视频理解 S3D,I3D-GCN,SlowFastNet, LFB
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
原创:Fisher Yu@Oulu
作者:SIGAI人工智能平台
出处:SIGAI人工智能平台
公众号:SIGAI
最近看了下几篇动作识别,视频理解的文章,在这里记下小笔记,简单过一下核心思想,以便后续查阅及拓展使用。
文章主要想探索的问题如下:
1.如何改造I3D,使其更轻量且性能更好?
2.如何改造I3D,使其理解视频场景里的物体交互?
3.如何高效融合不同帧率,不同 temporal 分辨率的视频?
4.如何让网络拥有 Long-term 的能力(即理解10秒以上的长视频)?
Separable 3D CNN (S3D) [1], ECCV2018
文章的创新不是很多,但是就像当初提出P3D和R(2+1)D一样,做了很多对比实验,来探讨分解卷积及网络结构设计的性能对比。这里主要贴几个重要结论,后面设计相关网络时可用:
-
通过实验证明了 top-heavy model design 更轻量,且性能更优:
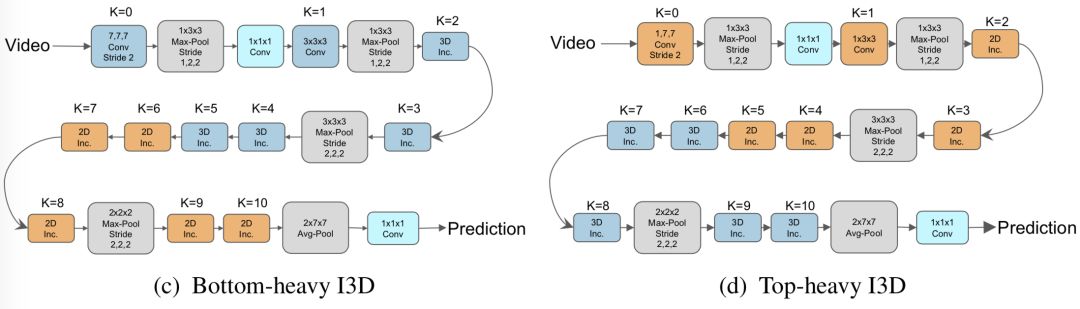
top-heavy 和 bottom-heavy 的区别是,前者先2D再3D,而后者先3D再2D。故前者在时空分辨率极高的的前几层使用2D卷积,而在时空分辨率较低的后几层对semantic feature进行3D卷积,故更轻量性能更好。
2. 在保持I3D的Inception Backbone不变情况下,将 3x3x3 卷积核都换成 1x3x3 + 3x1x1 卷积,参数更少且性能更好:
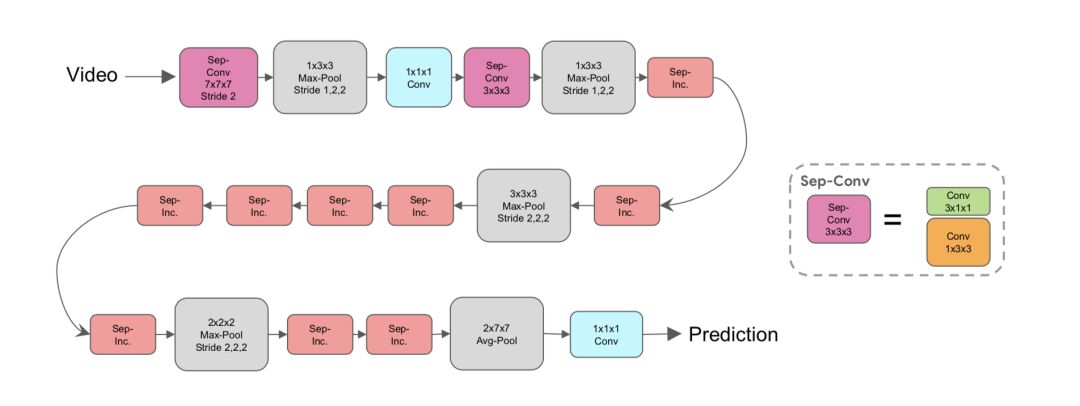
S3D
参数少了,不容易过拟合,这里就是文中说的标准S3D;还可更轻量级的版本 Fast S3D, 按照top-heavy设计,把前面几个模块换成2D卷积即可。
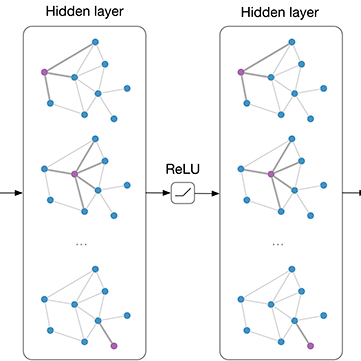
3. 在每个 3x1x1 卷积后加入了 Self-attention 模块 (即文中的 spatio-temporal feature gating),进一步提升性能:
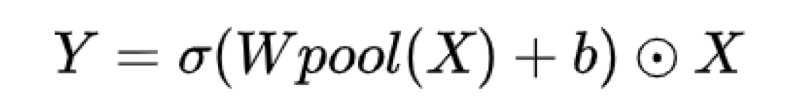
这里只是个普通的时空attention模块,将feature map中所有channels进行平均池化,然后进行线行映射和非线性激活,来产生时空attention map,最后权值叠加回去原feature map
I3D-GCN[2], ECCV2018
先来看看算法的主框架图:
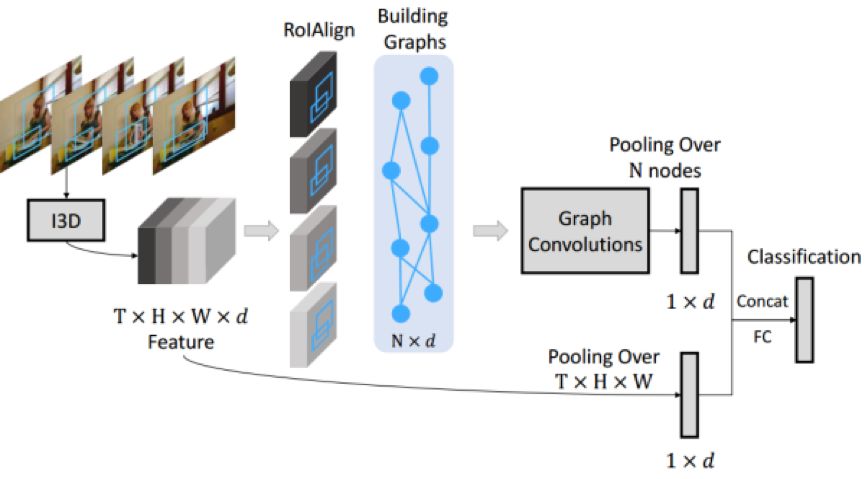
I3D-GCN主框架图
主要流程为:
1. 对均匀下采样后的T 帧作为输入,经过I3D,得到 TxHxWxd 的 deep feature,然后分两个branches
2. 第一个branch进行RPN来提取N个候选区域,然后进行ROIAlign来得到 Nxd 特征;接着构造相似度图和双向时空图,然后对两种图各进行图卷积操作,再叠加得 Nxd 特征;最后对N个物体特征进行均值池化,得到 1xd 特征
3. 第二个branch直接对时空deep feature进行均值池化,得到 1xd 特征
文中的主要创新点是构造两个图来描述N个物体特征间关系:
A、Similarity Graph
假定一帧中有 N 个物体,每个物体特征Xi是d维特征向量,故任何两个物体特征间的相关性可以表达为:
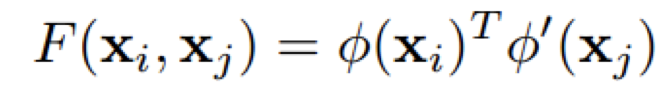
其中Φ(x)=wx和Φ’是=w’x对于原特征的不同变换,其变换矩阵的维度为 d x d 。
通过学习变换矩阵的参数,作者希望学习到同一个物体不同状态的相关性,以及不同物体间的关系。
B、Spatial-Temporal Graph
为了让图能学到时空特性,即不同物体在顺序连续帧间的空间关系,作者对 帧t 和 帧t+1 里的所有物体区域计算IoU,单向进行映射 t->t+1,然后把 IoU 的值赋给节点间的edge,最后对同一个节点的所有edge进行归一化。上述就形成了 spatial-temporal forward graph;为了丰富结构化信息,按照同样的方式对 帧t 和 帧t-1 也进行映射,形成 backward graph。
实验结果:
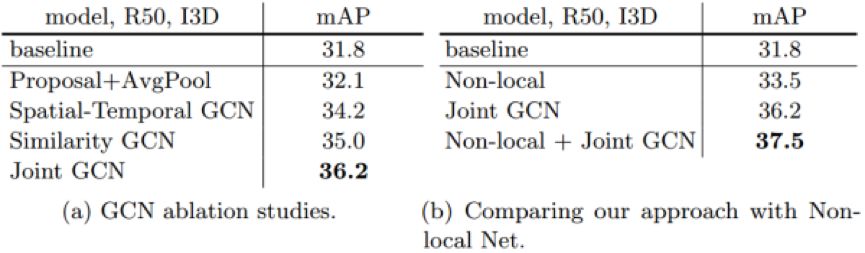
Charades数据集上实验结果
可见 Non-local + I3D + GCN 比 I3D baseline性能提升很大,虽然运算量增加了很多~
SlowFastNet [3]
FAIR Kaiming 指导的工作,超参对比实验非常丰富,集群GPU多就是猛,高校怎么玩得过?
文章致力于探索如何构造 轻量化的不同时间分辨率双流网络,使其通用于快速及慢速动作。正如之前文章《浅谈动作识别TSN, TRN, ECO》最后探讨的问题1,部分动作特别慢 (比如摇手转头) ,而另外一部分动作特别快 (比如 jumping) ,如果都用同一个时间分辨率的输入,同一套时空卷积,出来结果泛化能力就有待提高。
OK,接着来看看文中的网络框架:
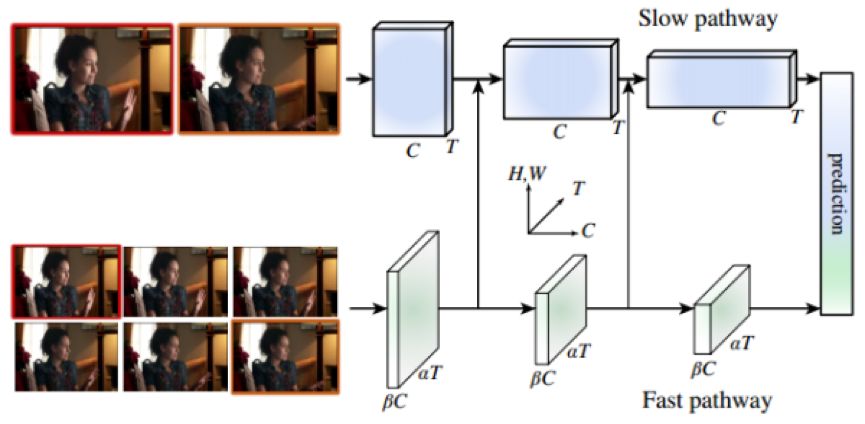
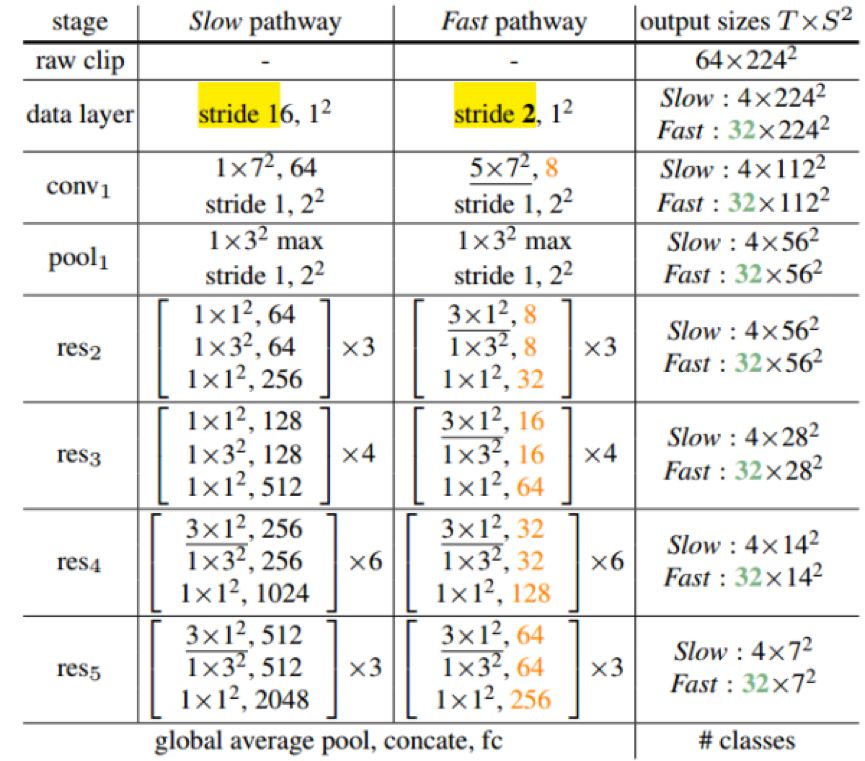
SlowFast Net 架构图
网络很简单,同模态同空间分辨率不同时间分辨率的双流网络,SlowPathway 主要提取类别的颜色,纹理,光照变化相关的语义特征,而 FastPathway 则提取 Fast motion 特征。为了使网络轻量且特征维度一致,FastPathway网络很窄,则同一个stage的channel数仅为SlowPathway的八分之一。
双流交互
由于 FastPathway 和 SlowPathway 在相同stage出来的特征维度不一致,文中探讨了三种 lateral connection 特征尺寸匹配方式:
假定 feature shape 在 SlowPathway 中为{T,S2,C},在 FastPathway 中为{αT,S2,βC}
1.Time-to-channel:直接reshape and transpose{αT,S2,βC}成{T,S2,αβC}
2. Time-stride-sampling:直接对FastPathway的时间维度下采样,成{T,S2,βC}
3. Time-stride convolution:对FastPathway进行5x1x1的3D卷积,成{T,S2,2βC}
最后通过实验发现,Time-stride convolution 的特征尺寸匹配效果最好,特征融合使用concat,且双向与单向 (只由FastPathway连向SlowPathway) 连接的效果差不多。
实验结果:
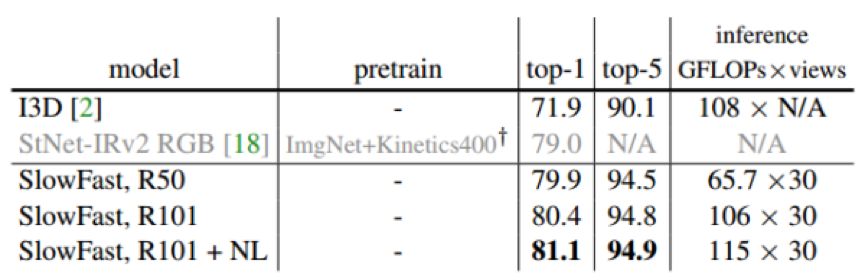
Kinectics-600 实验结果
这是什么水平?在时间复杂度与 轻量级的S3D-G 相当的情况下,性能比其还要好几个点~~
Long-Term Feature Banks(LFB) [4]
同为FAIR Kaiming 指导的工作,文章的开头很有趣,给出了下面一个 only 4 seconds 的 video clip,让我们猜视频里的人在干什么?

很明显,这不好回答,因为 short-term clip 不好表达整个video的内容,这也是当前基于3D卷积的时空网络遇到的瓶颈问题:GPU memory有限,即使在sparse sampling的前提下(当然你也可以极限去sampling,不过会丢失太多时间信息)
要回答上图的问题,我们需要更长的视频片段,如下图:

可以知道这是个音乐会,人们都在听音乐。故怎么实现 Long-term Feature Bank呢?
来一睹算法框架图:
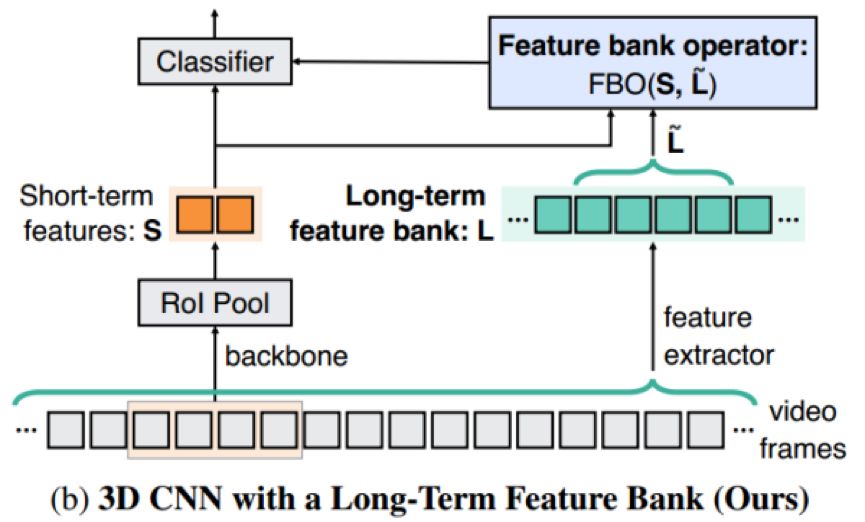
算法流程如下:
1. 首先将long-term视频分成short-term clips,对每个clip都进行3D CNN特征提取,然后RPN物体区域ROIAlign特征提取,每个clip就对应各自的 Short-term features S;接着将当前clip前后局部时间域里的多个short-term S串联起来,组成 long-term feature bank
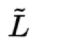
2. 为了找到 short-term 与 long-term 间的关系,将当前clip的 short-term S与 long-term 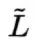
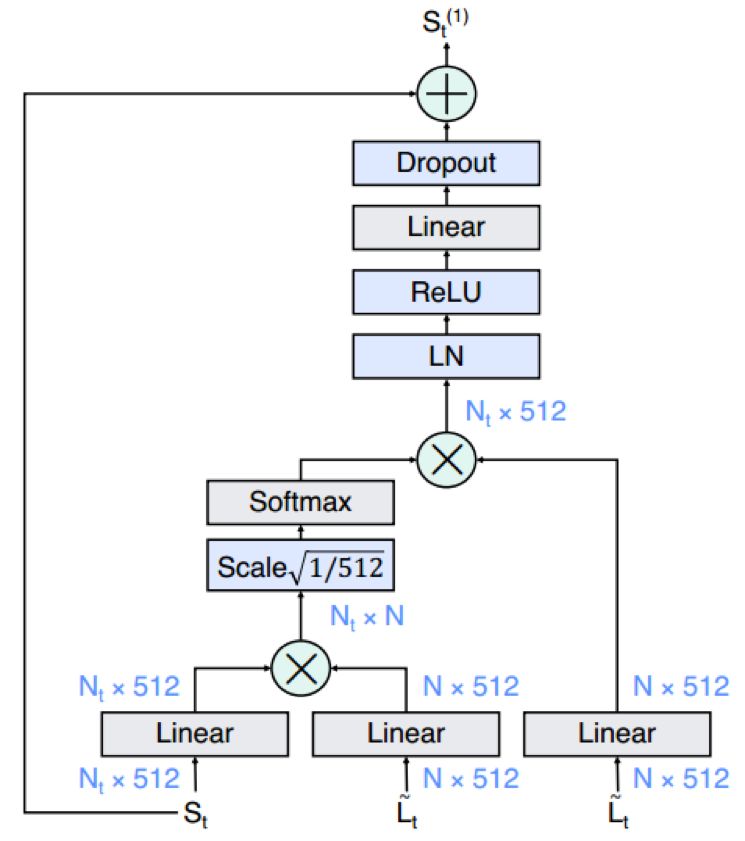
Modified non-local in FBO
3. 最后将FBO输出的特征与当前clip short-term S进行 concat,送进分类器
实验结果:
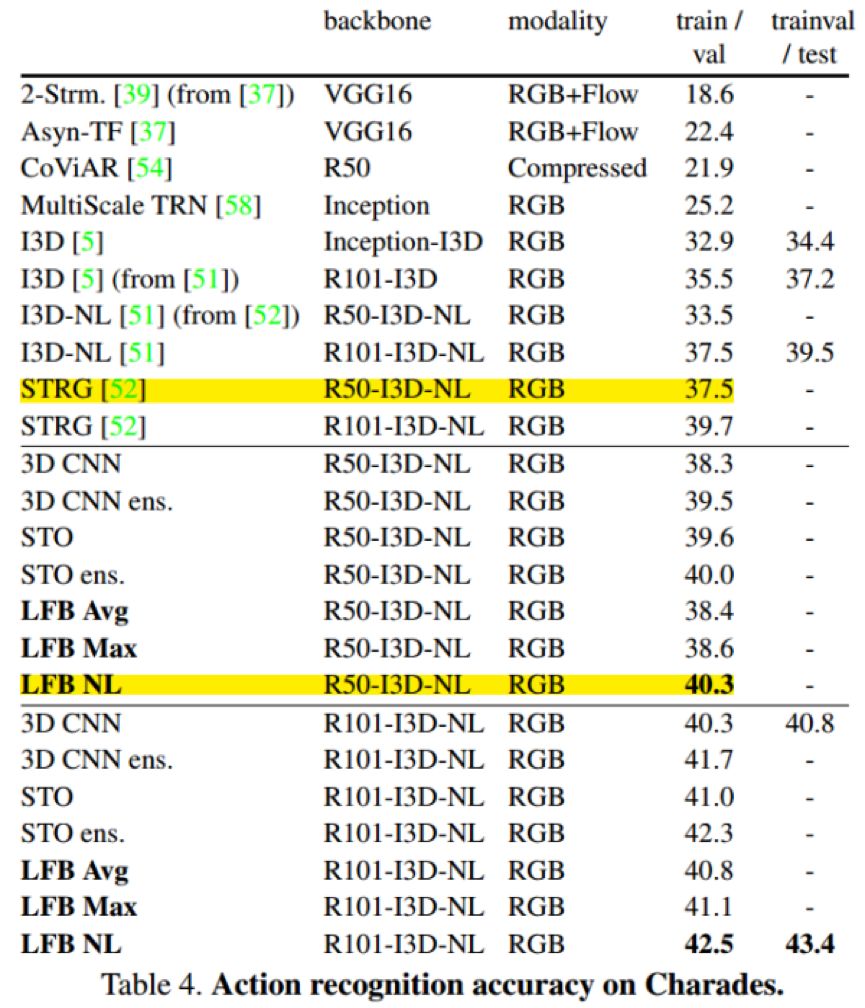
如上图标黄线Highlight所示,在相同backbone情况下,LFB 性能比 I3D-GCN 要高3个点左右~~
总结与展望:
上面几个文章从不同角度来探索视频理解识别存在的一些发展方向,还是很有参考意义。虽然像GCN中的关系描述很粗糙,且整个网络运算量巨大;SlowFast Net中的时间分辨率双流过于人为粗糙,能真正理解不同帧率不同快慢的动作,自适应调整网络就更好了;LFB中找短时长时的关系就更加粗暴了,也许你已经想到了更好的方法去整合 long-short term, fast & slow~~
Reference:
[1] Saining Xie, Rethinking Spatiotemporal Feature Learning: Speed-Accuracy Trade-offs in Video Classification, ECCV2018
[2] Xiaolong Wang, Videos as Space-Time Region Graphs,ECCV2018
[3] FAIR, SlowFast Networks for Video Recognition,2018
[4] FAIR, Long-Term Feature Banks for Detailed Video Understanding,2018
*延伸阅读
IBM发布百万级“人脸多样性”数据集,希望战胜人脸技术偏见
算法偏见就怪数据集?MIT纠偏算法自动识别「弱势群体」
TorchSeg:基于pytorch的语义分割算法开源了
每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击左下角“阅读原文”立刻申请入群~

觉得有用麻烦给个好看啦~