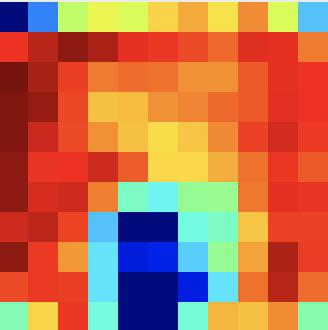
RGB-D salient object detection (SOD) recently has attracted increasing research interest and many deep learning methods based on encoder-decoder architectures have emerged. However, most existing RGB-D SOD models conduct feature fusion either in the single encoder or the decoder stage, which hardly guarantees sufficient cross-modal fusion ability. In this paper, we make the first attempt in addressing RGB-D SOD through 3D convolutional neural networks. The proposed model, named RD3D, aims at pre-fusion in the encoder stage and in-depth fusion in the decoder stage to effectively promote the full integration of RGB and depth streams. Specifically, RD3D first conducts pre-fusion across RGB and depth modalities through an inflated 3D encoder, and later provides in-depth feature fusion by designing a 3D decoder equipped with rich back-projection paths (RBPP) for leveraging the extensive aggregation ability of 3D convolutions. With such a progressive fusion strategy involving both the encoder and decoder, effective and thorough interaction between the two modalities can be exploited and boost the detection accuracy. Extensive experiments on six widely used benchmark datasets demonstrate that RD3D performs favorably against 14 state-of-the-art RGB-D SOD approaches in terms of four key evaluation metrics. Our code will be made publicly available: https://github.com/PPOLYpubki/RD3D.
翻译:RGB-D显性物体探测(SOD)最近引起了越来越多的研究兴趣,许多基于编码器脱coder结构的深层次学习方法已经出现,然而,大多数现有的RGB-D SOD模型在单一编码器或解码器阶段进行特征融合,这很难保证足够的跨模式融合能力。在本文件中,我们首次尝试通过3D 革命神经网络处理RGB-D SOD问题。提议的模型名为RD3D,目的是在编码器阶段进行预融合,在解码阶段进行深入融合,以有效促进RGB和深度流的全面融合。具体地说,RD3D模型首先通过一个膨胀的3D编码和深度模式进行预融合,而后又通过设计一个具有丰富反光预测路径的 3D 3D 的3D 解码,利用3D 3D 的庞大的集成能力来利用 3D 的集成和分解码 3,在解码和分解码阶段进行深入的深入融合战略,从而有效地和彻底地将RGBD 3 4号进行我们使用的主要基准模式的测试。