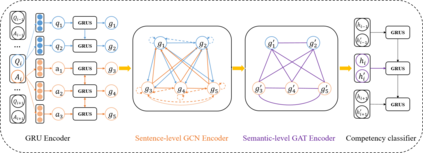
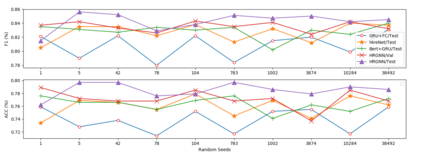
We address the task of automatically scoring the competency of candidates based on textual features, from the automatic speech recognition (ASR) transcriptions in the asynchronous video job interview (AVI). The key challenge is how to construct the dependency relation between questions and answers, and conduct the semantic level interaction for each question-answer (QA) pair. However, most of the recent studies in AVI focus on how to represent questions and answers better, but ignore the dependency information and interaction between them, which is critical for QA evaluation. In this work, we propose a Hierarchical Reasoning Graph Neural Network (HRGNN) for the automatic assessment of question-answer pairs. Specifically, we construct a sentence-level relational graph neural network to capture the dependency information of sentences in or between the question and the answer. Based on these graphs, we employ a semantic-level reasoning graph attention network to model the interaction states of the current QA session. Finally, we propose a gated recurrent unit encoder to represent the temporal question-answer pairs for the final prediction. Empirical results conducted on CHNAT (a real-world dataset) validate that our proposed model significantly outperforms text-matching based benchmark models. Ablation studies and experimental results with 10 random seeds also show the effectiveness and stability of our models.
翻译:我们的任务是根据文本特点自动评分候选人的能力,从非同步录象工作面试中的自动语音识别(ASR)记录中自动评分候选人的能力。关键的挑战是如何构建问答之间的依赖关系,对每个答题和答案进行语义层面的互动。然而,AVI最近的大多数研究侧重于如何更好地代表问题和答案,但忽视了他们之间的依赖性信息和互动,这对QA评估至关重要。在这项工作中,我们提议为自动评估问答配对,建立一个等级理学图表神经网络(HRGNN),具体地说,我们建立一个句级关系图形神经网络,以捕捉每个答题和答案之间判决的依赖性信息。但是,根据这些图表,我们采用了语义层面推理图关注网络,以模拟当前QA会议的互动状态。最后,我们提议建立一个封闭式的经常单位,以代表最后模型的时空问答配对。具体地,我们构建了一个关级关系级的图形神经图形网络网络,用以捕捉到在问答中或问题答案与答案之间的依赖性信息。根据我们提出的10基准模型进行的一项实验性实验性研究,并验证了我们基于实验性模型的实验性研究结果。