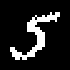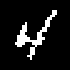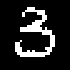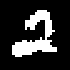We present TraDE, a self-attention-based architecture for auto-regressive density estimation with continuous and discrete valued data. Our model is trained using a penalized maximum likelihood objective, which ensures that samples from the density estimate resemble the training data distribution. The use of self-attention means that the model need not retain conditional sufficient statistics during the auto-regressive process beyond what is needed for each covariate. On standard tabular and image data benchmarks, TraDE produces significantly better density estimates than existing approaches such as normalizing flow estimators and recurrent auto-regressive models. However log-likelihood on held-out data only partially reflects how useful these estimates are in real-world applications. In order to systematically evaluate density estimators, we present a suite of tasks such as regression using generated samples, out-of-distribution detection, and robustness to noise in the training data and demonstrate that TraDE works well in these scenarios.
翻译:TraDE是自动递减密度估算的基于自我注意的架构,具有连续和离散的价值数据; 我们的模型是使用一个固定的最大可能性目标来培训的,确保密度估算的样本与培训数据分布相似; 使用自我注意意味着在自动递减过程中不需要在每一个共变体所需要的数据之外保留有条件的充足统计数据; 在标准表格和图像数据基准上,TraDE产生的密度估算大大高于现有方法,如流量估算器和经常性自动递减模型的正常化。 然而,搁置数据的日志相似性仅部分反映了这些估算在现实世界应用中的有用性。 为了系统地评估密度估测器,我们提出了一系列任务,例如利用生成的样本进行回归、分配外检测、在培训数据中对噪音的稳健度,并证明TraDE在这些情景中效果良好。