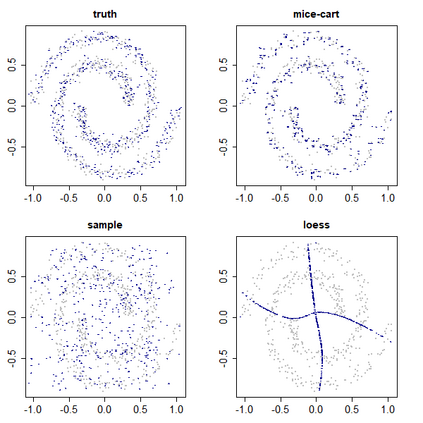
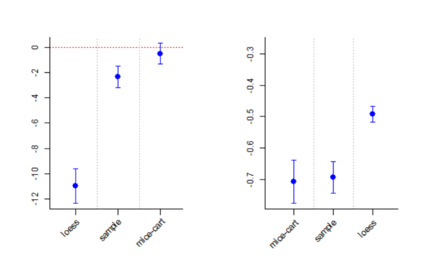
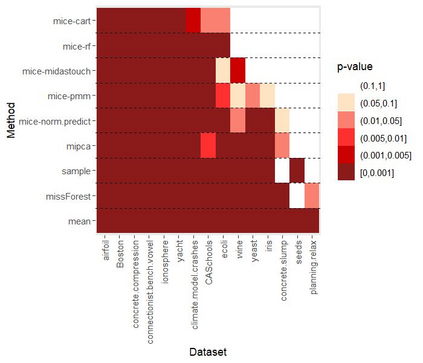
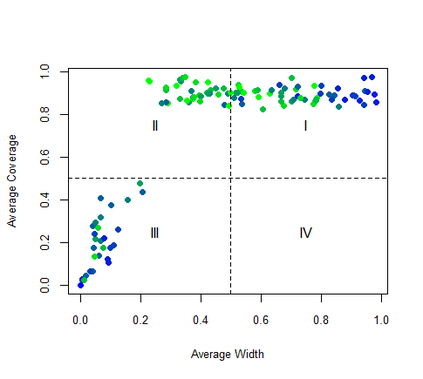
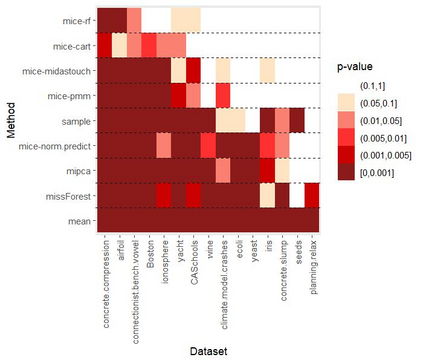
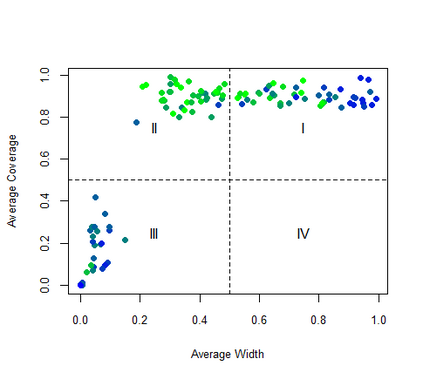
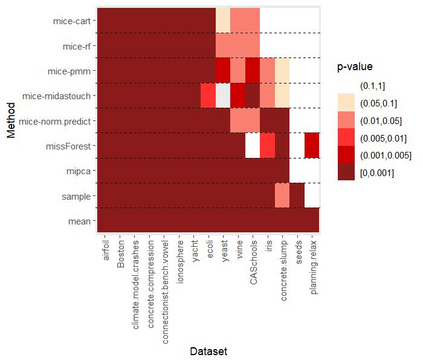
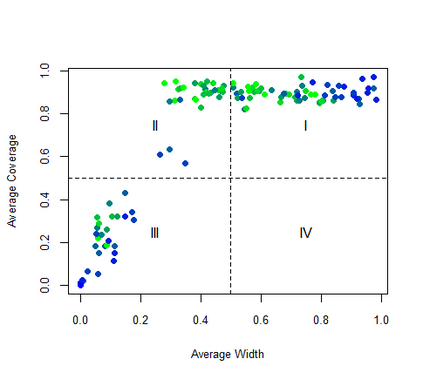
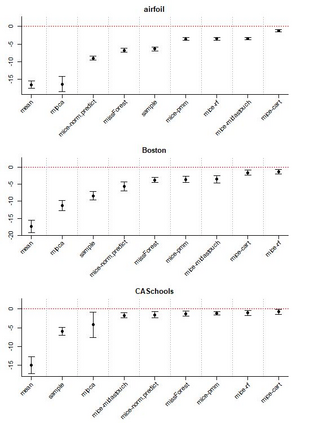
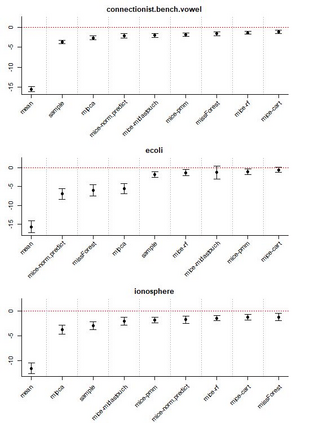
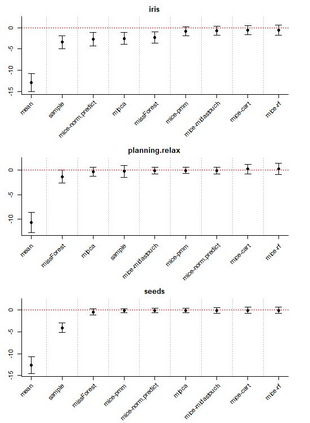
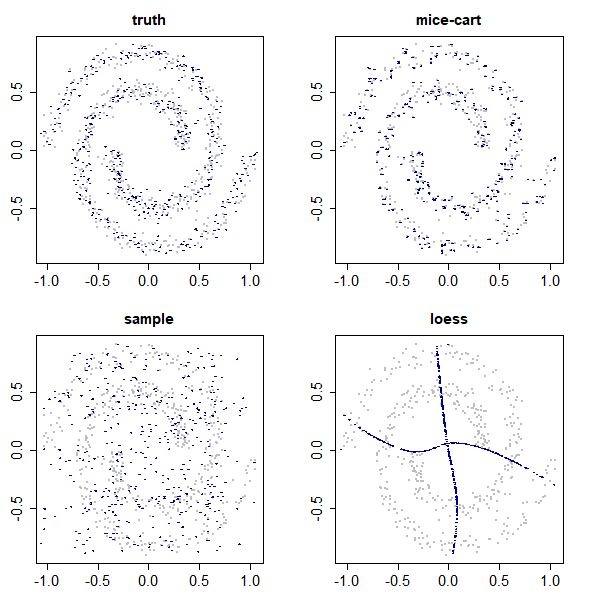
Given the prevalence of missing data in modern statistical research, a broad range of methods is available for any given imputation task. How does one choose the `best' method in a given application? The standard approach is to select some observations, set their status to missing, and compare prediction accuracy of the methods under consideration for these observations. Besides having to somewhat artificially mask additional observations, a shortcoming of this approach is that the optimal imputation in this scheme chooses the conditional mean if predictive accuracy is measured with RMSE. In contrast, we would like to rank highest methods that can sample from the true conditional distribution. In this paper, we develop a principled and easy-to-use evaluation method for missing value imputation under the missing completely at random (MCAR) assumption. The approach is applicable for discrete and continuous data and works on incomplete data sets, without having to leave out additional observations for evaluation. Moreover, it favors imputation methods that reproduce the original data distribution. We show empirically on a range of data sets and imputation methods that our score consistently ranks true data high(est) and is able to avoid pitfalls usually associated with performance measures such as RMSE. Finally, we provide an R-package with an implementation of our method.
翻译:鉴于现代统计研究中缺少的数据十分普遍,因此可以对任何特定估算任务采用广泛的方法。在特定应用中,如何选择“最佳”方法?标准方法是选择某些观测,将其状况设定为缺失状态,并比较审议中方法的预测准确性。除了必须在某种程度上人为地掩盖额外观测之外,这一方法的一个缺点是,如果用RUSE衡量预测准确性,这个方法的最佳估算方法选择有条件的平均值。相比之下,我们希望将能够从真正的有条件分布中抽样的最高方法排在首位。在本文中,我们为完全随机(MCAR)假设缺失的缺失值估算制定了原则性和易于使用的评估方法。该方法适用于离散和连续的数据,并针对不完整的数据集开展工作,而不必留下额外的观察来进行评估。此外,它赞成采用复制原始数据分布的估算方法。我们用经验来显示一系列数据集和估算方法,这些数据集和估算方法能够从真实的有条件分布中进行抽样。在本文中,我们在完全随机(MCAR)假设的假设下,为缺失的缺失值估算制定了一种原则性和易使用的评估方法。该方法适用于离散连续连续连续连续连续和连续的数据和连续进行计算。此外,我们作为执行的方法。