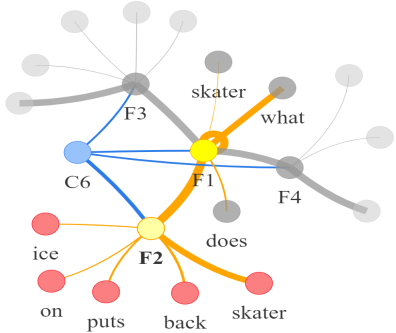
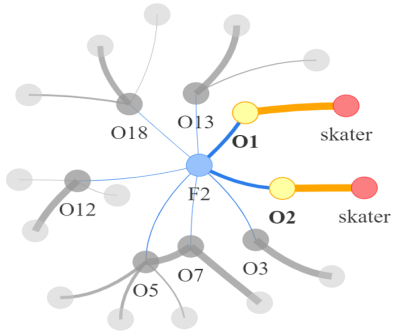
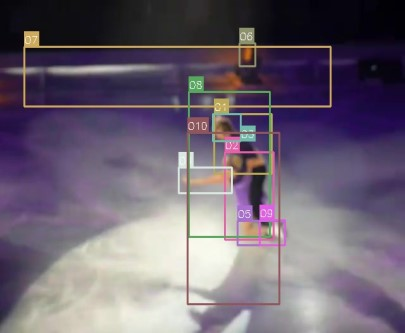
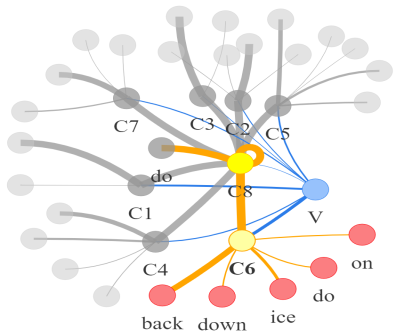
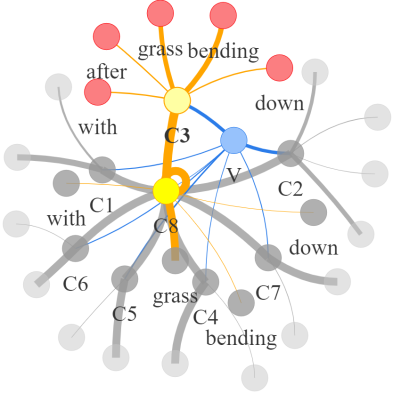
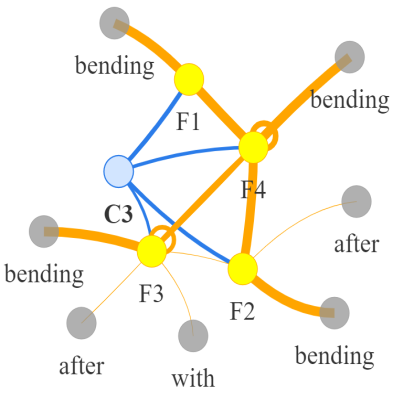
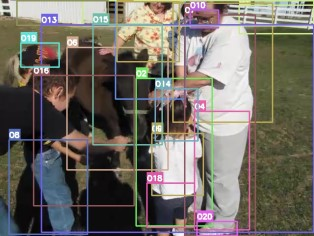
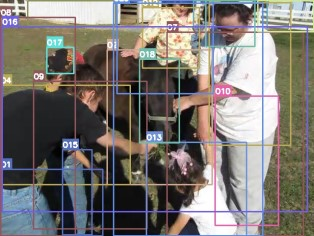
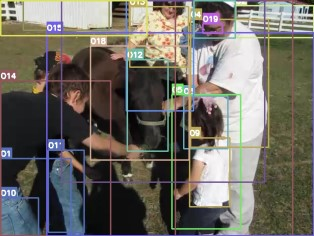
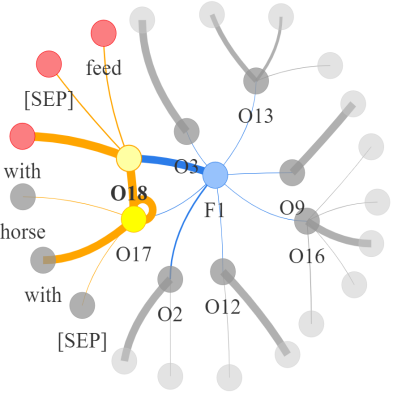
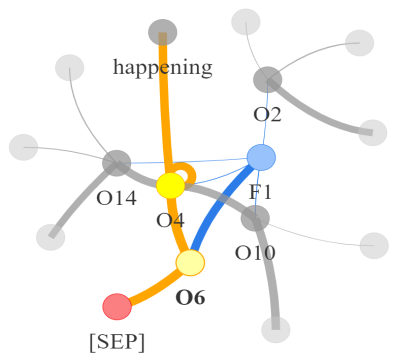
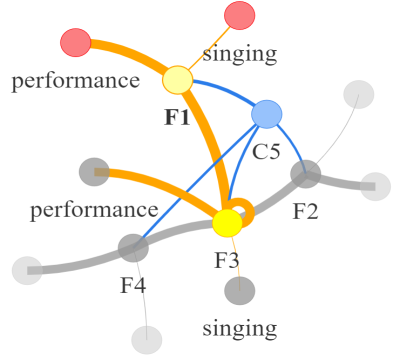
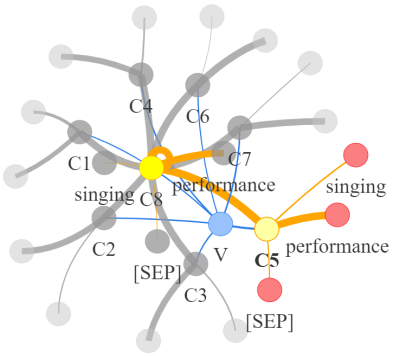
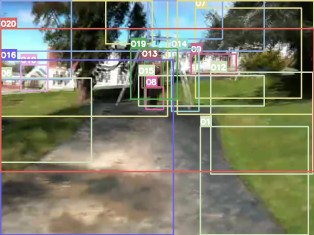
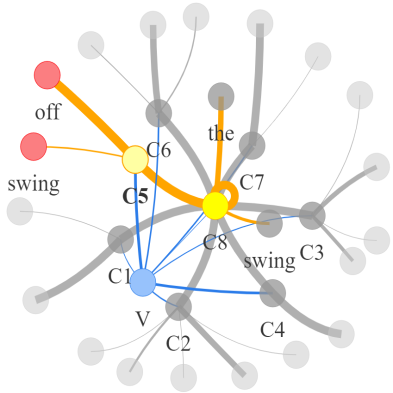
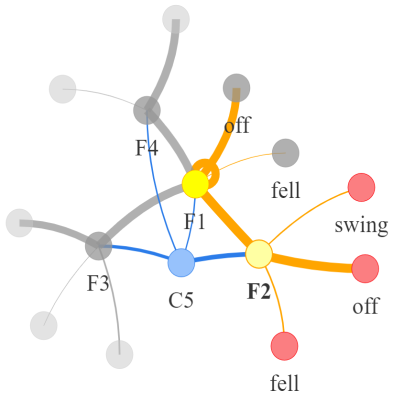
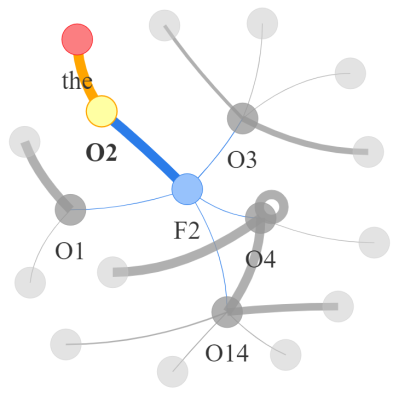
Video question answering requires the models to understand and reason about both the complex video and language data to correctly derive the answers. Existing efforts have been focused on designing sophisticated cross-modal interactions to fuse the information from two modalities, while encoding the video and question holistically as frame and word sequences. Despite their success, these methods are essentially revolving around the sequential nature of video- and question-contents, providing little insight to the problem of question-answering and lacking interpretability as well. In this work, we argue that while video is presented in frame sequence, the visual elements (e.g., objects, actions, activities and events) are not sequential but rather hierarchical in semantic space. To align with the multi-granular essence of linguistic concepts in language queries, we propose to model video as a conditional graph hierarchy which weaves together visual facts of different granularity in a level-wise manner, with the guidance of corresponding textual cues. Despite the simplicity, our extensive experiments demonstrate the superiority of such conditional hierarchical graph architecture, with clear performance improvements over prior methods and also better generalization across different type of questions. Further analyses also demonstrate the model's reliability as it shows meaningful visual-textual evidences for the predicted answers.
翻译:视频解答要求模型理解和理解复杂的视频和语言数据,以正确得出答案; 现有努力侧重于设计复杂的跨模式互动,将信息从两种模式融合起来,同时将视频和问题整体编码为框架和文字序列; 尽管这些方法取得了成功, 基本上围绕视频和问题内容的顺序性质循环, 几乎没有对问答问题的洞察力, 也缺乏可解释性。 在这项工作中, 我们争论说, 视频以框架序列显示, 视频元素( 如对象、行动、活动和事件) 不是顺序的, 而是语义空间的等级。 为了与语言查询中语言概念的多语义本质保持一致, 我们提议将视频建成一个有条件的图表结构, 将不同粒子的视觉事实以水平化的方式拼凑在一起, 指导相应的文字提示。 尽管简单, 我们的广泛实验表明, 视频结构具有优越性, 其性明显地改进了先前的方法, 并且在不同类型的问题中更加概括化。 进一步的分析还表明, 模型的可靠性是真实的预测性, 以真实性为证据。