
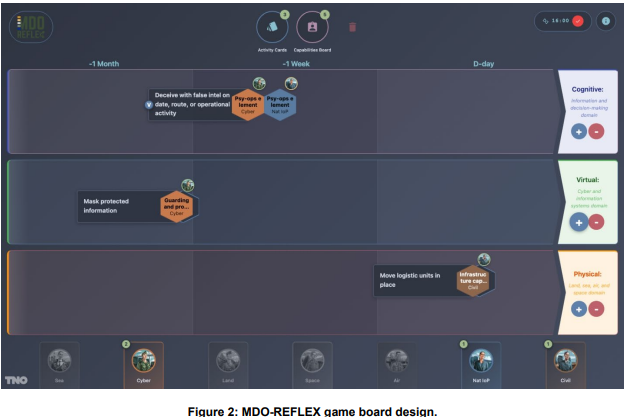
多域作战(MDO)处于现代军事转型的前沿,它要求跨越陆、空、海、网络、太空域以及民事组织和国家权力工具(警察、外交)的同步行动。对国防部门而言,在人员中培养对多域作战原则的深刻理解,对于建设一支能在复杂环境中敏捷行动的部队至关重要。超越物理域,国防部专业人员必须善于感知和影响认知域与虚拟域的效果,并善于整合所有域和权力工具的能力。
本文介绍一种兵棋推演方法,该方法利用人工智能——特别是大语言模型(LLM)——为国防部人员营造有意义的学习体验。独特之处在于,大语言模型扮演双重角色:它不仅是基于形态学分析构建沉浸式、有分析依据的想定片段的中心,也是在训练推演中生成动态、定制化反馈的核心。通过同时支持想定构建和实时评估,大语言模型使参与者能够超越传统的动能思维,接纳全方位的多域作战效果。
成为VIP会员查看完整内容


