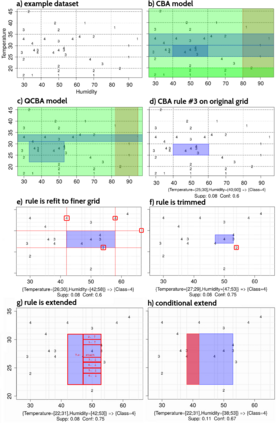
The need to prediscretize numeric attributes before they can be used in association rule learning is a source of inefficiencies in the resulting classifier. This paper describes several new rule tuning steps aiming to recover information lost in the discretization of numeric (quantitative) attributes, and a new rule pruning strategy, which further reduces the size of the classification models. We demonstrate the effectiveness of the proposed methods on postoptimization of models generated by three state-of-the-art association rule classification algorithms: Classification based on Associations (Liu, 1998), Interpretable Decision Sets (Lakkaraju et al, 2016), and Scalable Bayesian Rule Lists (Yang, 2017). Benchmarks on 22 datasets from the UCI repository show that the postoptimized models are consistently smaller -- typically by about 50% -- and have better classification performance on most datasets.
翻译:需要预先分解数字属性,然后才能将其用于关联规则学习,这是由此产生的分类师效率低下的一个原因。本文描述了旨在恢复数字属性离散(定量)属性所丢失信息的若干新规则调整步骤和新的规则裁剪战略,进一步缩小分类模型的规模。我们展示了拟议方法在三个最先进的关联规则分类算法产生的模型的超优化方面的有效性:根据协会分类(Liu,1998年)、可解释决定数据集(Lakkaraju等人,2016年)和可缩放的巴耶西亚规则列表(Yang,2017年),关于UCI存储处22个数据集的基准显示,后优化模型一直较小 -- -- 通常约为50% -- -- 并且大多数数据集的分类性能更好。