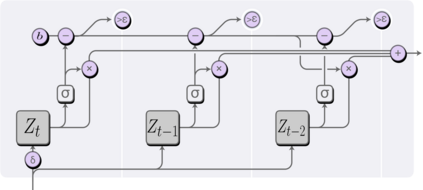
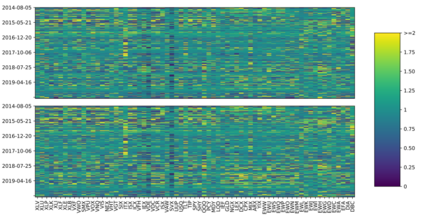
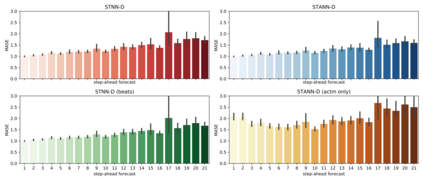
This paper addresses the difficulty of forecasting multiple financial time series (TS) conjointly using deep neural networks (DNN). We investigate whether DNN-based models could forecast these TS more efficiently by learning their representation directly. To this end, we make use of the dynamic factor graph (DFG) from that we enhance by proposing a novel variable-length attention-based mechanism to render it memory-augmented. Using this mechanism, we propose an unsupervised DNN architecture for multivariate TS forecasting that allows to learn and take advantage of the relationships between these TS. We test our model on two datasets covering 19 years of investment funds activities. Our experimental results show that our proposed approach outperforms significantly typical DNN-based and statistical models at forecasting their 21-day price trajectory.
翻译:本文探讨利用深神经网络共同预测多个财务时间序列的困难。 我们调查基于DNN的模型能否通过直接了解其代表性来更高效地预测这些TS。 为此,我们利用动态要素图(DFG),从我们所强化的动态要素图(DFG)中,提出一个新的基于可变时间的注意机制,使其记忆增强。我们利用这一机制,为多变量的TS预测提议了一个不受监督的DNN结构,以便学习和利用这些TS之间的关系。我们测试了我们关于19年投资资金活动的两个数据集的模式。我们的实验结果表明,我们提出的方法在预测21天的价格轨迹时,明显优于典型的DNN和统计模型。