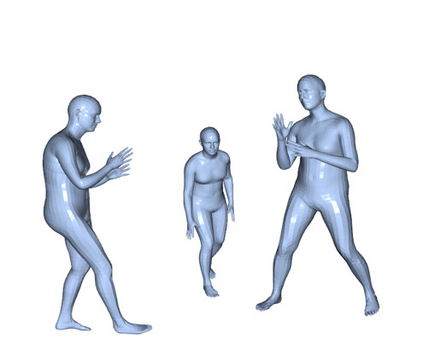
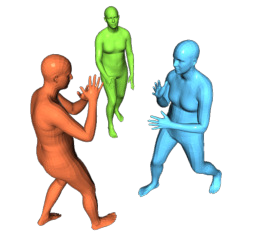
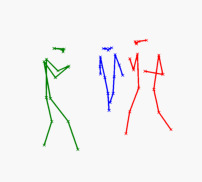
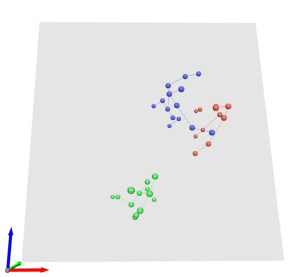
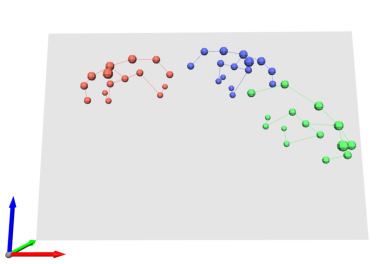
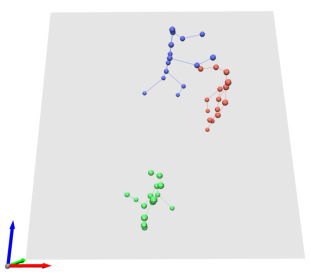
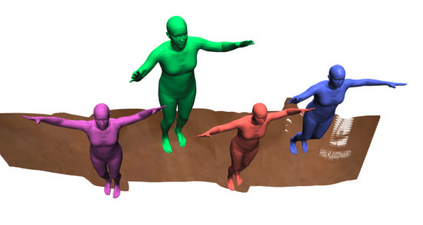
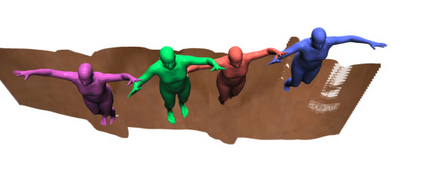
In this work, we consider the problem of estimating the 3D position of multiple humans in a scene as well as their body shape and articulation from a single RGB video recorded with a static camera. In contrast to expensive marker-based or multi-view systems, our lightweight setup is ideal for private users as it enables an affordable 3D motion capture that is easy to install and does not require expert knowledge. To deal with this challenging setting, we leverage recent advances in computer vision using large-scale pre-trained models for a variety of modalities, including 2D body joints, joint angles, normalized disparity maps, and human segmentation masks. Thus, we introduce the first non-linear optimization-based approach that jointly solves for the absolute 3D position of each human, their articulated pose, their individual shapes as well as the scale of the scene. In particular, we estimate the scene depth and person unique scale from normalized disparity predictions using the 2D body joints and joint angles. Given the per-frame scene depth, we reconstruct a point-cloud of the static scene in 3D space. Finally, given the per-frame 3D estimates of the humans and scene point-cloud, we perform a space-time coherent optimization over the video to ensure temporal, spatial and physical plausibility. We evaluate our method on established multi-person 3D human pose benchmarks where we consistently outperform previous methods and we qualitatively demonstrate that our method is robust to in-the-wild conditions including challenging scenes with people of different sizes.
翻译:在这项工作中,我们考虑如何估计多人类在现场的3D位置以及他们的身体形状,以及用一个静态相机录制的单一 RGB 视频来显示他们的身体形状和分解面。与昂贵的基于标记或多视图的系统相比,我们的轻量级设置对私人用户来说是理想的,因为它能够让一个负担得起的3D运动捕捉容易安装,不需要专家知识。为了应对这一具有挑战性的环境,我们利用大规模预先培训模型,在各种模式上利用计算机视觉方面的最新进展,包括2D身体接合、联合角度、标准差异图和人体分解面罩。因此,我们采用了第一个非线性优化法,共同解决每个人绝对的3D位置、其直观、个人形状以及场景的大小。我们特别利用2D身体联合点和联合角度,从正常差异预测中估算出场景的深度和个人独特规模。我们从每个平台的深度深度深度、共同角度重建了3D空间静态场景的点。最后,我们从一个连续的3D 人际空间定位方法到我们连续的深度的深度评估,我们用一个连续的图像和高度的图像模型来评估。