【论文推荐】最新八篇知识图谱相关论文—全卷积网络、结构化知识图谱、关系结构表示、情感分析、可解释和组合关系学习
【导读】专知内容组既昨天推出八篇知识图谱(Knowledge Graph)相关论文,
今天为大家推出八篇知识图谱(Knowledge Graph)相关论文,欢迎查看!
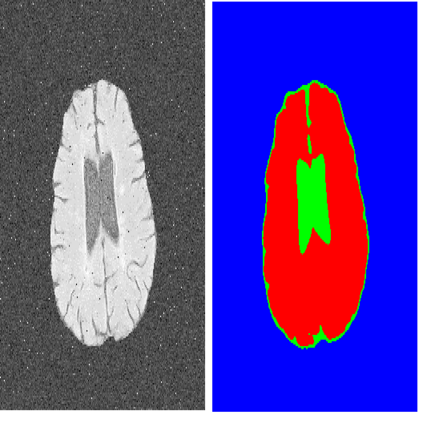
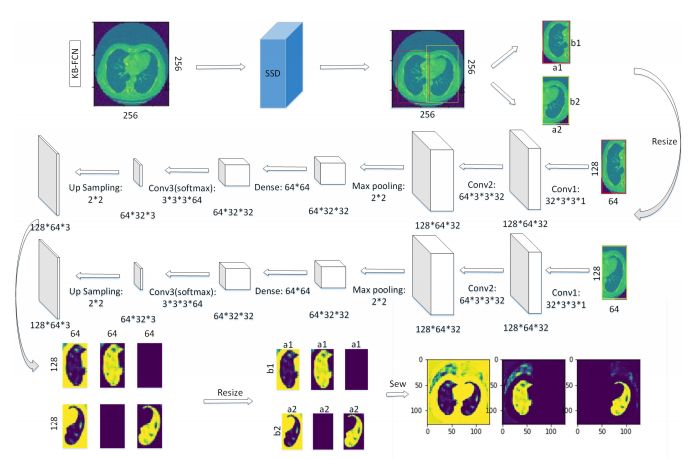
9.Knowledge-based Fully Convolutional Network and Its Application in Segmentation of Lung CT Images(基于知识的全卷积网络及其在肺部CT图像分割中的应用)
作者:Tao Yu,Yu Qiao,Huan Long
机构:Shanghai Jiao Tong University
摘要:A variety of deep neural networks have been applied in medical image segmentation and achieve good performance. Unlike natural images, medical images of the same imaging modality are characterized by the same pattern, which indicates that same normal organs or tissues locate at similar positions in the images. Thus, in this paper we try to incorporate the prior knowledge of medical images into the structure of neural networks such that the prior knowledge can be utilized for accurate segmentation. Based on this idea, we propose a novel deep network called knowledge-based fully convolutional network (KFCN) for medical image segmentation. The segmentation function and corresponding error is analyzed. We show the existence of an asymptotically stable region for KFCN which traditional FCN doesn't possess. Experiments validate our knowledge assumption about the incorporation of prior knowledge into the convolution kernels of KFCN and show that KFCN can achieve a reasonable segmentation and a satisfactory accuracy.
期刊:arXiv, 2018年5月22日
网址:
http://www.zhuanzhi.ai/document/9ad295af7a4e3a5f3fcfc8ea8147e5d7
10.Multi-Label Zero-Shot Learning with Structured Knowledge Graphs
(基于结构化知识图谱的多标签 Zero-Shot 学习)
作者:Chung-Wei Lee,Wei Fang,Chih-Kuan Yeh,Yu-Chiang Frank Wang
CVPR 2018
机构:Carnegie Mellon University,National Taiwan University
摘要:In this paper, we propose a novel deep learning architecture for multi-label zero-shot learning (ML-ZSL), which is able to predict multiple unseen class labels for each input instance. Inspired by the way humans utilize semantic knowledge between objects of interests, we propose a framework that incorporates knowledge graphs for describing the relationships between multiple labels. Our model learns an information propagation mechanism from the semantic label space, which can be applied to model the interdependencies between seen and unseen class labels. With such investigation of structured knowledge graphs for visual reasoning, we show that our model can be applied for solving multi-label classification and ML-ZSL tasks. Compared to state-of-the-art approaches, comparable or improved performances can be achieved by our method.
期刊:arXiv, 2018年5月26日
网址:
http://www.zhuanzhi.ai/document/55eb98b87d203024bcf0feac9beba5a2
11.From Knowledge Graph Embedding to Ontology Embedding: Region Based Representations of Relational Structures(从知识图谱嵌入到本体嵌入:基于区域的关系结构表示)
作者:Víctor Gutiérrez-Basulto,Steven Schockaert
机构:Cardiff University
摘要:Recent years have witnessed the enormous success of low-dimensional vector space representations of knowledge graphs to predict missing facts or find erroneous ones. Currently, however, it is not yet well-understood how ontological knowledge, e.g. given as a set of (existential) rules, can be embedded in a principled way. To address this shortcoming, in this paper we introduce a framework based on convex regions, which can faithfully incorporate ontological knowledge into the vector space embedding. Our technical contribution is two-fold. First, we show that some of the most popular existing embedding approaches are not capable of modelling even very simple types of rules. Second, we show that our framework can represent ontologies that are expressed using so-called quasi-chained existential rules in an exact way, such that any set of facts which is induced using that vector space embedding is logically consistent and deductively closed with respect to the input ontology.
期刊:arXiv, 2018年5月26日
网址:
http://www.zhuanzhi.ai/document/31ccad7c909af8e5d97758cacc10c2ca
12.Incorporating Literals into Knowledge Graph Embeddings(将文字融入知识图谱嵌入)
作者:Agustinus Kristiadi,Mohammad Asif Khan,Denis Lukovnikov,Jens Lehmann,Asja Fischer
机构:University of Bonn
摘要:Knowledge graphs, on top of entities and their relationships, contain other important elements: literals. Literals encode interesting properties (e.g. the height) of entities that are not captured by links between entities alone. Most of the existing work on embedding (or latent feature) based knowledge graph analysis focuses mainly on the relations between entities. In this work, we study the effect of incorporating literal information into existing link prediction methods. Our approach, which we name LiteralE, is an extension that can be plugged into existing latent feature methods. LiteralE merges entity embeddings with their literal information using a learnable, parametrized function, such as a simple linear or nonlinear transformation, or a multilayer neural network. We extend several popular embedding models based on LiteralE and evaluate their performance on the task of link prediction. Despite its simplicity, LiteralE proves to be an effective way to incorporate literal information into existing embedding based methods, improving their performance on different standard datasets, which we augmented with their literals and provide as testbed for further research.
期刊:arXiv, 2018年5月25日
网址:
http://www.zhuanzhi.ai/document/853194e96e265b677ac3cba1c012c4f3
13.Knowledge-enriched Two-layered Attention Network for Sentiment Analysis(知识丰富的二层注意力网络的情感分析)
作者:Abhishek Kumar,Daisuke Kawahara,Sadao Kurohashi
Accepted to NAACL 2018
机构:Kyoto University
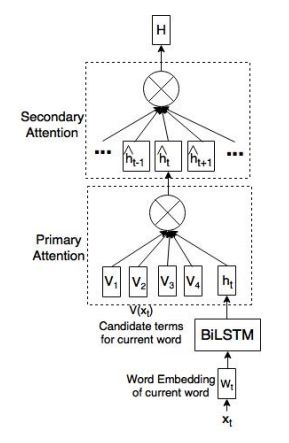
摘要:We propose a novel two-layered attention network based on Bidirectional Long Short-Term Memory for sentiment analysis. The novel two-layered attention network takes advantage of the external knowledge bases to improve the sentiment prediction. It uses the Knowledge Graph Embedding generated using the WordNet. We build our model by combining the two-layered attention network with the supervised model based on Support Vector Regression using a Multilayer Perceptron network for sentiment analysis. We evaluate our model on the benchmark dataset of SemEval 2017 Task 5. Experimental results show that the proposed model surpasses the top system of SemEval 2017 Task 5. The model performs significantly better by improving the state-of-the-art system at SemEval 2017 Task 5 by 1.7 and 3.7 points for sub-tracks 1 and 2 respectively.
期刊:arXiv, 2018年5月25日
网址:
http://www.zhuanzhi.ai/document/ab6bb0e4ef59fe1139d11fff1308567c
14.Interpretable and Compositional Relation Learning by Joint Training with an Autoencoder(用自编码器进行联合训练的可解释和组合关系学习)
作者:Ryo Takahashi,Ran Tian,Kentaro Inui
Accepted for publication in the ACL 2018
机构:Tohoku University
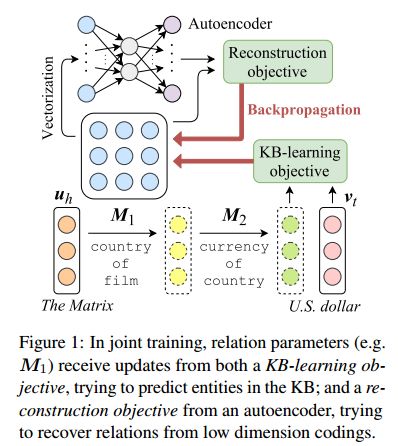
摘要:Embedding models for entities and relations are extremely useful for recovering missing facts in a knowledge base. Intuitively, a relation can be modeled by a matrix mapping entity vectors. However, relations reside on low dimension sub-manifolds in the parameter space of arbitrary matrices---for one reason, composition of two relations $\boldsymbol{M}_1,\boldsymbol{M}_2$ may match a third $\boldsymbol{M}_3$ (e.g. composition of relations currency_of_country and country_of_film usually matches currency_of_film_budget), which imposes compositional constraints to be satisfied by the parameters (i.e. $\boldsymbol{M}_1\cdot \boldsymbol{M}_2\approx \boldsymbol{M}_3$). In this paper we investigate a dimension reduction technique by training relations jointly with an autoencoder, which is expected to better capture compositional constraints. We achieve state-of-the-art on Knowledge Base Completion tasks with strongly improved Mean Rank, and show that joint training with an autoencoder leads to interpretable sparse codings of relations, helps discovering compositional constraints and benefits from compositional training. Our source code is released at github.com/tianran/glimvec.
期刊:arXiv, 2018年5月24日
网址:
http://www.zhuanzhi.ai/document/d38e99a4cb24e0f7d66c29cb30637db2
15.OK Google, What Is Your Ontology? Or: Exploring Freebase Classification to Understand Google's Knowledge Graph(谷歌,你的本体是什么?或者:探索freebase 分类来理解谷歌的知识图谱)
作者:Niel Chah
机构:University of Toronto
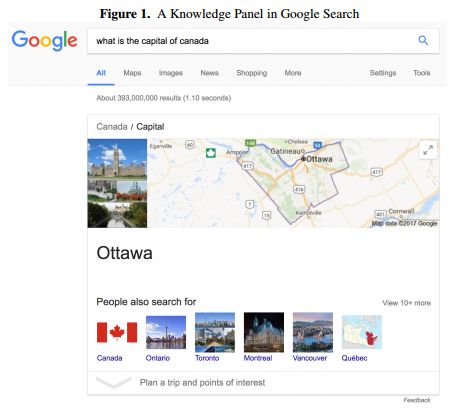
摘要:This paper reconstructs the Freebase data dumps to understand the underlying ontology behind Google's semantic search feature. The Freebase knowledge base was a major Semantic Web and linked data technology that was acquired by Google in 2010 to support the Google Knowledge Graph, the backend for Google search results that include structured answers to queries instead of a series of links to external resources. After its shutdown in 2016, Freebase is contained in a data dump of 1.9 billion Resource Description Format (RDF) triples. A recomposition of the Freebase ontology will be analyzed in relation to concepts and insights from the literature on classification by Bowker and Star. This paper will explore how the Freebase ontology is shaped by many of the forces that also shape classification systems through a deep dive into the ontology and a small correlational study. These findings will provide a glimpse into the proprietary blackbox Knowledge Graph and what is meant by Google's mission to "organize the world's information and make it universally accessible and useful".
期刊:arXiv, 2018年5月22日
网址:
http://www.zhuanzhi.ai/document/4895f1d8a234293192541e90d8004594
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取。欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知