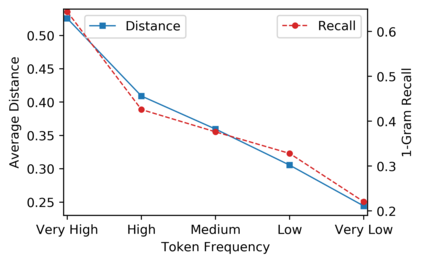
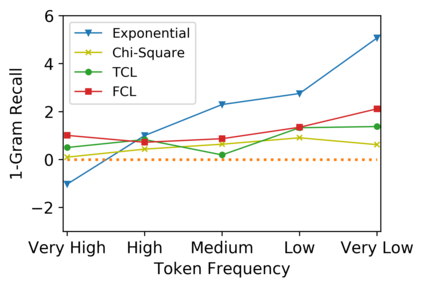
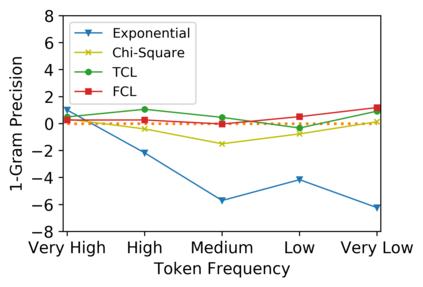
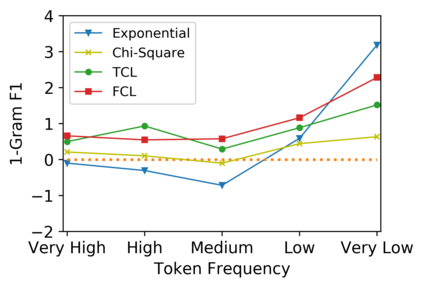
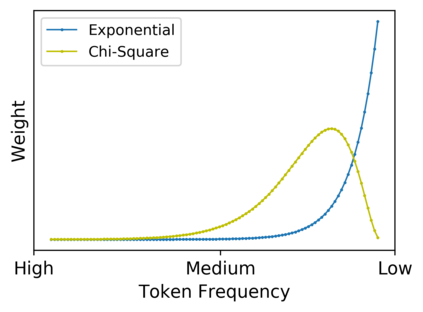
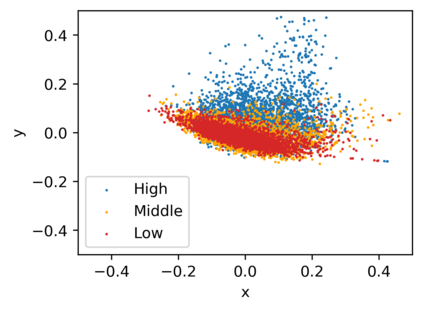
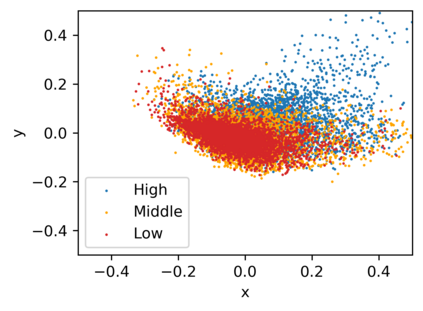
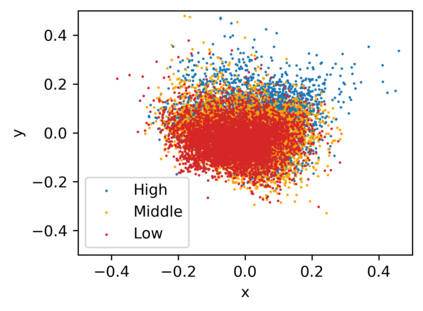
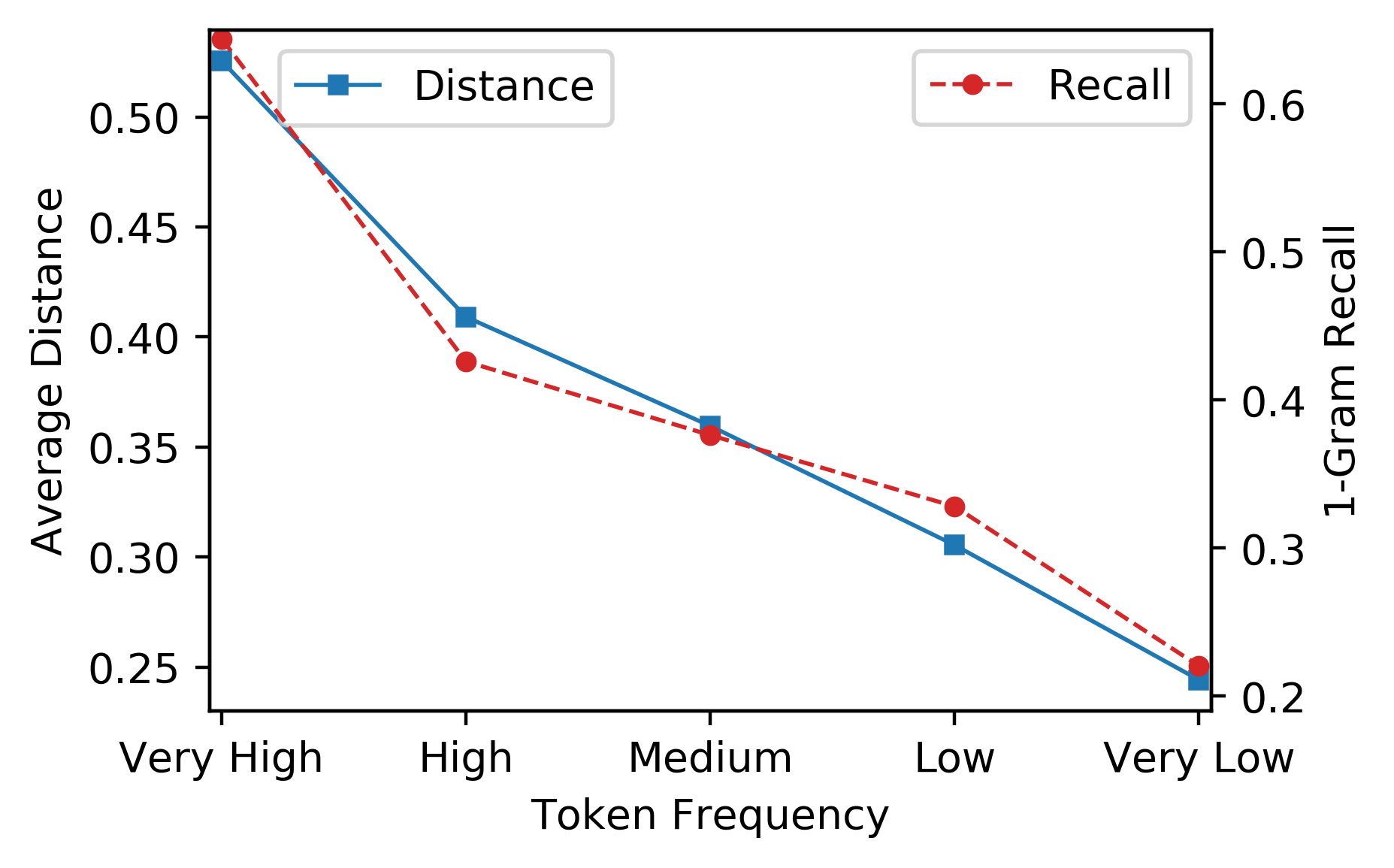
Low-frequency word prediction remains a challenge in modern neural machine translation (NMT) systems. Recent adaptive training methods promote the output of infrequent words by emphasizing their weights in the overall training objectives. Despite the improved recall of low-frequency words, their prediction precision is unexpectedly hindered by the adaptive objectives. Inspired by the observation that low-frequency words form a more compact embedding space, we tackle this challenge from a representation learning perspective. Specifically, we propose a frequency-aware token-level contrastive learning method, in which the hidden state of each decoding step is pushed away from the counterparts of other target words, in a soft contrastive way based on the corresponding word frequencies. We conduct experiments on widely used NIST Chinese-English and WMT14 English-German translation tasks. Empirical results show that our proposed methods can not only significantly improve the translation quality but also enhance lexical diversity and optimize word representation space. Further investigation reveals that, comparing with related adaptive training strategies, the superiority of our method on low-frequency word prediction lies in the robustness of token-level recall across different frequencies without sacrificing precision.
翻译:在现代神经机器翻译系统(NMT)中,低频字预测仍然是一项挑战。最近的适应性培训方法通过强调其在总体培训目标中的权重,促进不常见字的输出。尽管对低频字的回忆有所改进,但其预测精确性却受到适应目标的意外阻碍。从低频字构成一个更紧凑的嵌入空间的观察中,我们从代表性学习的角度来应对这一挑战。具体地说,我们提出一种有频率觉悟的象征性水平对比学习方法,其中每个解码步骤的隐藏状态被从其他目标词的对应方中推开,以基于相应频率的软式对比方式推开。我们对广泛使用的NISP中文英语和WMT14英文英语翻译任务进行了实验。经验性结果显示,我们提出的方法不仅能够显著提高翻译质量,而且能够提高词汇的多样性和优化单词表达空间。进一步的调查显示,与相关的适应性培训战略相比,我们关于低频字数预测的方法的优越性在于不同频率的符号水平的可靠性,而不牺牲精确性。