice the number of samples needed to achieve the desired confidence is smaller than the theoretical bound, and the estimation of {\epsilon} is more precise than predicted.
翻译:我们分析最终用户在数据模糊机制是他们事先不知道的(所谓的“黑盒子”情景)的情况下,能够在多大程度上推断出数据保护程度的信息。特别是,我们研究了当地差异隐私的两个概念(LDP)的调查情况,即:~epsilon}-LDP和R\'enyi LDP。一方面,我们证明,在对基本分布不作任何假设的情况下,不可能有一种算法,用可辨的保证来推断数据保护程度;这一结果也保留了DP所考虑的两种概念的中心版本。另一方面,我们证明,根据合理的假设(即,所涉密度的利普施茨),这种保证存在,并且可以通过简单的基于直方图的估测器实现。我们通过实验验证了我们的结果,我们注意到,在特别稳妥的分布(即拉普尔噪音)上,我们的方法比预期的结果要好得多,从某种意义上说,从实践上看,精确的样品数量比预期的要小,而精确的估计数比预期的要小。