机器之心 & ArXiv Weekly Radiostation
本周论文主要包括微软亚研团队提出一种升级版SwinTransformer;字节跳动、约翰霍普金斯大学等机构组成的联合团队,提出了适用于视觉任务的大规模预训练方法 iBOT,该方法在十几类任务和数据集上刷新了 SOTA 结果,在一些指标上甚至超过了 MAE 。
N-grammer: Augmenting Transformers with latent n-grams
Swin Transformer V2: Scaling Up Capacity and Resolution
IBOT : IMAGE BERT PRE-TRAINING WITH ONLINE TOKENIZER
Facebook AI’s WMT21 News Translation Task Submission
Mastering Atari Games with Limited Data
A Survey of Visual Transformers
Exploration in Deep Reinforcement Learning: A Comprehensive Survey
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:N-grammer: Augmenting Transformers with latent n-grams
摘要:
近日,一篇匿名提交给自然语言处理顶会 ACL 的论文《 N-grammer: Augmenting Transformers with latent n-grams 》中,研究者受到统计语言建模的启发,通过从文本序列的离散潜在表示构建 n-gram 来增强模型,进而对 Transformer 架构进行了一个简单而有效的修改,称为 N-grammer。
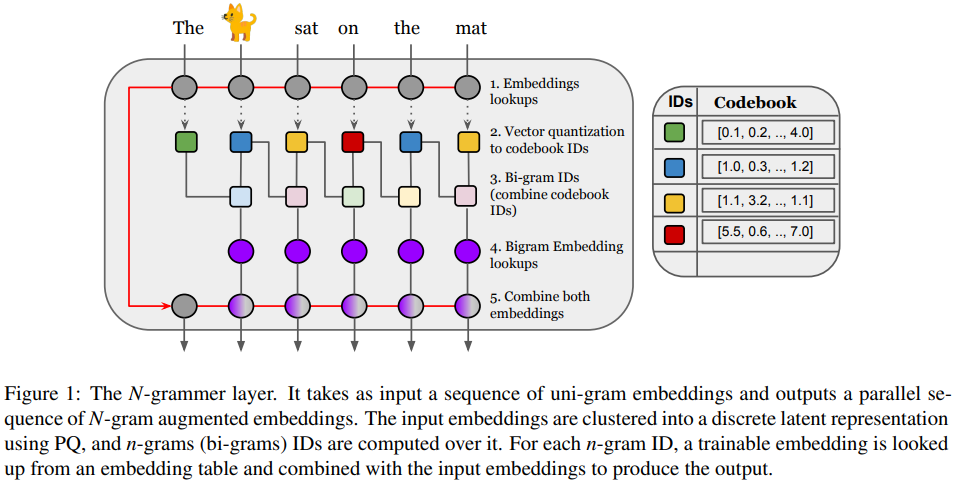
具体地,N-grammer 层通过在训练期间将潜在 n-gram 表示合并到模型中来提高语言模型的效率。由于 N-grammer 层仅在训练和推理期间涉及稀疏操作,研究者发现具有潜在 N-grammer 层的 Transformer 模型可以匹配更大的 Transformer,同时推理速度明显更快。在 C4 数据集上对语言建模的 N-grammer 进行评估表明,本文提出的方法优于 Transformer 和 Primer 等基准。
在网络高层次上,该研究引入了一个简单的层,该层基于潜在 n-gram 用更多的内存来增强 Transformer 架构。一般来说,N-grammer 层对于任意 N-gram 来说已经足够了,该研究仅限于使用 bi-gram,以后将会研究高阶 n-gram。这个简单的层由以下几个核心操作组成:
给定文本的 uni-gram 嵌入序列,通过 PQ (Product Quantization)推导出离散潜在表示序列;
推导潜在序列 bi-gram 表示;
通过哈希到 bi-gram 词汇表中查找可训练的 bi-gram 嵌入;
将 bi-gram 嵌入与输入 uni-gram 嵌入相结合。
![]()
![]()
推荐:
研究者用潜在 n-gram 来增强 Transformer。
论文 2:Swin Transformer V2: Scaling Up Capacity and Resolution
摘要:
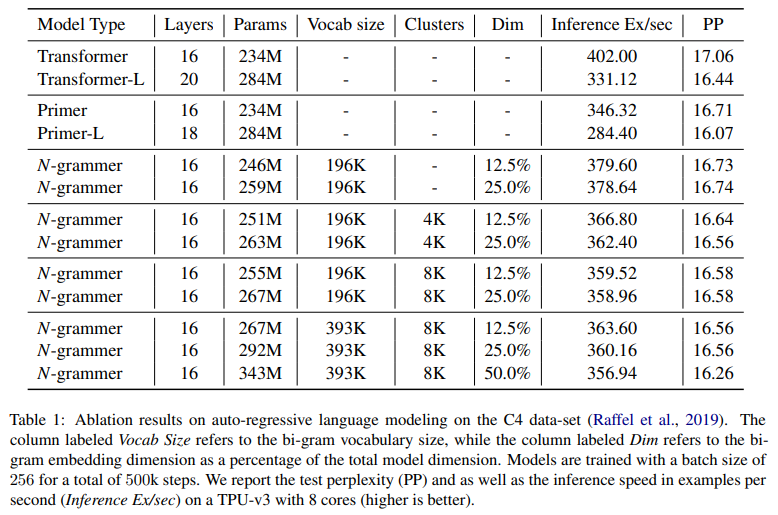
微软亚研团队又提出一种升级版SwinTransformer V2。具体而言,该研究提出了将 Swin Transformer扩展到 30 亿个参数并使其能够训练分辨率高达 1,536×1,536 的图像的技术。通过扩大容量和分辨率,Swin Transformer V2在四个具有代表性的基准上刷新纪录:在ImageNet-V2 图像分类任务上 top-1 准确率为 84.0%,COCO 目标检测任务为63.1 box 与54.4 max mAP,ADE20K 语义分割为 59.9 mIoU,Kinetics-400 视频动作分类的 top-1 准确率为 86.8%。
![]()
(图注)SwinV1-H与SwinV2-H的训练对比。
推荐:
微软亚研团队又提出一种升级版SwinTransformer V2。
论文 3:IBOT : IMAGE BERT PRE-TRAINING WITH ONLINE TOKENIZER
摘要:
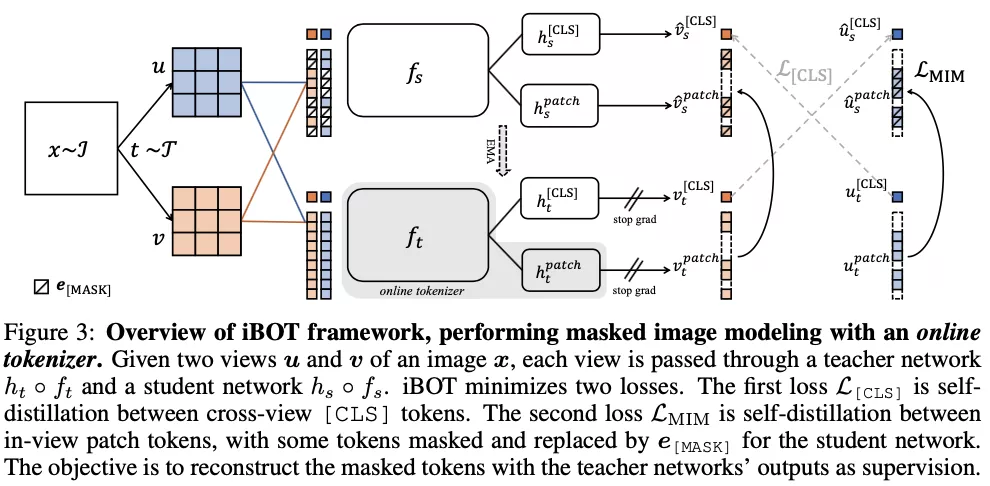
字节跳动、约翰霍普金斯大学等机构组成的联合团队,在一篇最新的论文中,他们提出了适用于视觉任务的大规模预训练方法 iBOT,通过对图像使用在线 tokenizer 进行 BERT 式预训练让 CV 模型获得通用广泛的特征表达能力。该方法在十几类任务和数据集上刷新了 SOTA 结果,在一些指标上甚至超过了 MAE。
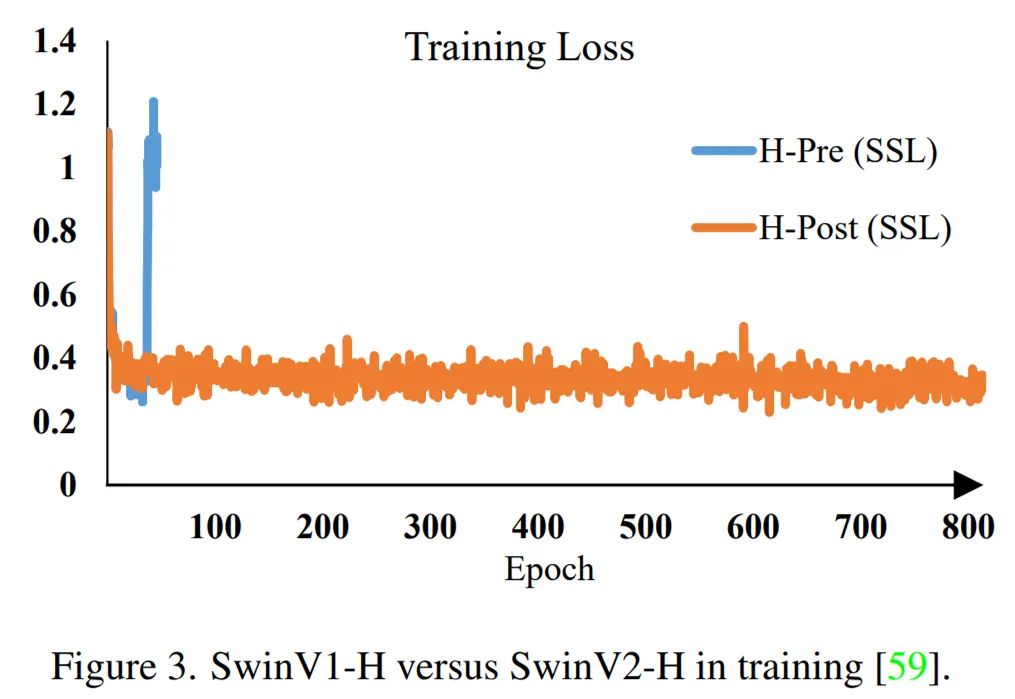
在该工作中,研究者主要探索了这种在 NLP 中主流的 Masked Modeling 是否能应用于大规模 Vision Transformer 的预训练。作者给出了肯定的回答,并认为问题关键在于 visual tokenizer 的设计。不同于 NLP 中 tokenization 通过离线的词频分析即可将语料编码为含高语义的分词,图像 patch 是连续分布的且存在大量冗余的底层细节信息。而作者认为一个能够提取图像 patch 中高层语义的 tokenizer 可帮助模型避免学习到冗余的这些细节信息。作者认为视觉的 tokenizer 应该具备两个属性:(a)具备完整表征连续图像内容的能力;(b) 像 NLP 中的 tokenizer 一样具备高层语义。
如何才能设计出一个 tokenizer,使之同时具备以上的属性呢?作者首先将经过 mask 过的图片序列输入 Transformer 之后进行预测的过程建模为知识蒸馏的过程:
![]()
iBOT 同时优化上述两项损失函数。其中,在 [CLS] 标签上的自蒸馏保证了在线 tokenizer 学习到高语义特征,并将该语义迁移到 MIM 的优化过程中;而在 patch 标签上的自蒸馏则将在线 tokenizer 表征的 patch 连续分布作为目标监督 masked patch 的复原。该方法在保证模型学习到高语义特征的同时,通过 MIM 显式建模了图片的内部结构。同时,在线 tokenizer 与 MIM 目标可以一起端到端地学习,无需额外的 tokenizer 训练阶段。
![]()
推荐:
字节跳动 iBOT 刷新十几项 SOTA,部分指标超 MAE。
论文 4:Facebook AI’s WMT21 News Translation Task Submission
摘要:
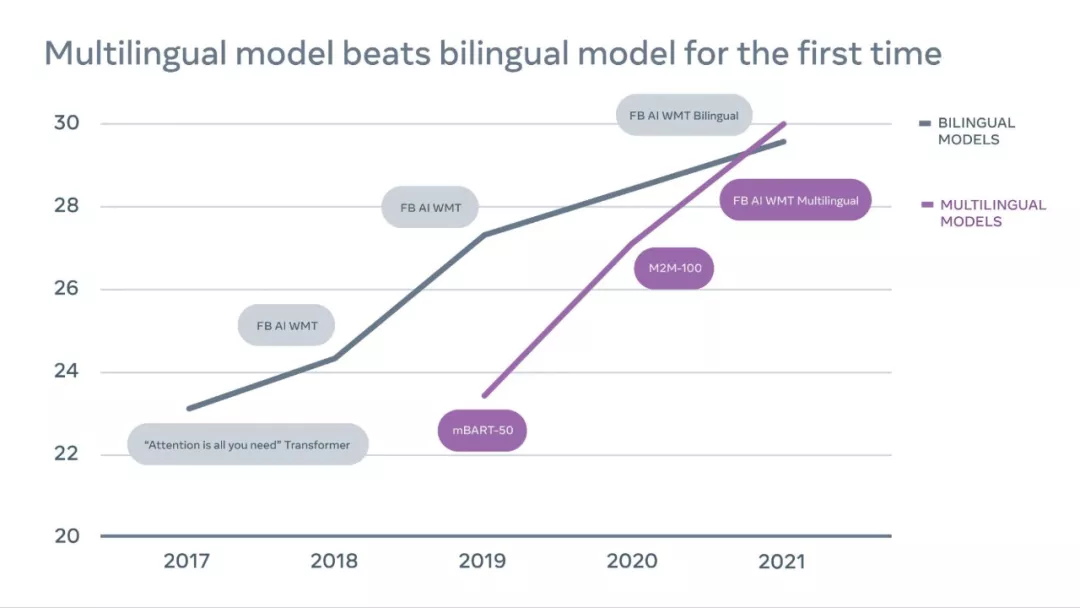
为了构建通用翻译器,来自 Meta 的研究者认为 MT 领域应该从双语模型转向多语言翻译(Multilingual translation)——多语言模型即一个模型可以同时翻译许多语言对,包括对低资源语言对(例如,冰岛语到英语的翻译)和高资源语言对(例如,英语到德语的翻译)的翻译。
Meta 的研究取得了突破性的进展:首次单一的多语言模型在 14 个语言对中有 10 个超过了经过特别训练的最好的双语模型,赢得了 WMT(一个著名的 MT 比赛)比赛。该单一多语言模型为低资源和高资源语言提供了最佳翻译,表明多语言方法确实是 MT 的未来。
这项研究建立在先前研究之上,提高了低资源语言的翻译质量。然而,当添加具有各种资源的语言时,随着更多语言的添加,一种模型将变得不堪重负,因为每种语言都具有独特的语言属性、脚本和词汇。当高资源语言受益于大型多语言模型时,对低资源语言对来说有过拟合的风险。
![]()
上图为 2017-2021 年 WMT 竞赛时间表,表中展示了英语到德语翻译的性能质量随时间的进展,由结果可得多语言模型现已超过了双语模型。其中 En-De(English to German) 被公认为最具竞争力的翻译方向。
为了训练 WMT 2021 模型,研究者构建了两个多语言系统:任何语言到英语(any-to-English) 和英语到任何语言(English-to-any),方法采用并行数据挖掘技术。
在本次研究中,Meta 添加了包含来自所有八种语言的数亿个句子的大规模单语数据。并且过滤了可用的单语数据以减少噪声量,然后使用可用的最强多语言模型对它们进行回译。
推荐:
首次赢得 WMT 机器翻译大赛,Meta 证明单个多语言模型强于双语模型。
论文 5: Mastering Atari Games with Limited Data
摘要:
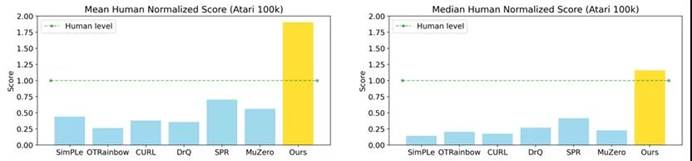
在一篇 NeurIPS 2021 论文中,清华大学交叉信息研究院高阳研究组提出了一种接受图像观测输入的高采样效率算法 EfficientZero,它基于之前 model-based 算法 MuZero。作者在基于图像观测的 model-based 强化学习算法上提出三点改进用于提升算法的采样效率并且保持高性能:时序一致性,预测阶段回报,修正目标价值。
在这三点改进下,EfficientZero 在 Atari 100k 的基准测试中实现了 190.4% 的平均人类性能和 116.0% 的中值性能,而这个任务只有两小时的真实游戏时间,这是第一次在如此有限数据下强化学习算法能够超越人类水平。此外,EfficientZero 的性能也接近 DQN 在 2 亿帧训练数据下的性能,然而所需要的数据降至约 500 分之一。
除了 Atari 游戏,研究还在机器控制的模拟环境 DMControl 100 基准下进行了部分环境的测试,性能同样是最佳,且与基于状态输入的 SAC 算法接近。实验表明,EfficientZero 的高采样效率和高性能可以更适配现实世界的环境,EfficientZero 或许能够使得强化学习算法在真实环境中有所突破。
![]()
EfficientZero 在 Atari 100k(2h 环境数据)基准下与其他算法结果对比
推荐:
交叉信息研究院高阳课题组在强化学习领域取得新突破。
论文 6:A Survey of Visual Transformers
摘要:
这段时间,计算机视觉圈有点热闹。先是何恺明等人用简单的掩蔽自编码器(MAE )证明了 Transformer 扩展到 CV 大模型的光明前景;紧接着,字节跳动又推出了部分指标超过 MAE 的新方法——iBOT ,将十几项视觉任务的 SOTA 又往前推了一步。这些进展给该领域的研究者带来了很大的鼓舞。
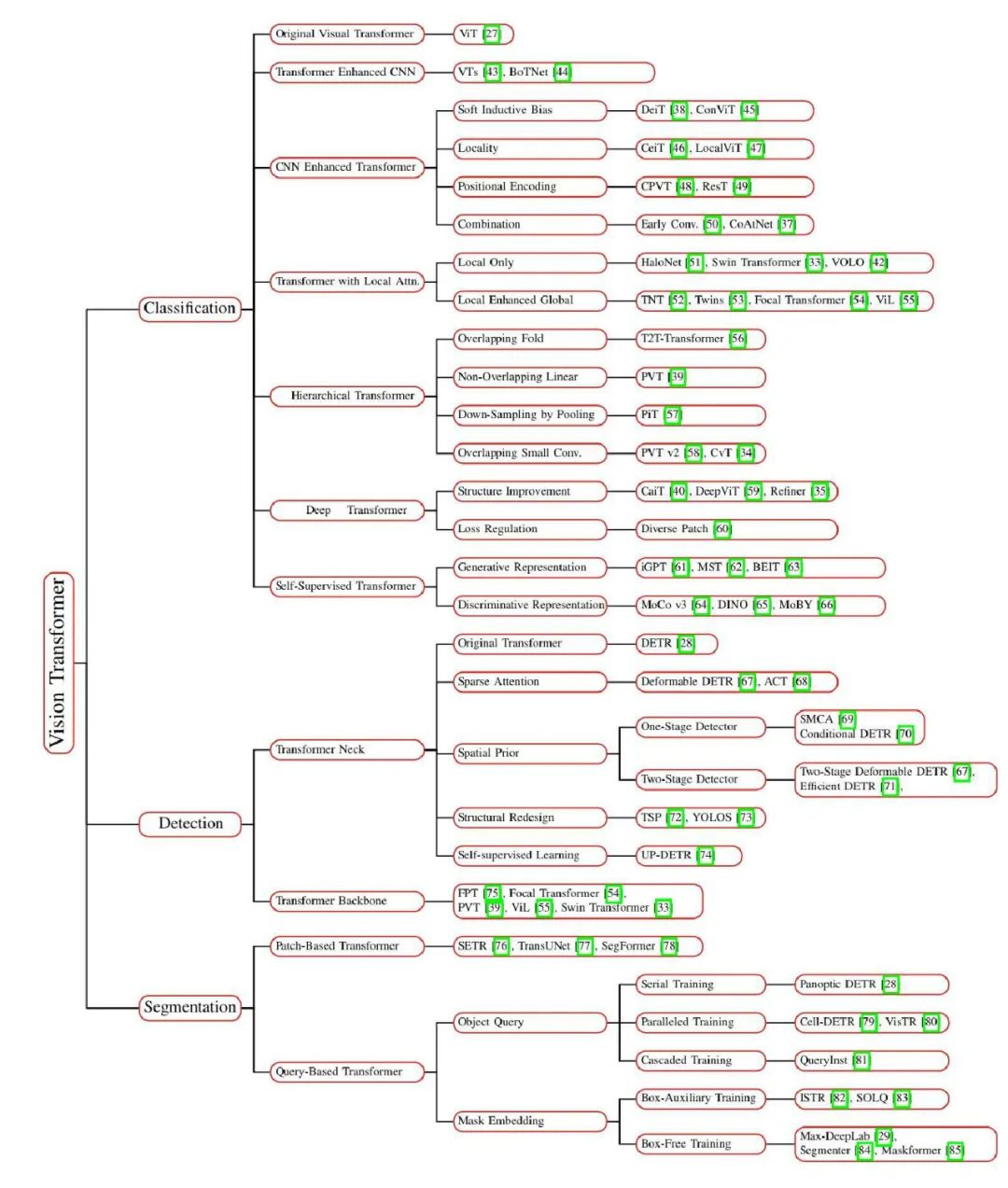
在这样一个节点,我们有必要梳理一下 CV 领域 Transformer 模型的现有进展,挖掘其中有价值的经验。因此,我们找到了中国科学院计算技术研究所等机构刚刚发布的一篇综述论文。在这篇论文中,Yang Liu 等几位研究者全面回顾了用于三个基本 CV 任务(分类、检测和分割)的 100 多个视觉 Transfomer,并讨论了有关视觉 Transformer 的一些关键问题以及有潜力的研究方向,是一份研究视觉 Transformer 的详尽资料。
如下图 2 所示,这篇综述将用于三个基本 CV 任务(分类、检测和分割)的 100 多种视觉 Transformer 方法按照任务、动机和结构特性分成了多个小组。当然,这些小组可能存在重叠。例如,其中一些进展可能不仅有助于增强图像分类骨干的表现,还能在检测、分割任务中取得不错的结果。
![]()
推荐:
这篇综述帮你梳理了 100 多个视觉 Transformer。
论文 7:Exploration in Deep Reinforcement Learning: A Comprehensive Survey
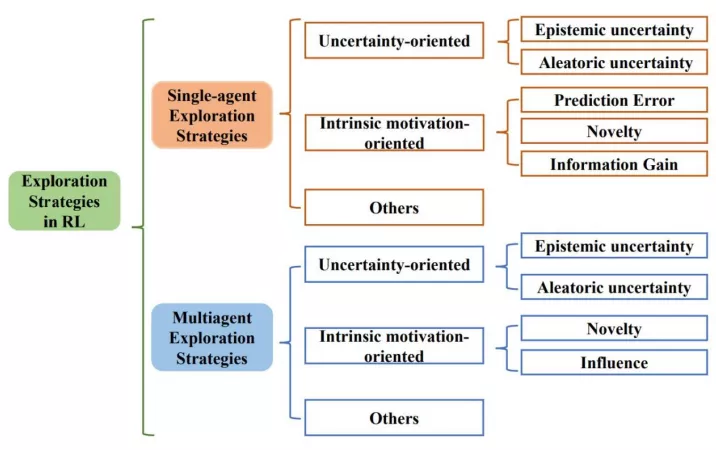
摘要:本文介绍深度强化学习领域第一篇系统性的综述文章。该综述共调研了将近 200 篇文献,涵盖了深度强化学习和多智能体深度强化学习两大领域近 100 种探索算法。总的来说,该综述的贡献主要可以总结为以下四:
三类探索算法。该综述首次提出基于方法性质的分类方法,根据方法性质把探索算法主要分为基于不确定性的探索、基于内在激励的探索和其他三大类,并从单智能体深度强化学习和多智能体深度强化学习两方面系统性地梳理了探索策略。
四大挑战。除了对探索算法的总结,综述的另一特点是对探索挑战的分析。综述中首先分析了探索过程中主要的挑战,同时,针对各类方法,综述中也详细分析了其解决各类挑战的能力。
三个典型 benchmark。该综述在三个典型的探索 benchmark 中提供了具有代表性的 DRL 探索方法的全面统一的性能比较。
五点开放问题。该综述分析了现在尚存的亟需解决和进一步提升的挑战,揭示了强化学习探索领域的未来研究方向。
![]()
上图展示了综述所遵循的分类方法。综述从单智能体深度强化学习算法中的探索策略、多智能体深度强化学习算法中的探索策略两大方向系统性地梳理了相关工作,并分别分成三个子类:方向不确定性的(Uncertainty-oriented)探索策略、面向内在激励的(Intrinsic motivation oriented)探索策略、以及其他策略。
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
1. SDCUP: Schema Dependency-Enhanced Curriculum Pre-Training for Table Semantic Parsing. (from Jian Sun)
2. RATE: Overcoming Noise and Sparsity of Textual Features in Real-Time Location Estimation. (from Yan Zhang)
3. DEEP: DEnoising Entity Pre-training for Neural Machine Translation. (from Kyunghyun Cho)
4. Keyphrase Extraction Using Neighborhood Knowledge Based on Word Embeddings. (from Mohammed J. Zaki)
5. Joint Unsupervised and Supervised Training for Multilingual ASR. (from Tara N. Sainath)
6. Textless Speech Emotion Conversion using Decomposed and Discrete Representations. (from Abdelrahman Mohamed, Emmanuel Dupoux)
7. Time Waits for No One! Analysis and Challenges of Temporal Misalignment. (from Noah A. Smith)
8. Transparent Human Evaluation for Image Captioning. (from Noah A. Smith)
9. User Response and Sentiment Prediction for Automatic Dialogue Evaluation. (from Yang Liu, Dilek Hakkani-Tur)
10. Multi-Grained Vision Language Pre-Training: Aligning Texts with Visual Concepts. (from Hang Li)
本周 10 篇 CV 精选论文是:
1. It's About Time: Analog Clock Reading in the Wild. (from Andrew Zisserman)
2. PyTorchVideo: A Deep Learning Library for Video Understanding. (from Jitendra Malik, Ross Girshick)
3. Visual Intelligence through Human Interaction. (from Li Fei-Fei)
4. Learning to Compose Visual Relations. (from Joshua B. Tenenbaum, Antonio Torralba)
5. Perceiving and Modeling Density is All You Need for Image Dehazing. (from Liang Chen, Zhiyong Lu)
6. Self-Supervised Predictive Convolutional Attentive Block for Anomaly Detection. (from Thomas B. Moeslund, Mubarak Shah)
7. UBnormal: New Benchmark for Supervised Open-Set Video Anomaly Detection. (from Mubarak Shah)
8. Restormer: Efficient Transformer for High-Resolution Image Restoration. (from Ming-Hsuan Yang)
9. Searching for TrioNet: Combining Convolution with Local and Global Self-Attention. (from Alan Yuille)
10. TransMix: Attend to Mix for Vision Transformers. (from Philip Torr, Alan Yuille)
本周 10 篇 ML 精选论文是:
1. Causal Effect Variational Autoencoder with Uniform Treatment. (from Kyunghyun Cho)
2. AnchorGAE: General Data Clustering via $O(n)$ Bipartite Graph Convolution. (from Xuelong Li)
3. HiRID-ICU-Benchmark -- A Comprehensive Machine Learning Benchmark on High-resolution ICU Data. (from Gunnar Rätsch)
4. LoMEF: A Framework to Produce Local Explanations for Global Model Time Series Forecasts. (from Rob J Hyndman)
5. Federated Learning for Internet of Things: Applications, Challenges, and Opportunities. (from Bhaskar Krishnamachari)
6. Aggressive Q-Learning with Ensembles: Achieving Both High Sample Efficiency and High Asymptotic Performance. (from Keith W. Ross)
7. Phase function estimation from a diffuse optical image via deep learning. (from Ge Wang)
8. Improving Transferability of Representations via Augmentation-Aware Self-Supervision. (from Honglak Lee)
9. Successor Feature Landmarks for Long-Horizon Goal-Conditioned Reinforcement Learning. (from Honglak Lee)
10. Variational Auto-Encoder Architectures that Excel at Causal Inference. (from Russell Greiner)
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com