【论文推荐】最新六篇图像分割相关论文—控制、全卷积网络、子空间表示、多模态图像分割
【导读】专知内容组整理了最近六篇图像分割(Image Segmentation)相关文章,为大家进行介绍,欢迎查看!
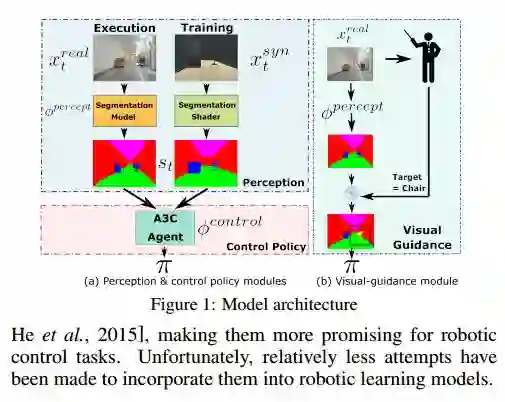
1.Virtual-to-Real: Learning to Control in Visual Semantic Segmentation
作者:Zhang-Wei Hong,Chen Yu-Ming,Shih-Yang Su,Tzu-Yun Shann,Yi-Hsiang Chang,Hsuan-Kung Yang,Brian Hsi-Lin Ho,Chih-Chieh Tu,Yueh-Chuan Chang,Tsu-Ching Hsiao,Hsin-Wei Hsiao,Sih-Pin Lai,Chun-Yi Lee
机构:National Tsing Hua University,National Chiao Tong University
摘要:Collecting training data from the physical world is usually time-consuming and even dangerous for fragile robots, and thus, recent advances in robot learning advocate the use of simulators as the training platform. Unfortunately, the reality gap between synthetic and real visual data prohibits direct migration of the models trained in virtual worlds to the real world. This paper proposes a modular architecture for tackling the virtual-to-real problem. The proposed architecture separates the learning model into a perception module and a control policy module, and uses semantic image segmentation as the meta representation for relating these two modules. The perception module translates the perceived RGB image to semantic image segmentation. The control policy module is implemented as a deep reinforcement learning agent, which performs actions based on the translated image segmentation. Our architecture is evaluated in an obstacle avoidance task and a target following task. Experimental results show that our architecture significantly outperforms all of the baseline methods in both virtual and real environments, and demonstrates a faster learning curve than them. We also present a detailed analysis for a variety of variant configurations, and validate the transferability of our modular architecture.
期刊:arXiv, 2018年3月18日
网址:
http://www.zhuanzhi.ai/document/df11369c10c2a380fef2e471af83d19e
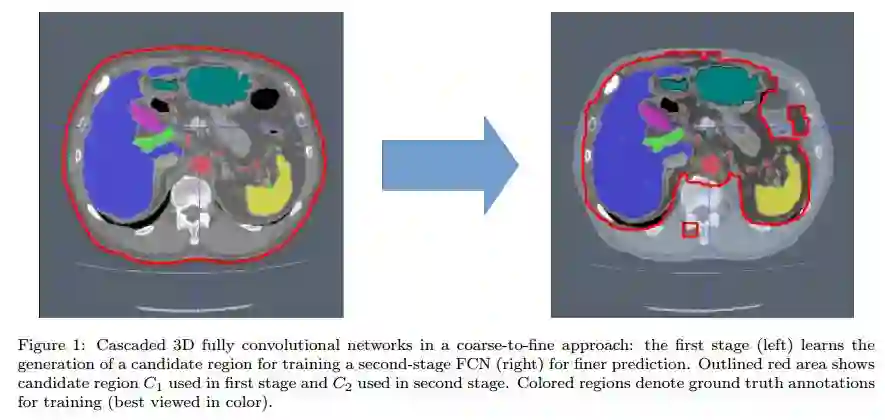
2.An application of cascaded 3D fully convolutional networks for medical image segmentation(基于级联三维全卷积网络的医学图像分割)
作者:Holger R. Roth,Hirohisa Oda,Xiangrong Zhou,Natsuki Shimizu,Ying Yang,Yuichiro Hayashi,Masahiro Oda,Michitaka Fujiwara,Kazunari Misawa,Kensaku Mori
机构:Nagoya University,Gifu University
摘要:Recent advances in 3D fully convolutional networks (FCN) have made it feasible to produce dense voxel-wise predictions of volumetric images. In this work, we show that a multi-class 3D FCN trained on manually labeled CT scans of several anatomical structures (ranging from the large organs to thin vessels) can achieve competitive segmentation results, while avoiding the need for handcrafting features or training class-specific models. To this end, we propose a two-stage, coarse-to-fine approach that will first use a 3D FCN to roughly define a candidate region, which will then be used as input to a second 3D FCN. This reduces the number of voxels the second FCN has to classify to ~10% and allows it to focus on more detailed segmentation of the organs and vessels. We utilize training and validation sets consisting of 331 clinical CT images and test our models on a completely unseen data collection acquired at a different hospital that includes 150 CT scans, targeting three anatomical organs (liver, spleen, and pancreas). In challenging organs such as the pancreas, our cascaded approach improves the mean Dice score from 68.5 to 82.2%, achieving the highest reported average score on this dataset. We compare with a 2D FCN method on a separate dataset of 240 CT scans with 18 classes and achieve a significantly higher performance in small organs and vessels. Furthermore, we explore fine-tuning our models to different datasets. Our experiments illustrate the promise and robustness of current 3D FCN based semantic segmentation of medical images, achieving state-of-the-art results. Our code and trained models are available for download: https://github.com/holgerroth/3Dunet_abdomen_cascade.
期刊:arXiv, 2018年3月20日
网址:
http://www.zhuanzhi.ai/document/4a59f83a57a9312c269f5da94f6a0907
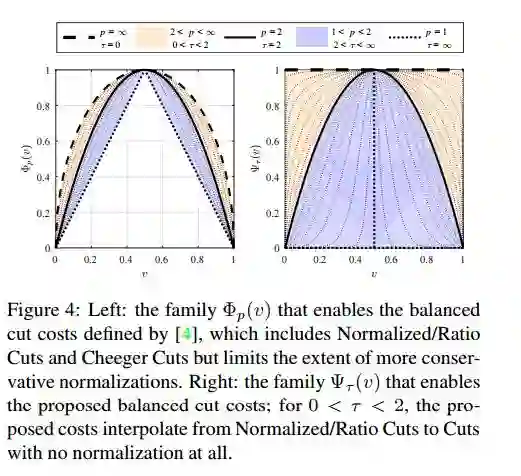
3.Compassionately Conservative Balanced Cuts for Image Segmentation
作者:Nathan D. Cahill,Tyler L. Hayes,Renee T. Meinhold,John F. Hamilton
摘要:The Normalized Cut (NCut) objective function, widely used in data clustering and image segmentation, quantifies the cost of graph partitioning in a way that biases clusters or segments that are balanced towards having lower values than unbalanced partitionings. However, this bias is so strong that it avoids any singleton partitions, even when vertices are very weakly connected to the rest of the graph. Motivated by the B\"uhler-Hein family of balanced cut costs, we propose the family of Compassionately Conservative Balanced (CCB) Cut costs, which are indexed by a parameter that can be used to strike a compromise between the desire to avoid too many singleton partitions and the notion that all partitions should be balanced. We show that CCB-Cut minimization can be relaxed into an orthogonally constrained $\ell_{\tau}$-minimization problem that coincides with the problem of computing Piecewise Flat Embeddings (PFE) for one particular index value, and we present an algorithm for solving the relaxed problem by iteratively minimizing a sequence of reweighted Rayleigh quotients (IRRQ). Using images from the BSDS500 database, we show that image segmentation based on CCB-Cut minimization provides better accuracy with respect to ground truth and greater variability in region size than NCut-based image segmentation.
期刊:arXiv, 2018年3月27日
网址:
http://www.zhuanzhi.ai/document/5e5409f17d9aba0f1f47dff24284c7d0
4.Image Segmentation Using Subspace Representation and Sparse Decomposition(基于子空间表示和稀疏分解的图像分割)
作者:Shervin Minaee
机构:NEW YORK UNIVERSITY
摘要:Image foreground extraction is a classical problem in image processing and vision, with a large range of applications. In this dissertation, we focus on the extraction of text and graphics in mixed-content images, and design novel approaches for various aspects of this problem. We first propose a sparse decomposition framework, which models the background by a subspace containing smooth basis vectors, and foreground as a sparse and connected component. We then formulate an optimization framework to solve this problem, by adding suitable regularizations to the cost function to promote the desired characteristics of each component. We present two techniques to solve the proposed optimization problem, one based on alternating direction method of multipliers (ADMM), and the other one based on robust regression. Promising results are obtained for screen content image segmentation using the proposed algorithm. We then propose a robust subspace learning algorithm for the representation of the background component using training images that could contain both background and foreground components, as well as noise. With the learnt subspace for the background, we can further improve the segmentation results, compared to using a fixed subspace. Lastly, we investigate a different class of signal/image decomposition problem, where only one signal component is active at each signal element. In this case, besides estimating each component, we need to find their supports, which can be specified by a binary mask. We propose a mixed-integer programming problem, that jointly estimates the two components and their supports through an alternating optimization scheme. We show the application of this algorithm on various problems, including image segmentation, video motion segmentation, and also separation of text from textured images.

期刊:arXiv, 2018年4月7日
网址:
http://www.zhuanzhi.ai/document/22303381b9b1e4a9e67d66195c8aec6c
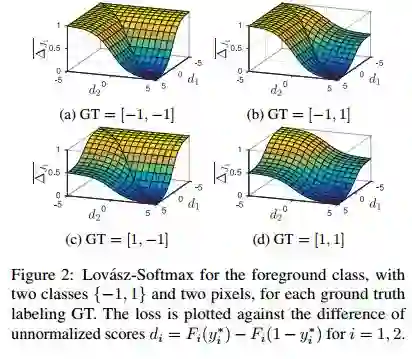
5.The Lovász-Softmax loss: A tractable surrogate for the optimization of the intersection-over-union measure in neural networks
作者:Maxim Berman,Amal Rannen Triki,Matthew B. Blaschko
摘要:The Jaccard index, also referred to as the intersection-over-union score, is commonly employed in the evaluation of image segmentation results given its perceptual qualities, scale invariance - which lends appropriate relevance to small objects, and appropriate counting of false negatives, in comparison to per-pixel losses. We present a method for direct optimization of the mean intersection-over-union loss in neural networks, in the context of semantic image segmentation, based on the convex Lov\'asz extension of submodular losses. The loss is shown to perform better with respect to the Jaccard index measure than the traditionally used cross-entropy loss. We show quantitative and qualitative differences between optimizing the Jaccard index per image versus optimizing the Jaccard index taken over an entire dataset. We evaluate the impact of our method in a semantic segmentation pipeline and show substantially improved intersection-over-union segmentation scores on the Pascal VOC and Cityscapes datasets using state-of-the-art deep learning segmentation architectures.
期刊:arXiv, 2018年4月9日
网址:
http://www.zhuanzhi.ai/document/048685cd67f1b7c9807a7614dcb964e2
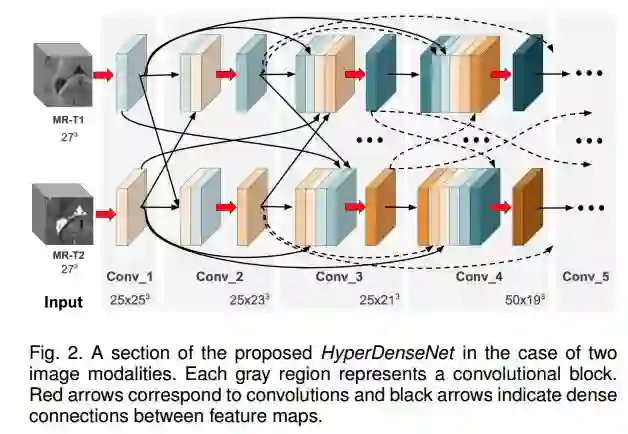
6.HyperDense-Net: A hyper-densely connected CNN for multi-modal image segmentation(HyperDense-Net:一个超紧密连接的CNN,用于多模态图像分割)
作者:Jose Dolz,Karthik Gopinath,Jing Yuan,Herve Lombaert,Christian Desrosiers,Ismail Ben Ayed
摘要:Recently, dense connections have attracted substantial attention in computer vision because they facilitate gradient flow and implicit deep supervision during training. Particularly, DenseNet, which connects each layer to every other layer in a feed-forward fashion, has shown impressive performances in natural image classification tasks. We propose HyperDenseNet, a 3D fully convolutional neural network that extends the definition of dense connectivity to multi-modal segmentation problems. Each imaging modality has a path, and dense connections occur not only between the pairs of layers within the same path, but also between those across different paths. This contrasts with the existing multi-modal CNN approaches, in which modeling several modalities relies entirely on a single joint layer (or level of abstraction) for fusion, typically either at the input or at the output of the network. Therefore, the proposed network has total freedom to learn more complex combinations between the modalities, within and in-between all the levels of abstraction, which increases significantly the learning representation. We report extensive evaluations over two different and highly competitive multi-modal brain tissue segmentation challenges, iSEG 2017 and MRBrainS 2013, with the former focusing on 6-month infant data and the latter on adult images. HyperDenseNet yielded significant improvements over many state-of-the-art segmentation networks, ranking at the top on both benchmarks. We further provide a comprehensive experimental analysis of features re-use, which confirms the importance of hyper-dense connections in multi-modal representation learning. Our code is publicly available at https://www.github.com/josedolz/HyperDenseNet.
期刊:arXiv, 2018年4月9日
网址:
http://www.zhuanzhi.ai/document/0b42c09b4e8e21e1a60c99477f9c8daa
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
投稿&广告&商务合作:fangquanyi@gmail.com
点击“阅读原文”,使用专知



